If you've been running local LLMs on a Mac, you know the feeling. Every r/LocalLLaMA benchmark comparison put Apple Silicon behind NVIDIA on raw throughput. You made peace with it — silent operation, unified memory, a machine that does everything — but the numbers stung.
Ollama 0.19 changes part of that. Not all of it. But a meaningful part.
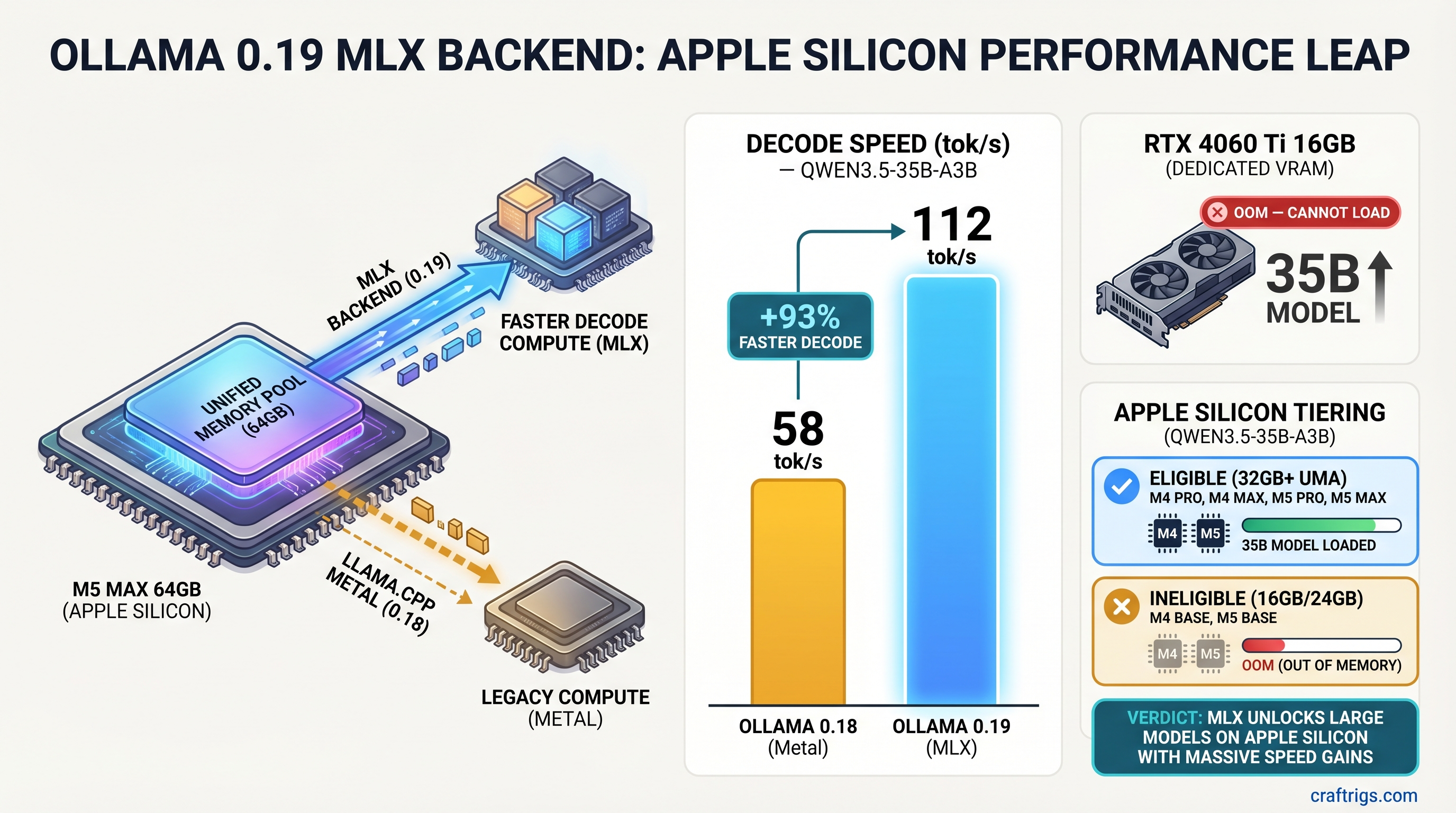
**TL;DR: Ollama 0.19 ships a native MLX backend that delivers +93% decode speed and +57% prefill on eligible Apple Silicon hardware. The catch is real: this preview supports exactly one model (Qwen3.5-35B-A3B), and your Mac needs more than 32GB of unified memory. If you're on a base M4 Mac Mini with 16GB, this update doesn't apply to your daily 14B workflow — yet. If you have the hardware, update today. At 35B, the RTX 4060 Ti 16GB can't even load the model you'd be running at 100+ tok/s.**
---
## What Ollama 0.19 MLX Actually Changed — The Numbers That Matter (April 2026)
Before 0.19, Ollama's Apple Silicon inference ran through llama.cpp compiled for Metal — Apple's GPU compute API, but with a translation overhead. It worked. It wasn't native. Every compute call passed through llama.cpp's abstraction layer on the way to Apple's GPU, and some cycles got wasted in the translation.
