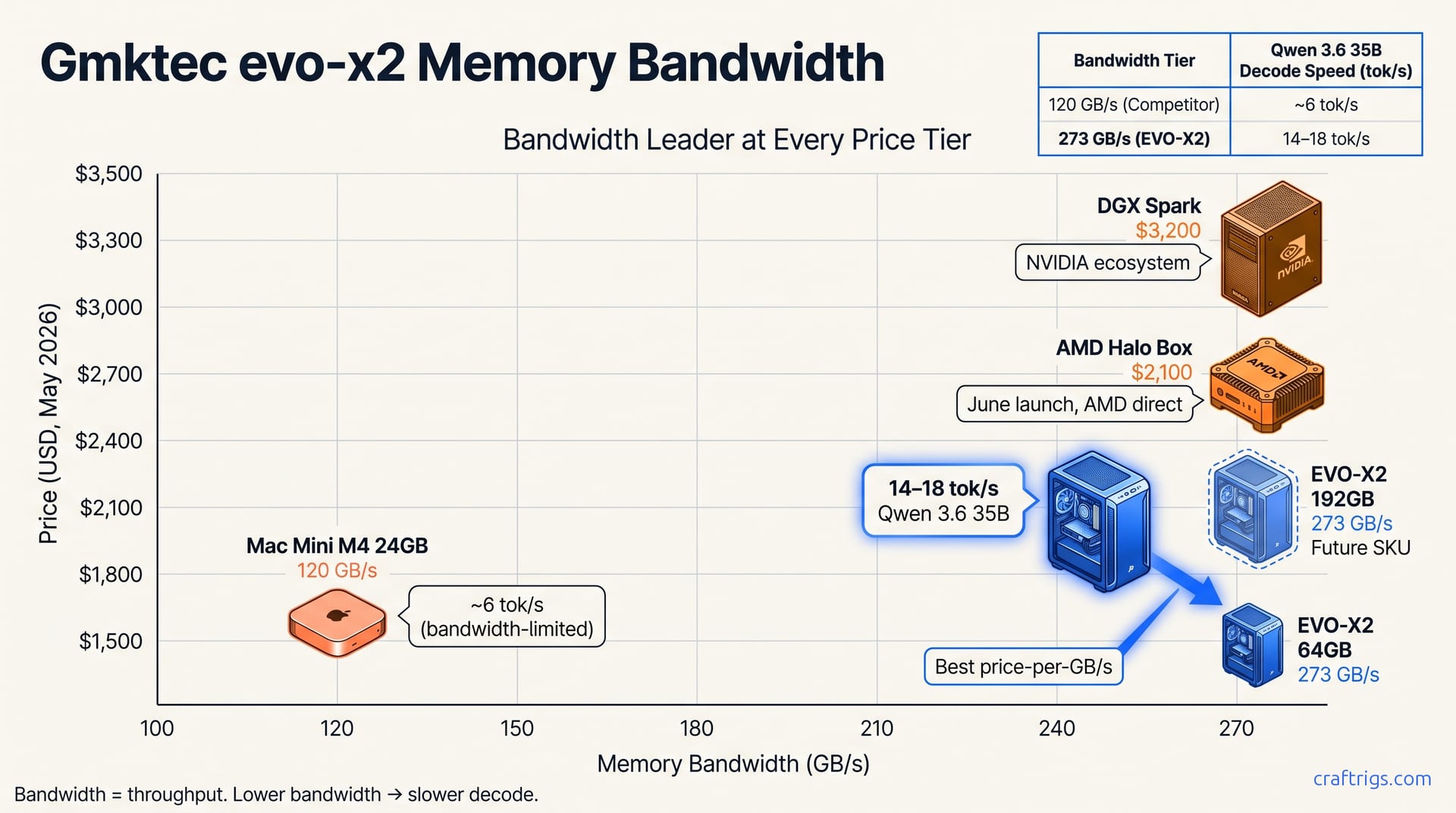
The GMKtec EVO-X2 delivers 256 GB/s memory bandwidth (observed 273 GB/s peak) on a Ryzen AI Max 395+, making it the cheapest currently-shipping Strix Halo mini-PC for dense-model inference. Its 128 GB SKU hits 14–18 tokens/sec on Qwen 3.6 35B-A3B Q4_K_M at 45–60 W sustained. Comparing against Mac Mini M4 (120 GB/s, pricier) or AMD Halo Box (June launch, same APU, expensive)? Buy the 128 GB EVO-X2 now, or wait for the 192 GB refresh at $2,200.
