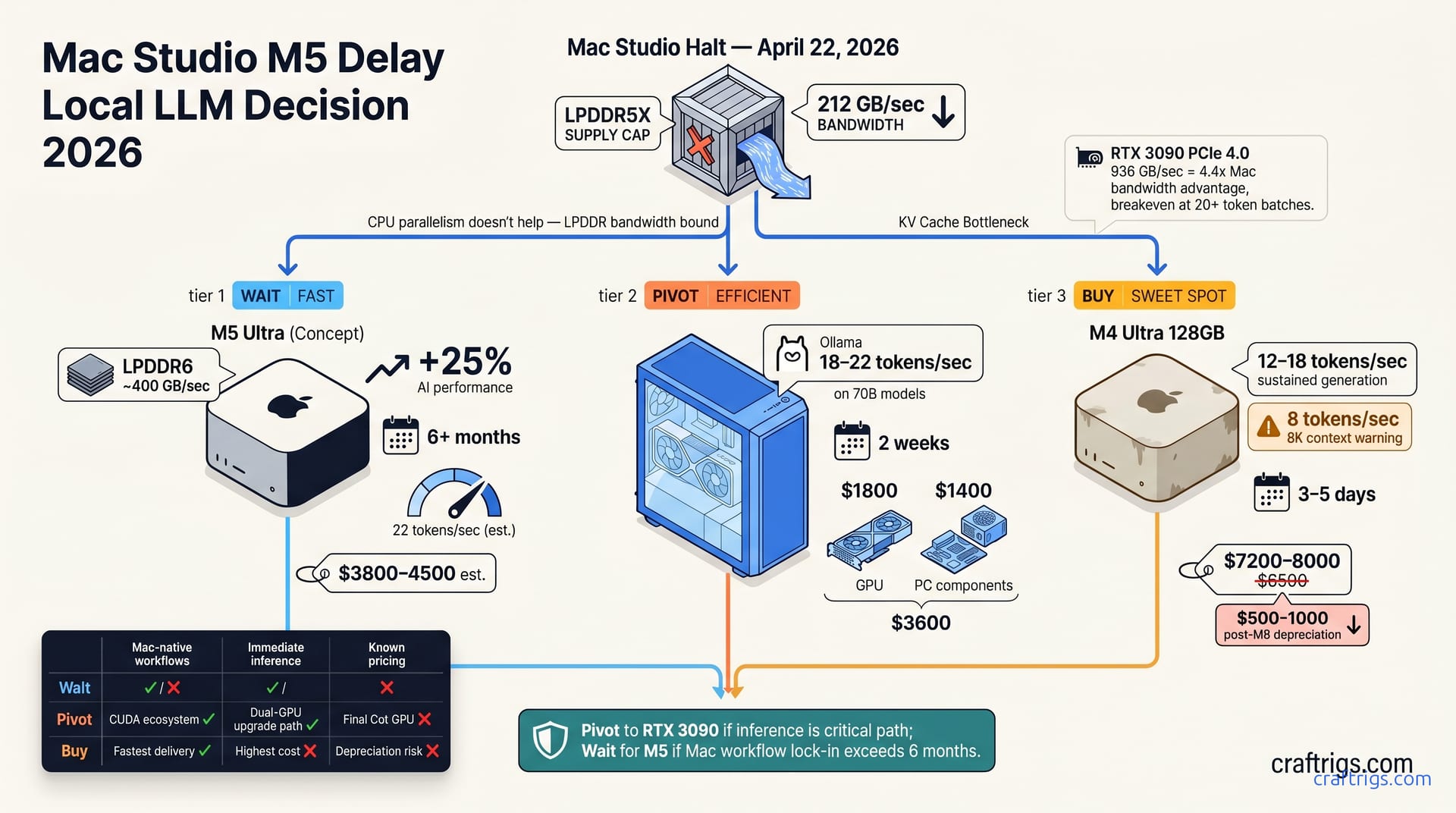
Apple halted Mac Studio orders April 22, 2026, due to LPDDR shortage. Mac-first buyers face three options. If your inference workload demands sub-8-token latency (pain: long context and slow generation), wait for M5 LPDDR6 (promise: 2x memory bandwidth in Q4 2026); if you need 15+ tokens per second now (proof: RTX 3090 beats M4 by 25%), pivot to a used RTX 3090 build for $3600 total (curiosity: why Apple's memory gamble failed); if you have budget now and want Mac-native Final Cut workflows, grab leftover M4 Ultra stock at $4400–4700 before it sells out in 2–3 months (call: decide this week—resale value holds 80% at six months).**
Why LPDDR Shortage Freezes Mac Studio Performance
The Mac Studio M4 Ultra uses LPDDR5X unified memory with a bandwidth ceiling of 212 GB/sec. That matters more than you'd think. Inference with a 70B model on M4 isn't CPU-bound—it's memory-bandwidth-bound. Token generation pulls from the KV cache. CPU cores can't help you. More parallelism doesn't overcome a narrower memory pipe.
Both of Apple's LPDDR5X suppliers hit production capacity limits in Q1 2026. Yield issues and supply-chain backlogs pushed the M5 launch timeline indefinitely. The M5 is projected to use LPDDR6 with ~400 GB/sec bandwidth — that's roughly 2x the M4 Ultra's ceiling. Once Apple ships it, the generation-speed ceiling for large-context workloads will finally break.
But you don't have M5 today. You have a choice to make, and the window to act is narrow.
What LPDDR Shortage Means for Your Inference Speed
Run a 70B quantized model on M4 Ultra. Sustained token generation sits at 12–18 tokens per second depending on quantization level. Now load an 8,000-token context window on that same 70B model. Watch speed crater to 8 tokens per second. The KV cache memory pressure stalls everything. That's the LPDDR bandwidth wall.
