The hardware you needed to run a 70B model in January 2025 is not the same as the hardware you need in March 2026. Not because the models changed — Llama 3 70B is still Llama 3 70B. The inference software got dramatically better, and every improvement compresses the hardware requirements for a given quality level.
Here are the 5 software milestones from 2025 that actually moved the needle on what you need to buy.
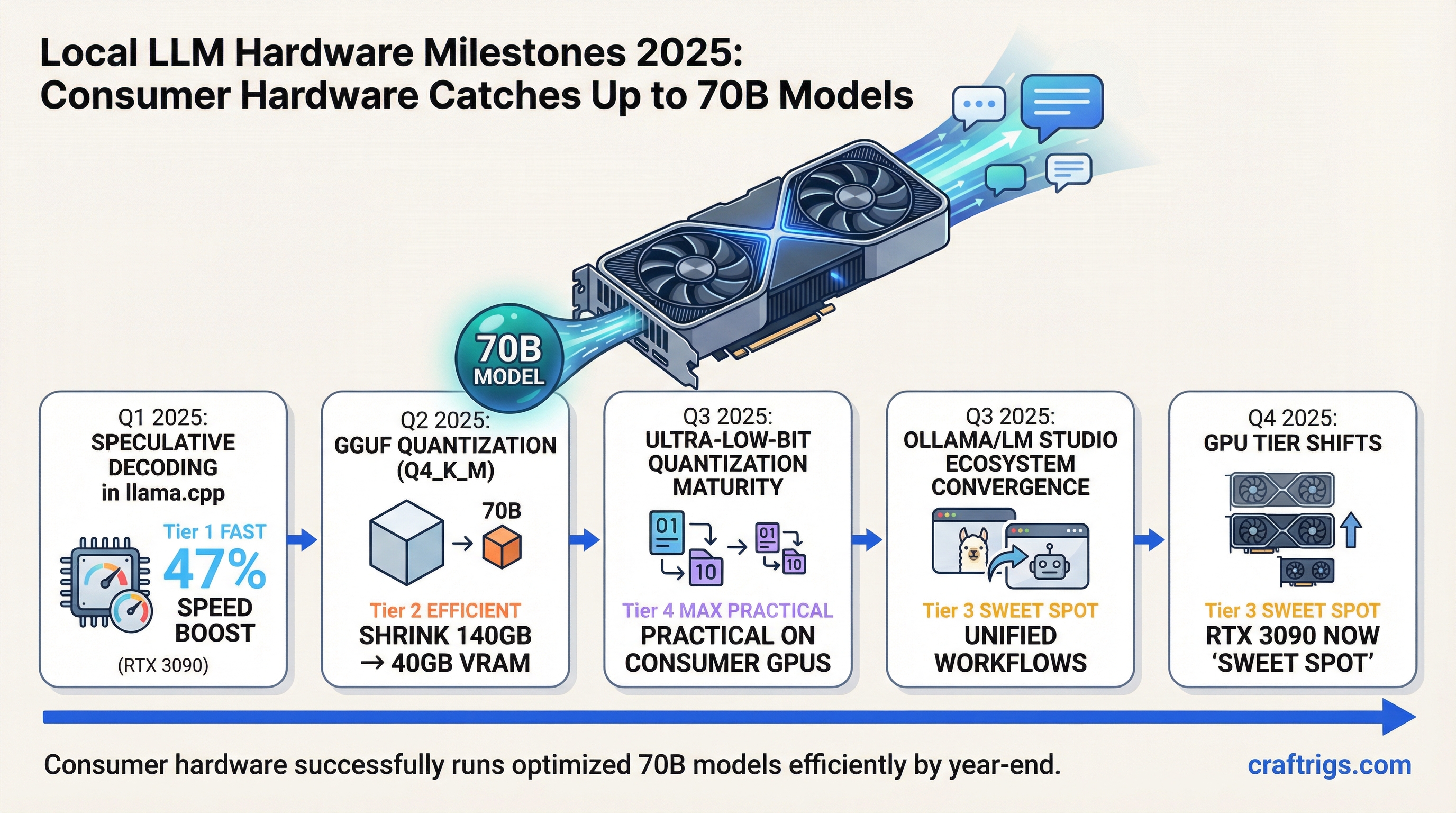
1. Speculative Decoding Landed in llama.cpp (November 2025)
Speculative decoding is one of those techniques that sounds theoretical until you see the benchmark numbers. The idea: use a small "draft" model (say, Llama 3.2 1B) to generate candidate tokens cheaply, then verify them in batches against your full model. Correct predictions get accepted in bulk; wrong ones get replaced. Net result: the full model does far less work per token.
When this landed in llama.cpp's server backend in November 2025, the documented speed improvements were 25-60% depending on the model pair and hardware.
