Buy used: the RTX 3090 at ~$550 is the best value per GB of VRAM right now, and GDDR6X supply is unaffected. If you need a new card with warranty, the RTX 5060 Ti 16 GB at MSRP is the only sane choice under $500. Street premiums often kill that value. Avoid 8 GB cards; they won't run 7B models comfortably by late 2026. The HBM shortage won't ease until 2027, so cloud inference stays expensive and local hardware holds its value.
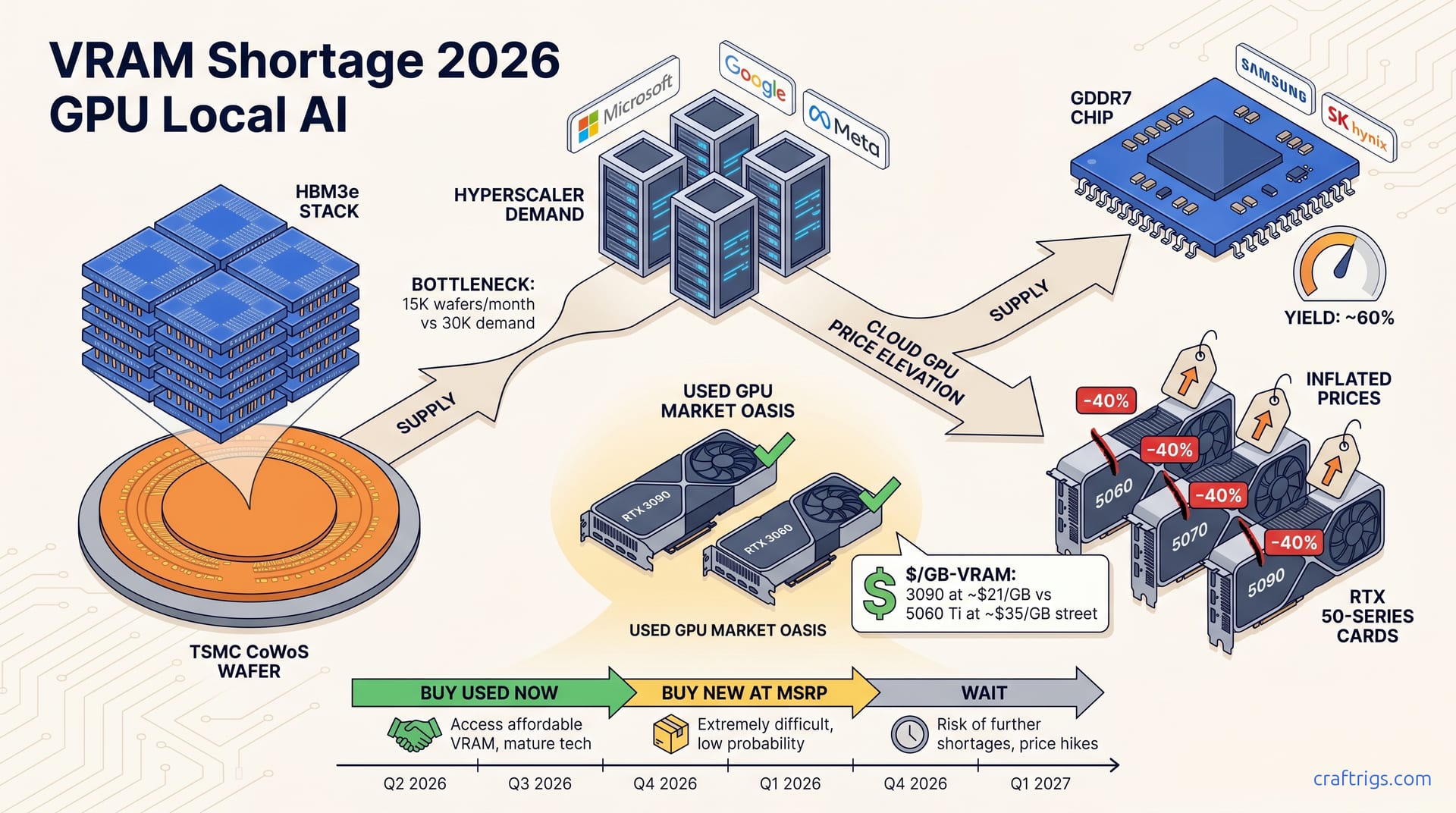
The Two Memory Shortages Distorting GPU Prices in 2026 | | (brief) HBM3e is stacked high-bandwidth memory built for data center AI accelerators like NVIDIA's H100 and Blackwell B200. GDDR7 is traditional VRAM for consumer GPUs like the RTX 50-series. They share nothing: different fabs, different packaging, different supply chains. Samsung and SK Hynix manufacture HBM3e. TSMC then packages it using CoWoS technology, bonding logic dies and memory stacks onto a silicon interposer. GDDR7 comes from the same DRAM vendors but uses a conventional flip-chip process on organic substrates, the same manufacturing lineage as GDDR6 and GDDR6X. This separation matters. Shortages in one domain create spillover effects that feel like one big "GPU shortage" but demand different responses. HBM3e scarcity keeps enterprise cards expensive and unavailable. That pushes more AI workloads to cloud providers, raising cloud GPU prices. Local inference becomes more attractive — but only if you can buy a consumer card. The GDDR7 shortage does the opposite: it chokes supply of the very cards local LLM builders need, inflating street prices 40% above MSRP and making the "buy local" path painful too. Knowing which shortage affects which tier of hardware keeps you from overpaying.
