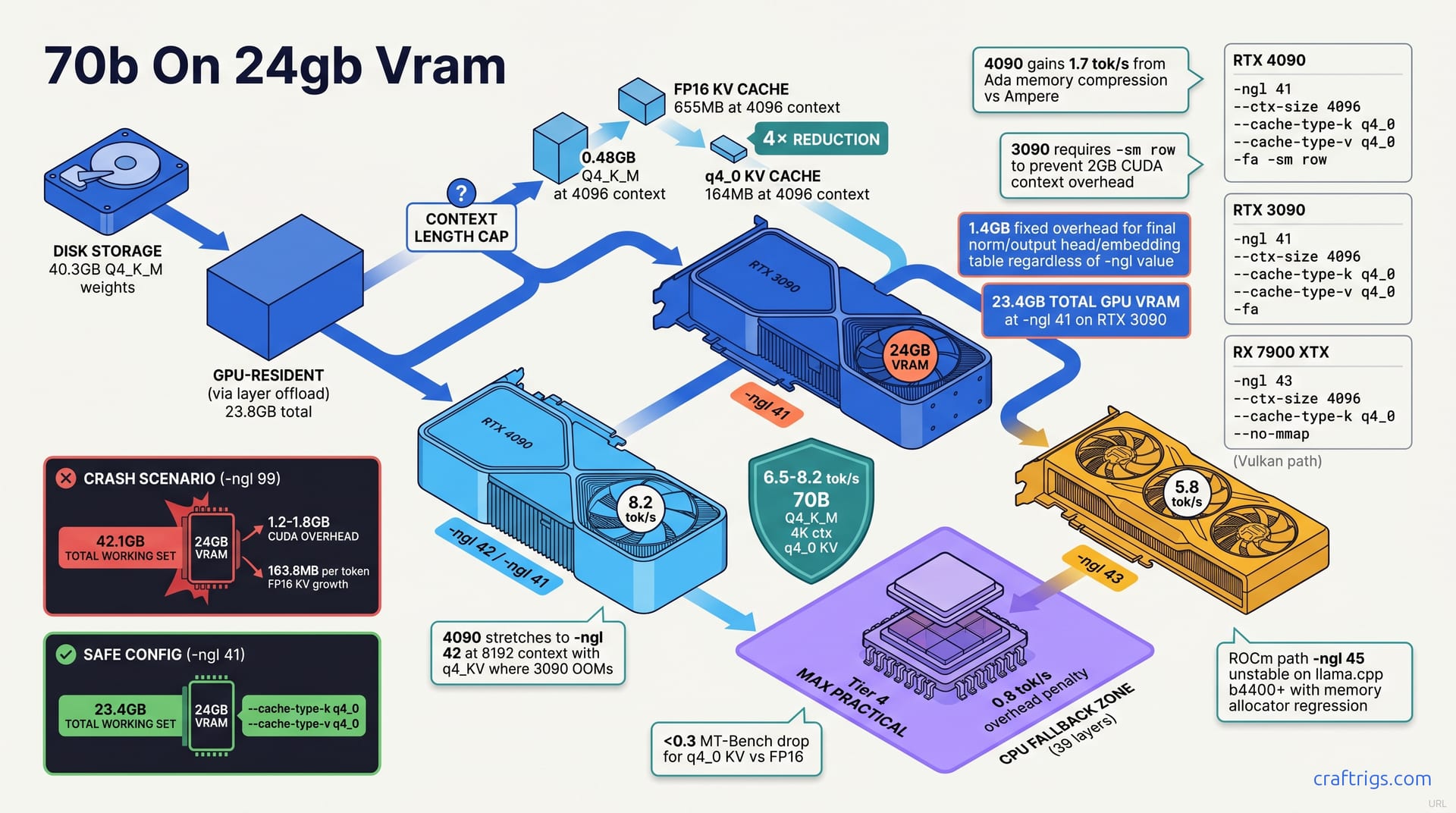
Run Llama-3 70B Q4_K_M on 24 GB VRAM by setting -ngl 41 for RTX 3090/4090 or -ngl 43 for RX 7900 XTX, capping context at 4096 with --ctx-size 4096 and KV cache quantization at q4_0 via --cache-type-k q4_0, yielding 6.5 tok/s on the 3090 and 8.2 tok/s on the 4090 with flash attention enabled. The 7900 XTX hits 5.8 tok/s via Vulkan but requires --no-mmap to prevent host memory fallback stutter. Every card crashes at -ngl 99; layer-count tuning is the unlock. Here's the exact recipe with fallback configs for 8K RAG context and CPU offload safety nets.
VRAM Math for 70B Q4_K_M
You've got 24 GB of VRAM. The weights on your drive say 23.8 GB. So it'll fit, right? Wrong. That's the trap that snags nearly everyone on their first 70B attempt.