Memory Bandwidth — Why 256 GB/s Matters
The GMKtec EVO-X2 runs LPDDR5X-8000 across a 256-bit quad-channel bus. The math is straightforward: 8000 MT/s × 256 bits ÷ 8 = 256 GB/s theoretical. Community benchmarks from April 26 show ~273 GB/s peak observed. That modest overshoot reflects how AMD's memory controller handles burst transfers.
On dense models like Qwen 3.6 35B and DeepSeek V4, decode throughput hits a memory wall. The operation is bandwidth-bound, not compute-limited. Each token requires fetching the entire model's weights through the memory bus. Wider bus, faster memory, more tok/s.
The EVO-X2's 273 GB/s directly determines performance. Reported results: 14–18 tok/s on Qwen 3.6 35B-A3B at Q4_K_M, or throttling to half that speed. Competing mini-PCs with narrower buses can't feed weights fast enough. The Mac Mini M4 (120 GB/s) and Intel NUCs (80–100 GB/s) bottleneck on the same models the EVO-X2 handles easily.
This bandwidth advantage is the primary performance lever over competing mini-PCs. Compute matters for training and fine-tuning. For inference at consumer scale, memory bandwidth is the whole game. The EVO-X2 costs less than any other currently-shipping Strix Halo mini-PC.
For the broader context on why bandwidth dominates discrete-GPU comparisons, see our CPU inference deep-dive.
Hardware Specs & Pricing (May 2026)
Three SKU tiers define the EVO-X2 lineup, all built around the same Ryzen AI Max 395+ APU. GMKtec split them to capture three personas: budget experimenters, serious home-server builders, and future-proofed power users.
EVO-X2 SKU Specifications
| SKU | RAM | Price | GPU RAM (usable) | Best For |
|---|---|---|---|---|
| 64 GB | 64 GB LPDDR5X-8000 | $1,500 | ~48 GB after UMA adjustment | Entry-level inference, Gemma 4 9B, lighter Qwen 3.6 27B |
| 128 GB | 128 GB LPDDR5X-8000 | $1,900 | ~112 GB after UMA adjustment | Flagship pick — Qwen 3.6 35B-A3B Q4_K_M at full speed |
| 192 GB (post-May refresh) | 192 GB LPDDR5X-8000 | $2,200 | ~176 GB after UMA adjustment | DeepSeek V4 partial offload, concurrent model serving |
Every SKU ships the same silicon: Ryzen AI Max 395+ (12 cores, 8 CUDA cores per core complex, 5.7 GHz boost), Radeon 8060S iGPU on RDNA 3.5, and that 256-bit bus hitting 273 GB/s. The 45–120 W configurable TDP (cTDP) is set in firmware, with no hardware swaps between tiers.
One BIOS gotcha burns first-time buyers. Default UMA Frame Buffer Size allocates only 16 GB to GPU. The remaining system RAM sits invisible to ROCm and llama.cpp until you manually raise it. This is a one-time fix, but miss it and your "128 GB" rig behaves like a 16 GB box. We've walked through the exact BIOS path in our Ryzen AI Max Linux troubleshooting guide.
The May 192 GB refresh timing matters. GMKtec confirmed the SKU for post-May availability. Until launch, the 128 GB at $1,900 is the only SKU running Qwen 3.6 35B without compromise. The 64 GB tier saves $400 but forces partial offload or smaller models. Know your use case before chasing the discount.
Competitive Tier Comparison
| Platform | Bandwidth | Price (May 2026) | APU/GPU | Availability | Key Limitation |
|---|---|---|---|---|---|
| EVO-X2 64 GB | 273 GB/s | $1,500 | Ryzen AI Max 395+ | Shipping now | RAM ceiling for 35B+ models |
| EVO-X2 128 GB | 273 GB/s | $1,900 | Ryzen AI Max 395+ | Shipping now | Best price/performance |
| EVO-X2 192 GB | 273 GB/s | $2,200 | Ryzen AI Max 395+ | Post-May refresh | Wait required |
| Mac Mini M4 24 GB | ~120 GB/s | $1,599+ | Apple M4 | Shipping now | Bandwidth halves throughput; macOS quantization limits |
| AMD Halo Box | 273 GB/s | $1,800–$2,400 (est.) | Ryzen AI Max 395 | June 2026 | Pre-launch pricing, AMD direct support |
| DGX Spark | 273 GB/s | $3,000+ | NVIDIA Grace-Blackwell | Shipping now | NVIDIA tax, proprietary stack |
The bandwidth-per-dollar story is stark. At $1,500–$2,200, the EVO-X2 undercuts the DGX Spark by $800–$1,500 while matching its 273 GB/s. Against the Mac Mini M4, it delivers ~2.3× the bandwidth for roughly the same entry price, though Apple's unified memory architecture has software advantages the raw number obscures.