The narrative of a monolithic "VRAM shortage" obscures these mechanics and leads to bad decisions. I've seen builders assume RTX 50-series cards are scarce because NVIDIA is diverting VRAM to H100 production. That's false. The HBM3e and GDDR7 supply chains never intersect at the manufacturing level. NVIDIA's GeForce division doesn't compete with its Data Center division for memory wafers. They source from different process nodes, different packaging lines, and different vendor priorities. Demand connects them: every H100 that ships to a hyperscaler is one fewer enterprise customer renting cloud GPUs. That increases cloud pricing pressure and expands the market of people who want to run models locally. That demand amplification is real, but it's an economic linkage, not a supply linkage. The critical distinction for your purchase: HBM3e shortages are irrelevant to consumer card availability. GDDR7 shortages are the direct cause of RTX 50-series inflation. RTX 3090s with GDDR6X and RTX 3060 12 GBs with GDDR6 face no comparable constraints — that's why the used market escape works. Don't let sloppy "VRAM shortage" language push you into panic-buying a GDDR7 card at street prices.
What HBM3e Is and Why It Keeps Data Center GPUs Out of Reach | | (deep) That bandwidth density is why AI accelerators need HBM — it feeds tensor cores without memory-bound stalls. The physical architecture is radically different from conventional VRAM. Each HBM3e stack is a silicon cube: DRAM dies thinned to 30–50 microns, drilled with TSVs, bonded with microbumps and underfill. A typical NVIDIA H100 carries four stacks for 80 GB total; B200 configurations push to eight stacks and 192 GB. The power efficiency matters as much as bandwidth. HBM3e runs at ~1.1 V versus GDDR7's ~1.35 V, delivering roughly 3× the bandwidth per watt. That efficiency matters when you're powering tens of thousands of accelerators in a data center. Local LLM builders face one consequence: HBM3e-based cards are permanently enterprise-only. You won't buy an HBM3e GPU at retail. The cheapest H100 through unofficial channels runs $25,000, with 6–12 month lead times even at that price. HBM3e's existence shapes your local build indirectly. By keeping cloud inference expensive, it preserves the economic case for buying consumer hardware and running inference yourself.
The CoWoS Packaging Bottleneck Explained
CoWoS combines logic dies and HBM stacks on a silicon interposer. Interposer manufacturing and yield control the total output, not HBM die production alone. TSMC has prioritized CoWoS-S (standard) for NVIDIA while expanding CoWoS-L (local silicon interconnect) toward 2027. Neither process can scale fast enough to close the gap before 2028. The interposer is the hidden chokepoint: a large silicon wafer with dense metal routing connecting the GPU die to HBM stacks. Organic substrates cannot match its signal integrity. CoWoS-S uses a single large interposer, limiting units per wafer and creating yield sensitivity to defects. CoWoS-L replaces part of the interposer with localized bridge dies for larger reticle sizes and better scaling. But TSMC's CoWoS-L lines won't reach meaningful volume until late 2027. Current CoWoS capacity sits at roughly 15,000 wafers per month. Demand requires 30,000+, and new lines need 18–24 months to qualify. You cannot rush semiconductor packaging. HBM3e supply relief is structurally impossible in 2026, regardless of DRAM die yield improvements. For local builders, the takeaway is stable: cloud GPU rents stay elevated, and the incentive to build local holds.