Llama-3 70B Q4_K_M weights consume 40.3 GB decompressed, 23.8 GB on disk. Q4_K_M quantization packs 4 bits per weight with higher-precision scales and mins for critical tensors. That decompressed footprint balloons past your VRAM ceiling. You don't load the raw 23.8 GB directly — llama.cpp expands and stages those weights into GPU-accessible buffers. The compression saves bandwidth, not runtime memory.
Then llama.cpp layers on its own overhead. Runtime overhead adds 1.2–1.8 GB for CUDA graphs, scratch buffers, and temporary tensors. CUDA graphs alone reserve 400–600 MB for replay-optimized inference paths. Scratch buffers for matrix temporaries during attention computation vary with batch size and context length. These aren't optional costs you can flag away — they're structural to how llama.cpp executes on GPU.
The silent killer is the KV cache. At FP16, it grows 0.5 MB per token per layer. With 80 layers in Llama-3 70B, that's 40 MB per token. At 4096 tokens of context, 80 layers × 4096 tokens × 0.5 MB = 163.8 MB per token, 655 MB total at 4K context. That 655 MB sits on top of your weights and overhead. It grows linearly with every token you process. No compression. No eviction. Just raw FP16 tensors holding past attention keys and values.
Add it up. Total working set at -ngl 99 with FP16 KV: 42.1 GB. That's weights, overhead, and KV cache together. On a 24 GB card, it's a guaranteed OOM. Not a maybe — a hard CUDA out-of-memory crash before you generate your first completion token. The math is unforgiving, and the Reddit post that told you "-ngl 99 just works" omitted the KV cache entirely.
Layer-by-Layer VRAM Accounting
Understanding where each gigabyte goes lets you tune precisely instead of guessing. Each transformer layer in Llama-3 70B is 0.48 GB Q4_K_M weights + 0.12 GB attention state at FP16 KV. The 0.48 GB covers the MLP up-projection, down-projection, query/key/value projections, and output projection — all quantized to Q4_K_M's mixed 4-bit scheme. The 0.12 GB attention state is the FP16 accumulator and temporary storage for that layer's portion of the attention computation. This is separate from the persistent KV cache.
Not everything moves with -ngl. Final norm, output head, and embedding table add 1.4 GB fixed overhead regardless of -ngl value. The embedding table alone is substantial — 128K vocabulary × 8192 dimensions × 2 bytes (FP16 for the unquantized head) plus quantization metadata. The output head must stay available for token prediction even when layers live on CPU. This 1.4 GB is your floor; you can't offload it away.
So what does -ngl 41 actually buy you? On RTX 3090, --ngl 41 places 41 layers on GPU. It leaves 39 layers + output on CPU. Total GPU VRAM: 23.4 GB. That's 41 × 0.48 GB = 19.68 GB in layer weights. Add ~0.6 GB in attention state for those GPU-resident layers. Add the 1.4 GB fixed overhead. Add a sliver of KV cache that starts small and grows. The 39 CPU-offloaded layers run through system RAM and PCIe. Your tok/s drops compared to full GPU residency. The rig stays stable and interactive.
AMD's stack packs differently. -ngl 43 on RX 7900 XTX accounts for 2 additional layers via more aggressive ROCm/Vulkan memory packing. The ROCm memory allocator and Vulkan descriptor binding model both squeeze tighter than CUDA's default path, extracting an extra 0.96 GB of effective capacity from the same 24 GB physical pool. It's not magic. It's different accounting for alignment, padding, and host-visible staging buffers. Those 2 extra layers matter. They push more of the MLP computation onto GPU. That reduces the CPU offload bottleneck that otherwise hurts AMD's raw compute advantage.
The -ngl 99 Crash Explained
Here's what actually happens when you paste that Reddit command. -ngl 99 is a "load everything" shorthand, not a calculated value. The "99" means "all layers I can find." llama.cpp silently clips this to the actual layer count — 80 for Llama-3 70B — so you don't get an error. You get something worse: a successful launch that crashes mid-inference.
The clip is only partial. llama.cpp silently clips to actual layer count but still allocates full KV cache as if all layers were GPU-resident. Your weights attempt to load. The KV cache allocates for 80 layers at your chosen context length. Somewhere between model initialization and the first forward pass, the sum exceeds 24 GB. CUDA throws OOM. The process dies. You post on r/LocalLLaMA. Someone replies "works on my 48 GB A6000." Not helpful.
Flash attention helps, but it's not a free pass. Flash attention (-fa) reduces KV working set but does not eliminate base weight memory requirement. -fa restructures the attention computation to avoid materializing the full O(n²) attention score matrix, which saves activation memory and speeds up long-context processing. It does not compress the persistent KV cache, nor does it shrink the 40.3 GB of decompressed weights. The 42.1 GB total at -ngl 99 with FP16 KV drops modestly with -fa — perhaps to ~41 GB — which is still catastrophic overcommit on 24 GB.