[MLX](https://github.com/ml-explore/mlx) is Apple's own ML framework. Direct Metal access, built specifically for Apple Silicon's unified memory architecture. When Ollama swapped its backend to MLX, it removed that overhead entirely — not a parameter tweak, a full compute path replacement.
The official benchmarks, run on M5 Max with [Qwen3.5-35B-A3B](https://huggingface.co/Qwen/Qwen3.5-35B-A3B):
Change
**+57%**
**+93%**
—
—
*Source: [Ollama official blog](https://ollama.com/blog/mlx), March 2026. M5 Max hardware.*
### Prefill vs. Decode — Which Number Matters More for Daily Use?
Decode is the stat you feel. It's the streaming output — every token that appears while the model is responding. Going from 58 to 112 tok/s at 35B means roughly doubling how fast you see words on screen.
Prefill affects how long it takes to load context: long system prompts, pasted code blocks, RAG pipelines, multi-turn conversation history. The 57% gain there matters if you're feeding large inputs or doing document analysis.
For most people's daily use, decode is the headline.
### How MLX Differs From the Previous llama.cpp Path
Apple's unified memory means your CPU, GPU, and Neural Engine share the same physical memory pool — no copying data between separate VRAM and system RAM. Traditional GPU frameworks assume separate pools and carry overhead from that assumption.
MLX was designed from scratch around unified memory. It knows the data is already where the GPU can read it. The previous llama.cpp Metal path didn't have that advantage built in — it was ported from a cross-platform codebase. Ollama swapping to MLX is the difference between a translated text and one written natively in the language.
> [!NOTE]
> MLX applies across all Apple Silicon (M1 forward), but Ollama's 0.19 preview is optimized for M5, M5 Pro, and M5 Max hardware. The benchmark numbers above are from M5 Max. If you're on M4 or older chips with eligible memory, expect proportional gains at lower absolute speeds.
---
## Who Actually Benefits From Ollama 0.19 MLX — The Hardware Truth
Most coverage says "Apple Silicon users" and stops there. Here's the part that matters:
**You need more than 32GB of unified memory.** Not 16GB. Not 24GB. The MLX preview enforces this requirement, and the currently supported model (Qwen3.5-35B-A3B) needs it.
Est. Decode Speed
—
—
~65–80 tok/s est.
~90–110 tok/s est.
~120–135 tok/s est.
**112 tok/s confirmed**
*32GB is the stated minimum; M4 Pro 48GB is the comfortable entry point.*
*Pricing as of April 2026: Mac Mini M4 Pro 48GB at $1,999. Mac Mini base M4 from $599.*
If you bought the base M4 Mac Mini — and most people did — the honest read is this: the 93% decode improvement isn't something you'll see on your Qwen2.5 14B workflow. Ollama 0.19 still brings general improvements (smarter cache management, better session memory reuse, improved model loading), but the headline performance gains require hardware most M4 Mac Mini owners don't have.
That's not a knock on the update. It's a preview. More models and lower memory thresholds are flagged as coming. But it's worth knowing before you update expecting a transformed experience on your $599 machine.