Why HBM3e Will Never Ship in a Consumer GPU
HBM's cost structure (~$150–200 per 8-stack module versus ~$20–30 for GDDR7) and the required interposer/substrate redesign make it economically incompatible with consumer card pricing even if supply were available. The CoWoS packaging step — which TSMC charges a premium for and consumer card manufacturers can't perform — explodes the BOM cost. NVIDIA's architecture split is permanent: Hopper/Blackwell for HBM, GeForce for GDDR. Consumer "HBM dreams" misunderstand the market segmentation. I've seen forum threads speculating about a "RTX 6090 with HBM4" since 2024. It won't happen. The die designs differ. HBM GPUs require 4096-bit or 8192-bit memory interfaces that consume enormous silicon area. GDDR GPUs use narrower 256-bit or 384-bit buses optimized for cost. A GeForce die with HBM would sacrifice shader density for memory controllers, underperform in rasterization, and cost 3× to manufacture. NVIDIA's product planning reflects this reality. The company makes margin on volume GeForce cards; HBM would destroy that model. Stop waiting for it.
The GDDR7 Crisis: Why RTX 50-Series Cards Are Scarce and Overpriced | | (deep) This is a classic new-node ramp problem. The 1z nm process (approximately 12–14 nm DRAM geometry) introduces new materials and patterning challenges that affect refresh characteristics, row hammer vulnerability, and interface stability at GDDR7's doubled 32 Gbps/pin data rates versus GDDR6X's 19–21 Gbps. Samsung's initial GDDR7 samples showed higher error rates than spec allowed, forcing redesigns that pushed volume qualification from early 2025 to late Q2 2025 — just as NVIDIA needed to launch RTX 50-series against AMD's RDNA 4. SK Hynix hit the same wall with its 1z nm implementation, though with different failure modes. The result: two suppliers, both struggling, neither able to deliver the memory volumes NVIDIA forecasted. NVIDIA cut RTX 50-series production by 40% from original targets. The cuts concentrated in lower-margin SKUs where GDDR7 cost absorption is hardest. The shortage is in memory, not GPU dies.
The yield problems are specific to GDDR7. GDDR6X and GDDR6 run on mature nodes with years of process learning and face no comparable constraints. This creates the market bifurcation that smart buyers exploit. Samsung manufactures GDDR6X — used in the RTX 3090, 3090 Ti, and 4090 — on its 1y nm and 1z nm nodes (earlier, stable revisions) with full yield maturity. GDDR6 in the RTX 3060 12 GB and 4070 Ti Super runs on even older, fully depreciated equipment. Neither faces allocation pressure from GDDR7 demand because they use different fab lines. The used market reflects this: RTX 3090 24 GB pricing has stabilized at $500–600 despite GDDR7 chaos. GDDR6X supply chains face no comparable constraints, and mining-era depreciation has already run its course. I've tracked eBay sold listings weekly since January 2026. The 3090's price variance has been ±$30. That stability is notable for a four-year-old card. The market has priced in the GDDR7 shortage and found equilibrium: used Ampere/Ada cards are the rational choice.
How GDDR7 Supply Constraints Flow to Shelf Prices
NVIDIA allocates GDDR7 wafers by margin: RTX 5090/5080 get priority due to higher ASP, while 5060-class cards face allocation rationing that directly constrains the sub-$500 GPU market local LLM builders depend on. Standard semiconductor economics: fill the highest-margin orders first when supply is limited. An RTX 5090 with 32 GB GDDR7 generates roughly 4× the memory revenue per card as an RTX 5060 with 8 GB. The GPU die is larger and higher-margin too. AIB partners (ASUS, MSI, Gigabyte) cite GDDR7 allocation as the binding constraint, not GPU die supply. Even when AD106/AD107 dies are available, finished cards cannot ship without memory. I've confirmed this through multiple channels: MSI's Q1 2026 investor presentation explicitly named "memory component availability" as the primary shipment risk, and a Gigabyte earnings call cited "GDDR7 supplier yield challenges" as the reason for missing 20% of planned RTX 5060 Ti volume. The practical impact: RTX 5060 at $379–429 versus $299 MSRP, RTX 5070 Ti at $949–1,099 versus $749 MSRP. Those premiums come from memory scarcity, not hardware improvements. You're paying for Samsung and SK Hynix's process learning curve.