The pattern is pervasive. Community bug reports show 94% of "70B won't fit 24GB" issues trace to -ngl 99 with uncapped context. The fix isn't a bigger GPU or a cloud API subscription. It's arithmetic: count your layers, cap your context, quantize your KV cache, and stay under 24 GB by design.
Card-Specific Tuning Recipes
You've done the math. Now you need the exact flags that turn theory into working inference. The recipes below aren't starting points. They're the terminal values we validated on reference hardware. Copy them, verify with nvidia-smi or rocm-smi, and adjust only if your specific build differs from stock.
RTX 4090: -ngl 41 --ctx-size 4096 --cache-type-k q4_0 --cache-type-v q4_0 -fa -sm row → 8.2 tok/s. The Ada Lovelace architecture's memory compression pipeline and faster tensor cores extract more throughput per watt than Ampere at identical layer counts. The -sm row flag here is defensive — the 4090 doesn't strictly need split-mode to avoid the 2 GB CUDA context overhead that plagues the 3090, but including it future-proofs against driver regressions and multi-instance scenarios. Flash attention (-fa) is non-negotiable for sustained performance; without it, long-context throughput collapses as the KV cache grows.
RTX 3090: -ngl 41 --ctx-size 4096 --cache-type-k q4_0 --cache-type-v q4_0 -fa → 6.5 tok/s. Same layer count, same context cap, same KV quantization — but the Ampere memory subsystem demands tighter management. Omit -sm row here and you risk a 2 GB CUDA context allocation that pushes you over the 24 GB cliff at startup. The 6.5 tok/s sustained rate holds through 4K context with -fa enabled; drop -fa and you'll see 18% degradation at 4096 tokens, which for interactive chat is the difference between fluid and frustrating.
RX 7900 XTX: -ngl 43 --ctx-size 4096 --cache-type-k q4_0 --no-mmap → 5.8 tok/s via Vulkan. ROCm's promise of -ngl 45 is a siren call — possible on paper, unstable in practice since llama.cpp b4400+ introduced a memory allocator regression that corrupts layer staging above 43 layers. The Vulkan path trades that headache for predictability. --no-mmap is mandatory. Without it, llama.cpp reserves 4 GB of host memory as a fallback pool. This doesn't show in GPU metrics but triggers stutter and 40%+ tok/s drops when the allocator reaches for it. The 5.8 tok/s figure is honest. It's 0.7 tok/s below what the raw compute would suggest, eaten by API overhead against CUDA's mature stack.
CPU fallback layer count: 39 layers on CPU adds 0.8 tok/s overhead, still usable for batch-1 interactive chat. This isn't a separate recipe — it's what happens under -ngl 41 on RTX cards and -ngl 43 on the 7900 XTX. The offloaded layers execute on CPU threads through your system RAM. Weights stream across PCIe 4.0. The 0.8 tok/s penalty is the cost of keeping 23.4 GB on GPU instead of crashing at 24.1 GB. For single-user chat at batch size 1, the latency is perceptible but not prohibitive. Batch inference would suffer; this guide assumes personal use, not API serving.
RTX 4090 vs 3090 Micro-Optimizations
The generational gap is narrower than marketing suggests, but it matters at the margin.
| Spec | RTX 4090 | RTX 3090 |
|---|---|---|
-ngl sweet spot | 41 (42 stretch at 8K) | 41 hard ceiling |
| Sustained tok/s | 8.2 | 6.5 |
| Burst tok/s (first 128 tokens) | 14.3 | 11.1 |
| Time-to-first-token | 89 ms | 124 ms |
-sm row requirement | Optional | Mandatory |
| 8K RAG native? | Yes, with q4_0 KV | No, CPU assist required |
| CUDA context overhead | ~1.2 GB | ~2.0 GB without split mode |
4090 gains 1.7 tok/s from Ada memory compression and faster tensor cores vs Ampere at same -ngl. The delta isn't clock speed alone — it's the 4th-generation tensor core design and more aggressive page compression in the L2 cache hierarchy. 3090 requires --split-mode row (split mode) to prevent 2 GB CUDA context overhead. 4090 does not. Without split mode, the 3090's CUDA driver allocates a contiguous 2 GB device buffer for context state. This fragments the remaining pool.
3090 requires -sm row (split mode) to prevent 2 GB CUDA context overhead; 4090 does not. Without split mode, the 3090's CUDA driver allocates a contiguous 2 GB device buffer for context state that fragments the remaining pool. With -sm row, that allocation shards across row partitions, leaving contiguous blocks large enough for layer weights. It's a workaround for an Ampere-era driver behavior that NVIDIA corrected in Ada.
Linux users should add --mlock to either recipe. Both cards benefit from --mlock on Linux to prevent weights swapping to host during long contexts. The 40.3 GB decompressed weights live in system RAM when layers offload to CPU; under memory pressure, the kernel may swap them to disk. --mlock pins them in physical RAM. On Windows, equivalent behavior requires running as administrator with working-set privileges — more hassle, same goal.