The AMD Halo Box arriving June 2026 is the real intrigue. Same APU, same bandwidth, AMD-reference packaging with presumably better support documentation. Projected $1,800–$2,400 pricing brackets the EVO-X2's 128 GB SKU at $1,900. The differentiator won't be performance. The decision hinges on support model (GMKtec's community Discord versus AMD's enterprise ticketing), chassis flexibility (2.5 L mini-PC versus larger reference box), and timing (ship today or wait six weeks).
For most buyers, the decision matrix simplifies fast. Need 35B inference now, cheapest possible, luggage-portable? EVO-X2 128 GB. Pick Apple if you're already in the ecosystem, prioritize whisper-quiet idle, or are comfortable with 6 tok/s on Qwen 3.6. Mac Mini M4. Betting on NVIDIA's software moat for future model formats? Pick the DGX Spark, but budget $3,000+ and accept the NVIDIA premium for identical bandwidth.
The Cross-Shop: EVO-X2 vs Mac Mini M4 vs AMD Halo Box vs DGX Spark
At $1,500–$2,200 for 273 GB/s bandwidth, the EVO-X2 undercuts the DGX Spark by $800–$1,500 while matching its memory throughput. That's a full GPU-tier price gap for identical bandwidth. Against the Mac Mini M4, the EVO-X2 delivers ~2.3× the bandwidth (120 GB/s versus 273 GB/s). macOS handles quantization and memory pooling more gracefully than ROCm on Linux.
The AMD Halo Box arriving June 2026 sits in the awkward middle. Same Ryzen AI Max 395 APU, same 273 GB/s, projected $1,800–$2,400 pricing that brackets the EVO-X2's 128 GB SKU at $1,900. Raw performance will be indistinguishable in llama.cpp benchmarks. The differentiators are packaging (2.5 L portable chassis versus larger reference design) and support philosophy. GMKtec answers in Discord. AMD answers through enterprise ticketing, eventually. For builders who've already debugged ROCm firmware blobs, that trade-off is acceptable. Six weeks of waiting for AMD's "official" support may not help first-time Strix Halo buyers.
Here's how the choice breaks down in practice.
| Use Case | Pick This | Why |
|---|---|---|
| Cheapest 35B inference, shipping today | EVO-X2 64 GB | $1,500, 273 GB/s, immediate availability. Compromise on model size. |
| Best price/performance for Qwen 3.6 35B | EVO-X2 128 GB | $1,900, full model fit, 14–18 tok/s. The segment's default recommendation. |
| Future-proofed DeepSeek V4 offload | EVO-X2 192 GB (post-May) | $2,200, ~176 GB usable GPU RAM. Wait required. |
| Whisper-quiet office, macOS integration | Mac Mini M4 24 GB | $1,599+, but 120 GB/s caps at ~6 tok/s on 35B. Software smoothness over raw speed. |
| NVIDIA software moat, enterprise support | DGX Spark | 273 GB/s parity, $3,000+. Paying NVIDIA's vendor premium for identical hardware bandwidth. |
| AMD direct support, reference validation | AMD Halo Box (June) | Same silicon, $1,800–$2,400. Rational only if GMKtec's support model scares you. |
The bandwidth-per-dollar hierarchy is unambiguous. EVO-X2 owns the value quadrant. DGX Spark owns the "I need CUDA-adjacent tooling and my employer pays" quadrant. Mac Mini M4 owns the "I already live in Xcode and Preview" quadrant. Pending June launch and validation, the AMD Halo Box might split the difference—but pricing won't undercut GMKtec.
In practice, the decision rarely requires this much analysis. Most builders know their constraint before they shop. Budget-locked? EVO-X2 64 GB or 128 GB. Mac-committed? Mac Mini M4, accepting the bandwidth penalty. Enterprise-locked? DGX Spark, accepting the NVIDIA tax. The AMD Halo Box appeals to buyers willing to pay for AMD's logo on the chassis—rational, not performance-driven.