> [!WARNING]
> Comparing a 16GB M4 Mac Mini to an RTX 4060 Ti after Ollama 0.19 and expecting MLX gains won't work — those two configurations are in separate categories. For a fair post-0.19 comparison that captures the MLX improvement, you need a 32GB+ Mac and the Qwen3.5-35B-A3B model.
---
## Mac Mini M4 vs. RTX 4060 Ti — Where the Comparison Actually Lives Now
The competitive story from this update isn't where most people expect. It's not M4 16GB vs. RTX 4060 Ti at 14B — that matchup is essentially unchanged. It's at 35B, where the hardware tiers diverge completely.
Loads the Model?
The [RTX 4060 Ti](/glossary/vram) 16GB carries 288 GB/s of GDDR6 bandwidth — genuinely fast memory. But it's 16GB. Qwen3.5-35B-A3B doesn't fit. The M4 Pro at 48GB unified memory with [273 GB/s bandwidth](https://www.apple.com/mac-mini/specs/) runs it fluently, sharing that pool across CPU, GPU, and Neural Engine.
At 35B, this isn't a speed comparison. It's "runs at 100+ tok/s" vs. "can't load the model."
### At 14B and Below — Where NVIDIA Still Holds
The 14B tier is unchanged by this specific release. With llama.cpp Metal (the path all Macs still use for non-MLX models):
- RTX 4060 Ti 16GB (CUDA): ~22 tok/s on Qwen3 14B Q4 (last verified April 2026)
- M4 Mac Mini 16GB (Metal): ~20–24 tok/s on Qwen2.5 14B Q4_K_M
- M4 Pro 48GB (Metal): ~30–35 tok/s on 14B Q4
These are close. And since Ollama 0.19 MLX doesn't yet support the Qwen2.5 14B or Llama family at this quantization, neither config gets a 93% uplift here. The RTX build stays ahead on prefill throughput and costs roughly half as much for a 14B-focused workflow.
### The Real Decision: Total Cost and Use Case Fit
This isn't a clean winner-loser comparison — it's two different tools.
- **Mac Mini M4 Pro 48GB wins on:** silent operation, 35B model capacity, unified memory advantage at high parameter counts, MacOS as a daily driver, no separate GPU power draw
- **RTX 4060 Ti build (~$950-1,050) wins on:** raw prefill speed, CUDA software compatibility, lower cost for 14B work, upgrade path to dual-GPU 70B configs
If you're building specifically to run 14B models cheaply, the NVIDIA path is still better value. If you want a quiet machine that runs 35B for creative work or document analysis — and also happens to be your computer — the Mac is now the clear answer at this model tier.
---
## Which Mac Models Benefit Most From Ollama 0.19
Gains scale with memory bandwidth. Higher bandwidth → faster data through the unified memory pool → higher tok/s at fixed model size.
### M4 Base (16GB and 24GB) — General Improvements Only
The MLX preview doesn't apply here. Your 14B workflows continue on the llama.cpp Metal path, unchanged in throughput. You get Ollama 0.19's general improvements: smarter cache reuse reduces memory pressure across long sessions, and model management is cleaner. Not nothing — but not the headline numbers.
Best model pick for M4 16GB remains: Qwen2.5 14B Q4_K_M for quality, Qwen2.5 7B Q6_K when you want sub-5-second first token latency.
### M4 Pro and M4 Max — Where This Update Matters
At 48GB, the M4 Pro hits the comfortable MLX entry point. With 273 GB/s of bandwidth, you'll see Qwen3.5-35B-A3B decode in the 90–110 tok/s range — a model that was borderline-unusable at 35B speed before this update.
M4 Max configurations with 64–128GB are the true sweet spot. For a full breakdown of which Mac makes sense at which model tier, see our [Mac Mini M4 Pro vs Mac Studio M4 Max for local LLM](/mac-mini-m4-pro-vs-mac-studio-m4-max-local-llm) comparison.