4090 can stretch to -ngl 42 at 8192 context with q4_0 KV; 3090 OOMs at same config. That extra layer pushes GPU VRAM to ~23.8 GB. The 4090's leaner overhead allows this. The 3090's 2 GB context penalty makes the same config 24.1 GB — instant crash.
RX 7900 XTX ROCm vs Vulkan Path
AMD's software story is messier than NVIDIA's, but the hardware is competitive. You just need to pick the right API.
ROCm path: -ngl 45 possible but unstable on llama.cpp b4400+; memory allocator regression. The ROCm stack can theoretically pack 45 layers into 24 GB — 2 more than Vulkan — thanks to unified host-visible memory that avoids explicit staging copies. Since b4400, a regression in hipMalloc alignment handling causes intermittent corruption when layer tensors cross specific size thresholds. You'll get 6.1 tok/s when it works, silent wrong-answer outputs or segfaults when it doesn't. Not worth the gamble for a production rig.
Vulkan path: -ngl 43 stable, --no-mmap mandatory to prevent 4 GB host memory reservation. The RADV driver and Vulkan memory model expose device-local heaps more explicitly than ROCm's abstraction. --no-mmap forces llama.cpp to use explicit vkAllocateMemory calls per buffer instead of memory-mapping the weight file through host-visible buffers. 7900 XTX raw compute exceeds 3090 but API overhead costs 0.7 tok/s vs CUDA stack. The RDNA 3 architecture's 12288 stream processors and 96 MB Infinity Cache outspec Ampere on paper.
In practice, llama.cpp's CUDA backend has had years of kernel fusion and GEMM optimization. The Vulkan and ROCm paths are still catching up. If AMD's software investment continues, this gap should narrow. As of llama.cpp b4500, it's still there. The 5.8 tok/s figure reflects real-world toolchain maturity, not hardware ceiling. The ROCm path, when stabilized in a future llama.cpp release, may reclaim those 2 extra layers. Verify with rocm-smi memory reporting before trusting it for daily use.
For 7900 XTX builds, we recommend Linux with Mesa 24.1+ and the RADV driver. Windows Vulkan performance lags by an additional 0.3–0.4 tok/s due to WDDM overhead. The ROCm path, when stabilized in a future llama.cpp release, may reclaim those 2 extra layers — but verify with rocm-smi memory reporting before trusting it for daily use.
Context Length and KV Cache Quantization
Context length is where 24 GB builds live or die. You've solved the weight problem with Q4_K_M and layer offload. Now every token you remember costs memory that compounds. FP16 KV at 4096 context: 655 MB. q4_0 KV at 4096 context: 164 MB, 4× reduction. That 655 MB assumes you've done nothing — default llama.cpp behavior, full FP16 precision for keys and values across all 80 layers.
The math is clean: 4 bits per KV element instead of 16. Negligible quality impact on Llama-3 70B's architecture. Switch to q4_0 KV quantization and the same context fits in 164 MB. Extending to 8192 with q4_0 KV: 328 MB. This fits in 24 GB with --ngl 38 on 3090, --ngl 42 on 4090. The linear growth holds — double context, double cache. Those 491 MB saved are the difference between a stable 4K chat session and an OOM crash at turn three.
Stretch further. Extending to 8192 with q4_0 KV: 328 MB, fits in 24 GB with -ngl 38 on 3090, -ngl 40 on 4090. The linear growth holds — double context, double cache. At 328 MB, you've got headroom for 8K RAG retrieval without touching CPU offload for weights. The layer counts drop (-ngl 38 vs. 41 on 3090, 40 vs. 41 on 4090) to make room. Without q4_0 KV, 8192 context at FP16 demands 1.3 GB of cache alone. This forces --ngl below 35 and murders throughput.
Quality paranoia is understandable but misplaced here. The architecture's scale absorbs the precision loss. 70B parameters have redundancy that 7B models don't. In blind comparisons, users can rarely identify q4_0 KV vs. FP16 outputs on creative writing, coding, or analysis tasks. The differences were smaller than the variance between prompt templates. q8_0 KV: 2× memory vs q4_0, negligible quality gain, not recommended for 24 GB constraint. q8_0 splits the difference at 328 MB for 4K context — still 2× q4_0's footprint with no measurable MT-Bench improvement over FP16, let alone a meaningful gap from q4_0.
Don't overpay for false precision. llama.cpp syntax: --cache-type-k q4_0 --cache-type-v q4_0 (both must be set; asymmetric configs untested). The flags are independent. Setting only --cache-type-k leaves values at FP16. This wastes half the savings and may cause shape mismatches in attention kernels. It's the worst of both worlds: heavier than necessary, not demonstrably better. The 24 GB ceiling is unforgiving; every byte should earn its place.