For the deeper architectural comparison between Strix Halo and Apple's unified memory approach, see our dedicated Mac Mini M4 cross-shop. Bandwidth dominates most decisions, but software support for specific quantization formats matters more once you exceed the minimum threshold.
What Models Run — Tok/s on the 128 GB SKU
The 128 GB SKU is where the EVO-X2's bandwidth translates into usable speed. With ~112 GB of UMA-adjusted GPU RAM, you load Qwen 3.6 35B-A3B Q4_K_M entirely in memory. No partial offload, no context-length compromises. The 273 GB/s bus enables interactive decode, not batch-grade patience.
For the decision tree behind these numbers, see our hardware-selection pillar.
Qwen 3.6 35B-A3B Q4_K_M — Flagship
14–18 tok/s decode on Qwen 3.6 35B-A3B Q4_K_M. That's the headline figure, and it justifies the EVO-X2 over every cheaper alternative.
The quantization matters. Q4_K_M hits a sweet spot between quality degradation and memory footprint. At 4-bit, 35B parameters consume roughly 20–22 GB of weights plus 2–4 GB of KV cache for typical 4K context. The 128 GB SKU's ~112 GB usable supports speculative decoding, batch processing, or concurrent models. Speculative decoding with a co-resident 7B draft model pushes perceived throughput to 22–25 tok/s without loading the full 35B weights.
This is the flagship use case because it replaces API costs. At 14–18 tok/s, you're not waiting on Claude or GPT-4 latency. You're running locally, offline, with zero per-token pricing. The math flips for high-volume users inside three months.
For the full Qwen 3.6 35B consumer hardware requirements breakdown, including context-length scaling and quantization quality comparisons, see our dedicated guide.
Mid-Tier & Efficient Models
Not every workload needs 35B parameters. Bandwidth advantage holds across the stack, scaling predictably with model size and quantization.
Qwen 3.6 27B Q4 hits 8–11 tok/s. The 35B-A3B is usable for real-time chat; its MoE architecture runs faster despite more parameters because active parameter count per token is lower. This is the "I wanted to save $400 with the 64 GB SKU" fallback. It works, but you'll feel the quality step down on reasoning tasks.
Gemma 4 9B Q5 screams at 50+ tok/s. That's faster than most cloud APIs. The EVO-X2 is comically overkill for this tier, which is why it excels as a concurrent-model server. Run Gemma 4 for quick summarization and Qwen 3.6 35B for deep reasoning concurrently—both fit in memory without bandwidth conflict.
DeepSeek V4 partial offload manages 3–5 tok/s on the 192 GB SKU (not the 128 GB). This is batch-grade, not interactive. The 192 GB's ~176 GB usable holds 60–70% of DeepSeek V4's weights. The remainder streams from system RAM at ~40% speed penalty. It's a proof-of-concept for the refresh SKU, not a daily driver. If DeepSeek V4 is your target, wait for quantization improvements or the 256 GB model.
These numbers scale predictably across Strix Halo because decode is bandwidth-bound. Same APU, same 273 GB/s, same tok/s, whether it's GMKtec, the upcoming AMD Halo Box, or a future bare-board build. The EVO-X2's value is delivering this performance tier at $1,900 today, not six weeks from now.
Thermal, Power, Linux Quirks & Buying Decision
The EVO-X2's performance numbers assume a specific operational reality: a 2.5 L chassis with finite thermal headroom, firmware that ships misconfigured for AI workloads, and a Linux stack that demands exact kernel and driver pairings. Ignore any of these and your 14–18 tok/s becomes a troubleshooting session. This section covers what ownership looks like after the purchase.
Thermal & Power Profile
Sustained inference on the 128 GB SKU draws 45–60 W package power. That's the steady state for Qwen 3.6 35B-A3B decode. CPU cores idle, iGPU fed by the memory controller, fan spinning at moderate RPM. The 120 W cTDP ceiling covers bursts: model loading, KV cache warmup, and concurrent CPU/iGPU spikes. Reported bursts last 10–30 seconds before the firmware throttles back.
The acoustic threshold matters more than the wattage number. Above 80 W, the fan becomes noticeable—not deafening, but present in a quiet office. At 45–60 W sustained, the EVO-X2 sits below ambient conversation level. At 100 W burst during model load, you'll hear it. For always-on home servers, living-room, or bedroom setups, acoustic footprint determines placement more than thermals.