Real numbers: Qwen 2.5 Coder 32B on an RTX 3090 went from 34.79 t/s to 51.31 t/s — a 47% improvement without touching the hardware. On a P40 (the eBay special), the same technique pushed from 10.54 t/s to 17.11 t/s. Hardware that was borderline usable before is now comfortably running 32B models.
This matters for anyone deciding between hardware tiers. An RTX 3090 with speculative decoding is closing the gap on an RTX 4090 without it for certain workloads.
2. Modern Quantization Shrank 70B VRAM Requirements by 70%
Llama 3 70B in FP32 requires approximately 140GB of memory. The same model at Q4_K_M quantization sits around 40GB and runs on a dual-GPU setup with two 24GB cards. Push further to Q2_K and you're under 25GB — one RTX 3090 can technically load it.
Note
Q4_K_M hits around 92% of full-precision perplexity in independent evaluations. For most conversational use cases, this quality difference is imperceptible in practice. Q8_0 gets to ~98% with roughly double the VRAM vs Q4.
The GGUF format formalized these quantization levels and made them portable across inference engines. By mid-2025, every major local LLM runner — Ollama, llama.cpp, LM Studio — supported the same GGUF quantization tiers. You can pull a Q4_K_M model from Hugging Face and it runs everywhere.
Ultra-low-bit quantization (1-bit, 1.58-bit, 2-bit) hit maturity in 2025 as well. Early results were disappointing. More recent implementations, particularly BitNet-style approaches, are matching full-precision perplexity on specific task benchmarks. Hardware requirements for running capable models dropped to cards that cost $150 on the used market.
3. Flash Attention Got Async Loading in llama.cpp (February 2025)
Flash Attention is an algorithmic optimization that computes attention more efficiently by breaking it into smaller blocks that fit in fast SRAM. It reduces memory bandwidth requirements and speeds up the attention computation itself. The problem: original Flash Attention implementations stalled the GPU during weight loading.
The February 2025 llama.cpp merge added async data loading for Flash Attention — simultaneous compute and data fetch, instead of sequential. On Ampere architecture (RTX 30 series) and newer, this translates to measurable throughput improvements at long context lengths, where attention is the bottleneck.
The practical effect: long-context use cases (feeding large documents into a 32K+ context window) got substantially faster on RTX 30/40/50 series cards without any hardware changes. If you already owned an RTX 3090 in January 2025, it got meaningfully better at document summarization by March 2025 through a software update.
4. MoE Models Became Viable on Consumer Hardware
Mixture-of-Experts (MoE) models like Mixtral 8x7B and DeepSeek V3 use a routing mechanism where only a subset of the model's parameters are active for any given token. The catch: you still need all the parameters loaded in memory, even the inactive ones.
Software advances in 2025 improved how inference engines handle MoE VRAM allocation. llama.cpp's DeepSeek-specific optimizations (merged in the V2/V3 support work) combined with Flash Attention for MoE layers made DeepSeek V3 — a 671B parameter model — run on consumer hardware via multi-GPU setups in a way that wasn't practical before.
More accessible: the DeepSeek R1 distilled models (7B, 14B, 32B, 70B) brought reasoning-capable models into ranges that fit on single consumer GPUs. A 14B reasoning model on a 16GB card is a very different proposition than "you need a $10,000 server to reason."
5. Ollama and LM Studio Absorbed the Complexity
This isn't a single milestone so much as the cumulative effect of 2025's Ollama and LM Studio releases. Two years ago, running a local LLM required command-line comfort, manual GGUF downloading, and understanding of GPU layers. Now it's download, install, pull model, run.
Tip
If you're benchmarking inference speed, use llama-bench rather than subjective feel in a chat UI. LM Studio and Ollama add latency overhead that obscures raw GPU performance. For hardware comparison purposes, llama.cpp direct with llama-bench gives you clean numbers.
The abstraction of GPU configuration (auto-detecting layers to offload based on available VRAM), automatic quantization selection, and one-command model management didn't change what hardware you need, but it changed who can run local LLMs. The addressable audience expanded dramatically, which matters for the ecosystem around hardware availability and community support.
The net effect of these five changes: what required a $3,000+ build in early 2025 now runs reasonably on a $700-800 build in March 2026. That math gets better every few months as llama.cpp and related projects continue improving. For the specific VRAM requirements driven by these quantization advances, our model-by-model VRAM breakdown maps every major model to the hardware it actually needs. And for a full picture of current GPU options, our GPU comparison guide covers every relevant card at every price point.
2025 Local LLM Hardware Timeline
timeline
title Local LLM Hardware Milestones 2025
Q1 2025 : RTX 5090 launch (32GB VRAM)
: Llama 3.3 70B consumer-runnable
Q2 2025 : Apple M4 Max ships (128GB unified)
: AMD RX 9070 XT release
Q3 2025 : Sub-10B models hit GPT-4 benchmarks
: Quantization hits Q2 quality
Q4 2025 : 70B models run on single consumer GPU
: Local inference costs near zero