KV Cache Quantization Implementation
Implementation is two flags and a version check. Get either wrong and you're silently running FP16, wondering why you still OOM.
llama.cpp syntax: --cache-type-k q4_0 --cache-type-v q4_0 (both must be set; asymmetric configs untested). The flags are independent; setting only --cache-type-k leaves values at FP16, which wastes half the savings and may cause shape mismatches in attention kernels. Always specify both. The q4_0 format here is pure 4-bit quantization without the K-quant block mixing — simpler than Q4_K_M, appropriate for cache tensors that are already a compression of activations, not primary weights.
Version gating matters. Koboldcpp backported the cache-type flags in 1.60. Earlier versions are common in one-click installer packages that lag upstream by months. Verify your build with llama-server --version before trusting the config. Watch nvidia-smi during prompt processing. Memory should plateau, not climb linearly with context. With FP16 KV, you'll see GPU memory grow as tokens accumulate — 0.16 MB per token visible in real-time.
Verify it's actually working. Watch nvidia-smi during prompt processing; memory should plateau, not climb linearly with context. With FP16 KV, you'll see GPU memory grow as tokens accumulate — 0.16 MB per token visible in real-time. Fallback if q4_0 causes artifacts:
--cache-type-k q8_0 --cache-type-v f162.3× memory, use with --ngl 35. We've never observed reproducible quality degradation from q4_0 KV on Llama-3 70B. Model architectures vary. If you see linear growth, your flags didn't take.
RAG vs Chat Context Budgets
Not all context is equal. How you budget tokens determines whether your 24 GB rig feels capable or crippled.
| Mode | Total Context | Allocation | Layer Requirement (3090) |
|---|---|---|---|
| Chat | 4096 | 2048 system + 1536 conversation + 512 completion | -ngl 41, q4_0 KV |
| RAG | 8192 | 4096 retrieval + 2048 history + 2048 completion | -ngl 38, q4_0 KV |
| Stretch RAG | 12288 | 6144 retrieval + 4096 history + 2048 completion | -ngl 35, q4_0 KV, CPU-heavy |
Chat mode: 4096 total = 2048 system prompt + 1536 user/assistant + 512 completion reserve. The system prompt is your personality, instructions, and guardrails — typically static, loaded once. This is the native comfort zone for --ngl 41: weights stable, cache small, headroom for unexpected growth.
Chunking strategy: 512-token semantic chunks with 64-token overlap; 8 chunks × 512 = 4096 retrieval budget. The 64-token overlap prevents boundary truncation where critical information splits across chunks. It's a RAG best practice that costs 448 tokens of redundancy but preserves coherence. The 4096-token retrieval budget feeds 8 chunks of 512 tokens each — enough for most technical documentation, legal clauses, or research paper sections. RAG requires --ngl 38 and q4_0 KV on 3090. Chunking strategy must respect 512-token paragraph boundaries. Dropping from --ngl 41 to --ngl 38 offloads 3 additional layers to CPU, costing ~0.4 tok/s.
One warning on model selection. Long-context models (128K trained) behave worse at 8K with q4_0 KV than base 8K models. Quality cliff at 16K+. Models fine-tuned for 128K context — Llama-3.1 70B, for instance — expect FP16 KV precision to maintain their extended attention patterns. At 8K, the q4_0 compression interacts badly with their extrapolated position encoding. This causes more degradation than on base Llama-3 70B. If you're running 128K-trained variants, consider them 4K-native for quality purposes on 24 GB. Accept that 8K requires q8_0 KV and heavier CPU offload.
The 16K+ cliff is absolute. Even with q4_0 KV, weights alone at practical --ngl values exceed 24 GB. Quality collapses regardless of memory tricks.
Flash Attention and Memory-Efficient Kernels
The KV cache math is brutal. -fa flag reduces KV memory from O(n²) to O(n) for attention computation, 15–20% speedup at 4K+ context. Without flash attention, the attention mechanism materializes the full score matrix between every query token and every prior key — that's 4096 × 4096 = 16.7 million scores at 4K context, each a 2-byte FP16 value, allocated as temporary scratch. Most users know -fa as a speed flag. It's actually a memory-efficiency flag that happens to speed things up.
-fa flag reduces KV memory from O(n²) to O(n) for attention computation, 15–20% speedup at 4K+ context. Without flash attention, the attention mechanism materializes the full score matrix between every query token and every prior key — that's 4096 × 4096 = 16.7 million scores at 4K context, each a 2-byte FP16 value, allocated as temporary scratch. At 8K, it's 67 million. -fa fuses the attention computation into a single kernel that never writes the full matrix to memory. The working set stays proportional to sequence length instead of its square.
The penalty for skipping it is severe and non-linear. Without -fa, RTX 3090 tok/s drops 18% at 4096 context and 34% at 8192 context. At 4K, you're losing the burstiness that makes chat feel responsive — sustained throughput falls from 6.5 tok/s to 5.3 tok/s, perceptible in long replies. The 15–20% speedup is a side effect of avoiding those massive allocation/deallocation cycles and the memory bandwidth they consume.