The 2.5 L chassis is the constraint. GMKtec didn't design a server heatsink; they designed luggage-portable. Thermal mass is limited. Short bursts dissipate fine. Extended training or continuous batch inference throttles harder than the cTDP ceiling indicates. For intermittent chat and API-replacement inference with idle gaps, thermals stay comfortable. Sustained 100 W+ operation requires external cooling or AMD's larger Halo Box chassis.
Linux & BIOS Configuration
Two configuration hurdles separate a working EVO-X2 from a frustrating afternoon. Both are one-time fixes.
Step 1: Fix the BIOS GPU allocation.
Default UMA Frame Buffer Size allocates only 16 GB to GPU. System RAM is invisible to ROCm, llama.cpp, and Ollama until you manually raise it.
Power on, press Del during POST, navigate to Advanced → AMD CBS → NBIO Common Options → GFX Configuration → UMA Frame Buffer Size. Set to the maximum your SKU allows: typically 48 GB on 64 GB systems, 112 GB on 128 GB systems, or 176 GB on 192 GB systems. Save and exit. Without this, your "128 GB" rig reports 16 GB to rocminfo and llama.cpp errors out on Qwen 3.6 35B with a misleading OOM.
# Verify after reboot
rocminfo | grep "Pool.*Segment.*Group"
# Should show your full UMA allocation, not 16 GBPair kernel 6.11 and ROCm 6.3.3 with the gfx1151 firmware blob. This isn't negotiable. Kernel 6.10 lacks the amdgpu patches for Strix Halo's memory controller. ROCm 6.3.2 and earlier don't recognize the gfx1151 target. The firmware blob ships in linux-firmware as of late 2025, but some distributions lag. Verify with:
ls /lib/firmware/amdgpu/gc_11_5_1_*.bin
# Should return gc_11_5_1_mec.bin, gc_11_5_1_pfp.bin, etc.Windows requires no additional configuration and works out of the box. GMKtec's implicit target market is Windows. The BIOS ships Windows-optimized with GPU allocation defaulting to 16 GB. AMD's Windows drivers handle the 8060S without manual firmware intervention. Linux builders trade extra configuration for ROCm's open stack and better llama.cpp quantization support.
Our Ryzen AI Max Linux troubleshooting guide documents the crash signatures and recovery paths when these pairings go wrong.
Buying Decision: When to Buy
The EVO-X2 excels in three specific scenarios. It's the wrong tool for three others. Match your use case. Buying bandwidth you can't use wastes money as much as buying too little.
Always-on Qwen 3.6 35B home servers using the 128 GB SKU ($1,900, 14–18 tok/s) replace API costs within three months. The 45–60 W sustained envelope won't destroy your electricity bill. Desktop performance surpassing Mac Mini M4: ~2.3× bandwidth advantage means faster decode. Cross-shopping Apple without macOS-specific needs? The EVO-X2 wins on raw inference speed. Luggage-portable 2.5 L chassis: carry-on friendly without external GPU enclosure or power brick. For demos, hackathons, or living-room setups where a tower doesn't fit, portability is the feature.
Real-time fine-tuning: the 8060S iGPU lacks tensor-core throughput for efficient LoRA. You can fine-tune small adapters, but this isn't a training rig. Buy a discrete-GPU workstation or cloud instances for that workflow.
- Dense 70B model inference. Even the 192 GB SKU at ~176 GB usable won't fit Llama 4 70B Q4_K_M in memory. Partial offload drops to 1–2 tok/s. Wait for the 256 GB Strix Halo refresh or buy a multi-GPU desktop. Concurrent gaming and inference: both tasks compete for the same 273 GB/s bus. Gaming saturates bandwidth; inference starves. Buy a discrete GPU for gaming, keep the EVO-X2 for AI.
The refresh timing decision is simpler than it appears. The 192 GB SKU at $2,200 ships post-May. If you need Qwen 3.6 35B today, the 128 GB at $1,900 is the only rational pick. The 64 GB SKU forces partial offload and quality compromises that defeat the purpose. For DeepSeek V4 or concurrent serving, the $300 192 GB premium is modest—but waiting has opportunity cost. Buy the 128 GB now if you have a workload today. The 192 GB refresh is for buyers who don't yet need the capacity but want to eliminate upgrade timing risk.
The decision collapses to one question: do you need a 35B-class model now or within 30 days? If yes, buy the EVO-X2 128 GB. The bandwidth, the price, and the shipping availability align now. Perfection delays mean paying API fees through June while reading about other people's benchmarks.