### Older Apple Silicon (M1/M2/M3) With 32GB+
M2 Max 96GB, M3 Max 64GB — if you have the memory, you get the MLX path. Relative gains are similar; absolute speeds are lower than M4/M5 due to bandwidth. An M2 Max at 400 GB/s (for that config) will likely land around 80–90 tok/s on Qwen3.5-35B-A3B — still a big leap from the llama.cpp Metal baseline.
---
## Windows and Linux Users — What Ollama 0.19 Gives You
Nothing from the MLX performance story. MLX is Apple's framework, Apple Silicon only.
Ollama 0.19 on Windows and Linux brings: smarter caching between sessions (reduces cold-start memory pressure), minor CUDA path improvements, and the updated model management interface. Useful, not dramatic. The 57%/93% numbers don't exist on your platform.
> [!WARNING]
> If you benchmark a Windows machine against a 32GB+ Mac running Ollama 0.19 on Qwen3.5-35B-A3B and the Mac destroys it — that's expected, and the reason is hardware tier, not just software. The RTX 4060 Ti 16GB can't load that model at all.
---
## CraftRigs Take — Ollama 0.19 MLX Rewrites the 35B Tier for Apple Silicon
Here's the claim most coverage buries or misses: at 35B, Apple Silicon is now in a category the RTX 4060 Ti 16GB literally can't enter.
That's a bigger story than "M4 16GB is now faster." It's narrower too. This preview works for one model, requires hardware most Mac Mini buyers don't have, and is optimized for M5-generation chips. But where it works, it genuinely works — 112 tok/s on a 35B model, on a machine that whispers, sleeps when you close the lid, and needs no separate GPU power cable.
What this doesn't change: fine-tuning, CUDA-dependent workflows, 70B inference for Mac users who can't afford Mac Studio pricing, and the value equation for anyone running 14B models on a budget.
What to watch: Ollama has flagged custom model support and broader model compatibility as "coming soon" for the MLX path. When common 14B and 27B models get native MLX paths — which seems like a matter of months, not years — the eligibility picture for M4 base and Pro owners changes completely. That's the update worth waiting for if you're on 16GB.
We're updating our [Mac Mini M4 LLM model guide](/best-llm-mac-mini-m4-2026) with a dedicated MLX section, a 32GB eligibility callout, and revised tok/s tables for M4 Pro hardware. If you linked to that guide for speed comparisons, the numbers for 35B are now out of date.
---
## FAQ — Ollama 0.19 MLX on Apple Silicon [2026]
**Do I need to do anything to enable the MLX backend in Ollama 0.19?**
Yes. Pull the supported model with `ollama pull qwen3.5:35b-a3b` on a Mac with more than 32GB of unified memory. The MLX backend activates automatically for that model. No settings flag or manual configuration needed.
**Does Ollama 0.19 MLX work with all models, or only specific ones?**
Only Qwen3.5-35B-A3B in NVFP4 quantization in this preview release. More models and custom model import are flagged as coming soon by Ollama, but as of April 2026, it's a single-model preview.
**Is the Mac Mini M4 now better than RTX 4060 Ti for local LLMs?**
At 35B — the current MLX target — a Mac with 48GB+ unified memory runs the model where the RTX 4060 Ti 16GB can't load it at all. At 14B, where most daily workflows live, the RTX 4060 Ti holds its own at ~22 tok/s and costs less to build around. The right answer depends on which model size matters to you.
**Will these gains appear in LM Studio or only Ollama?**
Ollama only, for now. LM Studio and other inference front-ends would need their own MLX backend integration. None have announced it as of April 2026.
**Does Ollama 0.19 MLX help older Apple Silicon (M1/M2/M3)?**
Yes, with 32GB+ unified memory. MLX applies across all Apple Silicon generations. Absolute speeds will be lower than M5 hardware, but the relative improvement over your pre-0.19 baseline should be similar. Technical Report
Ollama 0.19 MLX Doubles Decode Speed on Apple Silicon [2026]
By The Tester • • 9 min read
Some links on this page may be affiliate links. We disclose it because you deserve to know, not because it changes anything. Every recommendation here comes from benchmarks, not budgets.
ollama apple-silicon mlx mac-mini local-llm qwen
Technical Intelligence, Weekly.
Access our longitudinal study of hardware performance and architectural optimization benchmarks.