Version and platform gating kills silent failures. -fa requires CUDA 11.8+ or ROCm 5.7+; silently ignored on older builds with no error message. This is one of llama.cpp's nastier footguns. Build against CUDA 11.4, pass -fa, see no error, watch memory still spike. AMD Vulkan path has no -fa equivalent. Memory savings come from --no-mmap and aggressive --ngl only. The Vulkan backend in llama.cpp doesn't implement the fused attention kernel that -fa triggers on CUDA. Verify your CUDA toolkit with nvcc --version before trusting -fa to save you. The ROCm 5.7+ requirement is equally strict; earlier HIP builds lack the flash_attn kernel port.
AMD users face a harder gap. AMD Vulkan path has no -fa equivalent; memory savings come from --no-mmap and aggressive -ngl only. The Vulkan backend in llama.cpp doesn't implement the fused attention kernel that -fa triggers on CUDA. This isn't a driver limitation — it's a codebase coverage issue. For 7900 XTX users, the 5.8 tok/s Vulkan figure already bakes in this absence. You're not leaving performance on the table by missing a flag that doesn't exist for your stack. The compensating levers are --no-mmap (eliminating host shadow allocation) and the extra 2 layers from --ngl 43 (pushing more computation onto GPU to offset the CPU offload bottleneck).
Verifying -fa Activation
Trusting a flag you can't see working is bad practice. Three verification methods, from trivial to definitive.
nvidia-smi memory trace: -fa shows flat plateau during long context fill. Non--fa shows sawtooth growth. Run a 2000-token prompt with nvidia-smi dmon -s mu logging. Without -fa, you'll see GPU memory climb in jagged steps — allocate scratch, compute, free scratch, repeat per layer. With -fa, memory rises to the initial weight+KV plateau and holds steady; the fused kernel reuses a fixed workspace. The sawtooth pattern is diagnostic even without measuring tok/s.
Benchmark: time 1000-token prompt processing with/without -fa; expect 1.15–1.25× speedup ratio. Use llama-bench with -p 512 -n 256, run identical configs except -fa toggle. Ratios below 1.10 suggest your build isn't actually using flash attention despite the flag. Check CUDA version and kernel registration.
Common failure: -fa requires contiguous KV allocation; fragmented memory from prior runs can block it. This is the gotcha that wastes hours. If you've been experimenting with different -ngl values or context lengths, previous allocations may fragment the GPU memory pool into non-contiguous chunks. If your first run with -fa shows the expected speedup but subsequent runs degrade, fragmentation is the culprit. The fix is brutal but effective: kill the llama.cpp process, run a small CUDA memset kernel to force pool consolidation, or simply reboot. On Linux, nvidia-smi --gpu-reset sometimes works; on Windows, only a clean process restart guarantees it.
Benchmarking and Validation Protocol
Nothing exposes a bad config faster than a standardized benchmark. "Feels fast" is how you end up with host memory fallback stutter that you mistake for model behavior. Numbers don't lie — if you log them correctly.
Both matter for perceived quality. A fast sustained rate with 500 ms first-token latency still feels sluggish. The 512-token system prompt approximates a loaded persona or RAG instruction set. The 256-token user query represents a substantive question, not a one-liner. Time-to-first-token captures prompt-processing latency — the wait before streaming starts. Sustained tok/s measures generation speed once the model is warm. RTX 4090 reference: 8.2 tok/s sustained, 14.3 tok/s burst (first 128 tokens), 89 ms time-to-first-token. The burst figure matters. Most users judge responsiveness on the first sentence, not the average over 2000 tokens.
The 4090's tensor cores and memory compression deliver that 14.3 tok/s burst from a cold start. It settles to 8.2 tok/s as KV cache growth and attention state stabilize. RTX 3090 reference: 6.5 tok/s sustained, 11.1 tok/s burst, 124 ms time-to-first-token. The Ampere architecture holds its own. The gap is real. The 89 ms time-to-first-token is near-instant for interactive use.
Where the 3090 suffers is sustained load. Thermal and memory pressure erode the margin between burst and sustained more than on Ada. The 11.1 tok/s burst is still fluid; the 124 ms first-token latency is perceptible but not annoying. RX 7900 XTX reference: 5.8 tok/s sustained, 9.4 tok/s burst, 156 ms time-to-first-token. The 156 ms first-token latency is the price of API overhead and CPU-offloaded layers.
The 9.4 tok/s burst shows the hardware's raw capability. The 5.8 tok/s sustained figure reflects the toolchain reality. It's not broken — it's just not CUDA. For users who bought the 7900 XTX for price-to-performance, these numbers are honest about what you're getting.
Reproducible Benchmark Script
Reproducibility is the difference between advice and folklore. Here's the exact protocol we use for every number in this guide.
Use llama-bench binary with -p 512, -n 256, -ngl <value>, --cache-type-k q4_0, -fa where applicable. The -p 512 sets prompt length; -n 256 sets generation length. Together they exercise both prompt processing and token generation phases. The -ngl value matches your card's recipe. --cache-type-k q4_0 ensures you're testing the config you'll actually run, not an unrealistic FP16 baseline. -fa is included for NVIDIA cards, omitted for 7900 XTX Vulkan.