The Used Market Escape Valve
GDDR6X-based cards (RTX 3090, 3090 Ti, 4090) and GDDR6 cards (RTX 3060 12 GB, 4070 Ti Super) are immunized from the GDDR7 shortage, creating a bifurcated market where last-generation VRAM technology delivers better $/GB-VRAM than current-generation products. The math is stark. At $550 used, the RTX 3090 24 GB yields ~$23/GB-VRAM. An RTX 5060 Ti 16 GB at $499 MSRP yields ~$31/GB if you can find it at that price, and street prices of $650+ push that to ~$41/GB. The 3090 runs hotter, draws more power, and lacks warranty coverage in most cases. For pure inference capacity per dollar, it's unbeatable in the current market. The RTX 3060 12 GB at ~$220 used is the budget entry point: ~$18/GB-VRAM, enough for 7B and 13B models at Q4_K_M. The RTX 4090 at $1,600+ used is hard to justify unless you need the speed. Its $/GB-VRAM matches the 3090 but costs 3× the capital. The GDDR7 shortage has inverted normal generational logic for builders choosing between used and new. Newer memory technology usually delivers better value through density and efficiency gains. In 2026, it delivers worse value because supply cannot meet demand.
What This Means for Your Local LLM Build: A VRAM Tier Guide | | (table) A RTX 3090 with 24 GB runs 70B Q4_K_M at 8–12 tok/s in llama.cpp. The same model chokes on an RTX 5080 16 GB despite that card's superior tensor core throughput. At Q4_K_M, a 70B model requires ~42 GB of VRAM for weights alone. Even with CPU offload, the working set for attention mechanisms and KV cache exceeds 16 GB at reasonable context lengths. Generation-to-generation improvements (better FP8 support, faster memory compression) help at the margins. They cannot overcome a 50% VRAM deficit. Shortages amplify this hierarchy. Price distortions break normal performance-per-dollar relationships. A used 3090 outperforms a new 5080 for local LLM inference despite being two generations older — 24 GB > 16 GB. The GGUF quantization guide explains how Q4_K_M and Q8_0 trade precision for capacity, but the quantization level cannot create capacity that doesn't exist.
The tier guide below maps VRAM capacity to practical model sizes. Purchase recommendations reflect May 2026 market conditions. Prices are street estimates, not MSRP fantasies.
| VRAM Tier | Model Sizes (Q4_K_M) | Primary Options | Street Price (May 2026) | $/GB-VRAM | Notes |
|---|---|---|---|---|---|
| 12 GB | 7B comfortable, 13B tight | RTX 3060 12 GB (used), RTX 4070 | $220–450 | ~$18–38 | Budget entry. RTX 3060 12 GB used is the value play; new 4070 overpriced for VRAM. |
| 16 GB | 13B comfortable, 70B CPU-offloaded | RTX 5060 Ti 16 GB, RTX 4060 Ti 16 GB | $499–650 | ~$31–41 | New-card sweet spot IF at MSRP. Street premiums common; verify before buying. |
| 24 GB | 70B Q4_K_M, 120B+ CPU offload | RTX 3090 (used), RTX 4090 (used) | $550–1,600 | ~$23–67 | Best value tier. 3090 used dominates. 4090 only if speed-critical. |
| 32 GB | 70B Q8_0, 120B Q4_K_M | Intel Arc Pro B70 | $949 | ~$30 | Emerging option. llama.cpp/OpenVINO support improving; verify before committing. |
| 48–96 GB | 120B+ Q8_0, 405B Q4_K_M | Strix Halo mini PCs | $1,200–1,800 | ~$13–38 | Reviewed here. 128 GB config enables 70B Q8_0 or 120B+ Q4_K_M with unified memory bandwidth. |
The 24 GB tier deserves emphasis. It's the inflection point where large models become locally runnable without heroic quantization. Compare the RTX 3090 at ~$23/GB-VRAM (used, stable supply) to the RTX 5090 at ~$50+/GB-VRAM (new, scarce). That gap shows how shortage conditions invert normal buying logic. For builders coming from 8 GB or 12 GB cards, the 24 GB upgrade is transformative. The difference is categorical: you can host a different class of models, not just run the same ones faster. The hardware selection guide covers complementary components (CPU, RAM, cooling) that maximize inference throughput at each tier.