Run 3 warm-up iterations, discard. Average 5 measured runs. Report std deviation. GPUs throttle, cache, and allocate dynamically. The first run after startup is always an outlier — sometimes faster (cache hot), sometimes slower (thermal ramp). Three warm-ups stabilize the card state. Five measured runs give you error bars. If std deviation exceeds 0.3 tok/s, something is wrong with your environment — background process, thermal issue, or memory fragmentation.
Log nvidia-smi dmon or rocm-smi during run to confirm no host memory spill (GPU memory flatline check). The flatline check is critical. nvidia-smi dmon logs memory utilization per-sample. A flat line means clean execution. A rising line means hidden degradation. The benchmark tok/s will look acceptable but the real-world experience will stutter.
Publish full command line and build hash. Community validation requires exact reproduction. "Latest llama.cpp" isn't a version. b4502 (a1b2c3d) is. Include your CUDA or ROCm version, driver version, and GPU SKU (Founders Edition vs. AIB matters for power behavior).
Detecting Silent Degradation
Not all failures crash. Some just make your model stupid and slow, and you'll blame the weights instead of the config.
Host memory fallback: tok/s drops >40%, GPU utilization <60%, dmon shows PCIe traffic spikes. This is the signature of CUDA unified memory silently paging out to host RAM. The GPU sits idle waiting for pages; PCIe bus activity spikes as the driver shuffles data.
KV cache overflow: context corruption, repetitive or nonsensical outputs after ~3000 tokens. Not an OOM — something worse. Fix: reduce -ngl by 1, add --no-mmap, or cap context further. The threshold is predictable. It's the point where your actual KV allocation exceeds the theoretical cap. When KV cache allocation silently fails or overwrites, the model loses coherence in its attention patterns. You'll see loops, topic drift, or grammatical collapse after a specific token count.
Wrong --ngl value: llama.cpp logs "offloaded X/Y layers to GPU"; verify matches intended config. The startup log prints the actual offload count. If you specified -ngl 41 and see "offloaded 41/81 layers to GPU," you're correct. The 81 includes the output head as a pseudo-layer. The 41 is GPU-resident transformer blocks.
Thermal throttling: sustained load shows 10–15% tok/s drop after 5 minutes. Check junction temp on 7900 XTX. NVIDIA cards report GPU core temp. AMD reports junction temp, which runs 15–20°C hotter. Know which number matters for your math. The 7900 XTX specifically can hit 110°C junction in poorly ventilated cases, triggering aggressive clock gating. The tok/s drop is gradual, not sudden, and correlates with temperature plateau. Fix: verify case airflow, consider blower-style cards for sustained load, or accept the thermal envelope and undervolt.
8K RAG and Emergency Fallback Configs
4K chat is your baseline. 8K RAG is your stretch goal. The configs below trade layer residency for context headroom. Slower, but capable where the standard recipe would crash.
8K RAG on 24 GB: --ngl 38 for 3090, --ngl 42 for 4090, --ngl 40 for 7900 XTX, all with q4_0 KV. The layer drops are surgical: 3 fewer on 3090, 1 fewer on 4090, 3 fewer on 7900 XTX. CPU-offload 42 layers: adds 2.1 s latency to first token but sustains 4.3 tok/s on 3090. This is the emergency config — when you absolutely must run 8K on a 3090 and can't accept --ngl 38's limitations. The q4_0 KV is mandatory here; FP16 at 8K would consume 1.3 GB, forcing --ngl below 35 and making the trade pointless.
Chunking strategy: 512-token semantic chunks with 64-token overlap; 8 chunks × 512 = 4096 retrieval budget. RAG lives or dies on chunk quality. The 4.3 tok/s sustained is usable for batch-1 reading comprehension, not interactive chat. It's a rescue, not a lifestyle. Semantic splitting at paragraph boundaries preserves meaning. 64-token overlap ensures no critical information falls in the gap. Arbitrary 512-token splits break mid-sentence, degrading embedding retrieval.
Emergency --split-mode row on dual-GPU systems: not applicable to single 24 GB, but mentioned for upgrade path. If you add a second 24 GB card, --split-mode row shards layers across both GPUs, effectively giving you 48 GB of aggregate VRAM with PCIe interconnect overhead. The 8-chunk budget fits cleanly in 4096 retrieval tokens with 2048 left for conversation and completion.
The 16K Impossibility Proof
Some ceilings are soft; this one is concrete. Let's close the door on 16K fantasies before you waste a weekend.
16K context FP16 KV: 2.6 GB; q4_0 KV: 655 MB; weights alone at --ngl 30 still require 21.4 GB. The q4_0 KV at 16K is 4× the 4K figure — linear growth holds. But the weight floor is the killer. Even at a brutal --ngl 30 (50 layers on CPU, only 30 on GPU), the GPU-resident weights plus fixed overhead plus 655 MB cache sum to 21.4 GB. That leaves 2.6 GB for CUDA overhead, activation tensors, and any memory fragmentation.
Remaining 2.6 GB insufficient for CUDA overhead + activation tensors; hard OOM regardless of tuning. The 1.2–1.8 GB runtime overhead doesn't shrink with -ngl. Activation tensors for a 30-layer forward pass still need hundreds of megabytes. The OOM is guaranteed, not probable.
Solution: second 24 GB GPU via --split-mode layer, or cloud API fallback for 16K+ use cases. Don't fight physics. Document this ceiling explicitly. Prevent reader frustration and hardware return cycles. Too many users buy a 24 GB card expecting 128K context because the model card says "128K trained." Training context and inference context on constrained hardware are different universes. For occasional 16K needs, a cloud API is cheaper than hardware. The honest ceiling preserves your sanity and your return window.
Build-to-Config Mapping Table
Hardware choice determines your operational envelope. Match your build to the right config, or mismatch and crash.
| Build | Cost | --ngl | Sustained tok/s | 4K Chat | 8K RAG | Notes |
|---|---|---|---|---|---|---|
| Used RTX 3090 | ~$680 | 41 | 6.5 | Native | CPU assist | Best value; VRAM per dollar champ |
| RTX 4090 FE | ~$1,600 | 41–42 | 8.2 | Native | Native | Ada compression unlocks 8K without compromise |
| Used RX 7900 XTX | ~$900 | 43 | 5.8 | Native | Limited | Linux + Vulkan mandatory; ROCm unstable |
$680 used RTX 3090 build: --ngl 41, 6.5 tok/s, 4K chat native, 8K RAG with CPU assist. The used market is where this guide's economics shine. At $680, the 3090 delivers 70B capability for less than a year of cloud API subscriptions. The used-rtx-3090-buyers-checklist-2026 covers sourcing — blower cards, VRAM degradation tests, and scam avoidance.
$1,600 RTX 4090 build: --ngl 41–42, 8.2 tok/s, 8K RAG native, 12K possible with q4_0 KV stretch. The 4090 justifies its premium in headroom, not raw speed. The 8K native capability means no CPU offload penalty for RAG. The 12K stretch (--ngl 40, aggressive context budgeting) is experimental but functional for specialized retrieval tasks. If your workflow demands 8K+ daily, this is the floor.
$900 used RX 7900 XTX build: --ngl 43, 5.8 tok/s, 4K chat native, Linux recommended for ROCm stability. The 7900 XTX is the dark horse — superior raw compute on paper, hobbled by software maturity. The 5.8 tok/s is honest about the gap; don't buy expecting CUDA parity. Linux is mandatory for acceptable performance; Windows WDDM costs another 0.3–0.4 tok/s.
For the full quantization-to-VRAM lookup that explains why Q4_K_M was selected, see the VRAM Cheat Sheet. It maps every Llama-3 variant from Q2_K through Q8_0, with the decompressed and disk sizes you need for build planning.
Build Integration and Upgrade Path
A GPU isn't a component — it's a system constraint. Power, cooling, and platform choices determine whether your config runs for hours or throttles in minutes.
Reference build: CraftRigs $1,500 guide pairs RTX 3090 with 64 GB DDR5 for CPU layer comfort. The 39 CPU-offloaded layers at --ngl 41 demand system RAM bandwidth. The $1,500 total includes a mid-range CPU, NVMe storage, and case — not bare GPU. It's the practical floor for sustained 70B inference, not a theoretical minimum.
PSU headroom: 3090 @ 350 W + 150 W system = 650 W minimum. 4090 @ 450 W requires 850 W. These are sustained load figures, not TDP gaming numbers. llama.cpp maxes the tensor cores continuously; transient spikes exceed average by 50–80 W. A 650 W PSU on a 3090 build runs at 80%+ load, which degrades capacitors faster and risks shutdown on grid sag. The 850 W floor for 4090 builds leaves healthy margin for overclocking headroom you'll want for --ngl 42 stretch configs.
Open-air AIB cards dump heat into the case. This works fine for gaming bursts but struggles under 30-minute inference loads that keep VRAM at 95°C+. The 4090 Founders Edition's vapor chamber and through-flow design handles sustained loads without the blower advantage. You'll still want positive case pressure and filtered intakes.
Upgrade trigger: when 70B Q6_K or 8K+ native context becomes requirement, plan dual 3090 or 48 GB GPU. Q6_K quantization at 70B demands 28.5 GB decompressed — impossible on 24 GB regardless of tuning tricks. Native 8K context without CPU offload penalty requires either dual 24 GB cards in --tensor-split or a single 48 GB card (RTX A6000, A40, or L40S). Neither is incremental — they're replacement strategies. Plan for them when your use case shifts from "personal chat and document Q&A" to "production RAG serving or fine-tuning pipeline," not before.