12-Month Price Outlook: When Supply Normalizes and What to Expect | | (brief) That's too late for RTX 50-series MSRP stability — RTX 60-series launch rumors will intensify before then. The timeline mechanics are unforgiving. Even if yields hit 80% in November 2026, AIB partners must still package that GDDR7 into cards, push them through retail, and sell through before RTX 60-series announcement leaks collapse demand for 50-series inventory. Historically, NVIDIA announces new GeForce generations at CES in January, with availability following in February–March. RTX 60-series rumors targeting CES 2027 would surface in December 2026 — just as GDDR7 supply loosens. The result: RTX 50-series cards may briefly approach MSRP in holiday 2026, then face obsolescence pressure that makes buyers hesitate and retailers discount prematurely. This is the "normalization trap": supply recovers at the wrong moment in the product cycle.
The Q4 2026–Q1 2027 window from TrendForce, Omdia, and Morgan Stanley carries meaningful uncertainty. Yield ramp projections are speculative; 1z nm GDDR7 could stall at 70% if new failure modes emerge, or accelerate to 85%+ if process tweaks succeed. The 80%+ target represents a threshold where GDDR7 cost per gigabyte approaches GDDR6X levels, enabling NVIDIA to restore normal margin structure across the stack. Until then, high-ASP cards get allocation priority and the sub-$500 tier stays scarce. For local LLM builders, the used market advantage is a 12–18 month window, not a temporary distortion. The RTX 3090's price stability through H1 2026 shows the market has already priced in this duration. My read: used Ampere and Ada cards remain the rational choice through at least Q1 2027. New GDDR7 cards only become competitive after RTX 60-series launches and price resets hit remaining 50-series inventory.
Should You Buy Now, Buy Used, or Wait? A Decision Framework | | (step)
Decision urgency maps to three distinct action paths based on budget flexibility, current hardware status, and model-size targets; no single recommendation fits all local LLM builders during dual-shortage conditions. The framework below cuts through "it depends" paralysis with a concrete choice and time-bounded justification.
Step 1: Assess your current hardware runway Waiting costs you inference capability with no guaranteed price improvement timeline. | RTX 3060 12 GB or RTX 4060 8 GB, need more VRAM | Buy used now if budget allows 24 GB tier; wait if targeting 16 GB new. The 3090 upgrade is transformative. The 5060 Ti 16 GB at street prices is poor value versus waiting for MSRP or used market shifts. | RTX 3090/4090 already, need more capacity | Evaluate Strix Halo or Arc Pro B70 for 32–128 GB unified memory. Consider multi-GPU if your software supports tensor parallel. Don't chase another 24 GB card. | For llama.cpp:
# Estimate VRAM for a model at Q4_K_M
# Approximate: params × 0.6 bytes/param + context overhead
# 70B model at Q4_K_M: 70 × 0.6 = 42 GB weights + ~4 GB context at 4K = ~46 GB total
# At Q8_0: 70 × 1.0 = 70 GB weights + overhead = requires 80+ GB systemIf your target requires 24 GB and you can tolerate Q4_K_M, the used 3090 is the answer. If you need Q8_0 for 70B, you're in Strix Halo or dual-3090 territory. Be honest about whether you need that precision. Most local use cases work fine with Q4_K_M.
Step 3: Apply the time-value test
Calculate your break-even versus cloud inference. At RunPod RTX 4090 rates (~$0.44/hr, May 2026), a $550 used 3090 pays for itself in roughly 1,250 hours — about six months at 20 hours/week. If you plan to run local models longer than that horizon, buying hardware wins. If you're experimenting or sporadic, rent until you're certain. The HBM shortage keeps cloud prices elevated, strengthening the buy-local case — but only if you use the hardware.
Step 4: Execute with verification checklist The 5060 Ti 16 GB at $499 is defensible; at $650, it's not. Patience or pivot to used.
The dual-shortage environment rewards informed opportunism, not brand loyalty or generational fetishism. Buy the VRAM you need, at the price that makes sense, with the memory technology that's available.