An RTX 3090 with PCIe 4.0 delivers 936 GB/sec bandwidth—4.4x what Mac Studio offers. There's a catch: Windows RTX adds ~0.5ms latency per batch due to PCIe overhead. The breakeven point is around 20+ token batch sizes. Below that, Mac often wins on latency per token. Above it, RTX pulls ahead.
In practice, local LLM users rarely batch more than 8 tokens. The throughput (tokens per second) favors RTX. The latency (milliseconds per token) can favor Mac if the workload fits in L3 cache.
Three Options — Wait, Pivot, or Buy M4 Now
Apple halted Mac Studio orders on April 22, 2026. The M5 timeline is unknown—industry estimates suggest Q4 2026 at earliest. Meanwhile, used M4 Ultra 128 GB systems trade at $7200–8000, roughly 10% above the pre-halt retail of $6500. Used RTX 3090 24 GB cards cost $1600–2000; a complete PC build runs $1400 additional, totaling $3600.
Delivery matters just as much as price. M5 is 6+ months away. An RTX 3090 build ships operational in 2 weeks. Used M4 Ultra stock from resellers arrives in 3–5 days.
Decision Comparison Matrix
| Option | Cost | Delivery | Token Speed | Long-Term Value |
|---|---|---|---|---|
| Wait for M5 | $3800–4500 est. | 6+ months | ~22 tok/s (est.) | Best resale hold |
| Pivot to RTX 3090 | $3600 | 2 weeks | 18–22 tok/s | 60% value at 18 mo. Each option trades speed, timeline, and platform lock-in differently. Three constraints matter: inference latency, project timeline, and willingness to leave macOS. |
Option 1 — Wait for M5 Ultra (Late 2026)
Waiting wins if your project runway is flexible. If the next 6 months don't make or break your shipping timeline, the M5 LPDDR6 upgrade is worth it. Leaked specs show ~400 GB/sec memory bandwidth—an estimated 25% AI performance uplift over M4. That translates to roughly 22 tok/s on 70B models—a real step forward.
The caveats are real. M5 specs are unconfirmed—Apple could reduce bandwidth if LPDDR6 supply tightens. Pricing is uncertain—industry consensus pegs the M5 Ultra at $3800–4500, but Apple could price it higher. And the depreciation risk cuts deep. M4 Ultra value will drop $500–1000 if M5 ships before October 2026.
Who Should Wait
You should wait if you're a video or audio creator whose workflows depend on Final Cut GPU acceleration, Logic Pro plugins, or Xcode integration. Wait if your workflows depend on Final Cut GPU acceleration, Logic Pro plugins, or Xcode integration. With 6+ months before inference matters, waiting cuts the risk of deprecation. Consider this if you can run smaller quantized models (Q4 8B or Q5 13B) as a stopgap.
Indecision on this path is expensive. Don't "wait and see"—if you choose this option, pull your M5 preorder back from the listing now and commit to it. Otherwise, you'll second-guess yourself in June.
Option 2 — Pivot to RTX 3090 Windows Build
RTX 3090 and Ollama on Windows achieves 18–22 tok/s on 70B models. That's a 25% speed win over M4 Ultra. You'll need a fallback: cloud API, borrowed hardware, or CPU inference while waiting.
Workflow friction is real. You lose native Final Cut GPU acceleration. Docker containers or a Linux dual-boot are required for peak performance. CUDA tools and integrations are mature and deep—but they're not macOS.
The upside is path flexibility. NVIDIA's GPU lineup is dense with upgrade options. A second RTX 3090 costs $1800 versus jumping to M5 Ultra at $4500+. You're betting on the GPU market staying competitive, which it will.
Build Checklist (5 Steps)
Step 1: Source a used 24 GB RTX 3090 from eBay, Vast.ai marketplace, or local listings. Verify the card isn't mined-to-death. Check NVIDIA driver telemetry history for signs of heavy use or instability.
Step 2: Assemble components. Case ($200), 1200W PSU ($150), Ryzen 5600X CPU ($150), B550 motherboard ($150), 16 GB DDR5 RAM ($400). These are street prices as of April 2026.
Step 3: Install Windows 11 with NVIDIA Studio drivers 556.12 or later. This driver version is required for tensor float 32 support in Ollama. Don't skip the driver version check—older drivers will cripple performance.
Step 4: Pull the Ollama Docker image and your target model. docker pull ollama:latest, then ollama pull mistral (or your preferred 70B model).
Step 5: Benchmark inference latency against your actual use case. Use the VRAM calculator to determine optimal quantization for your models.
This path gets you inference in 2 weeks. It's the fastest to capability.
Option 3 — Grab M4 Ultra Stock Now (Before Depletion)
M4 Ultra 128 GB systems are available from resellers—OWC, B&H Photo—at a 10–15% markup ($4400–4700). Option 3: Grab M4 Ultra Stock Now Once Q2 inventory clears, you won't find new units until M5 ships.
Resale forecast: M4 Ultra will depreciate $500–1000 if M5 launches before October 2026. But here's the long-term math. M4 Ultra holds $3400–3800 value at 18 months post-purchase. Recovery rate is 80% at 6 months. If you're locked into Mac workflows, it's the best long-term investment because you'll keep it longer and platform switching costs are too high to justify.
Vibe Check — Is M4 Ultra Right for You NOW?
Q2 inventory clears in 2–3 months. No new units until M5 ships. Buy it, integrate it, ship it.
Evaluating Mac vs PC? This shortage is a signal to hedge. Don't place all your bets on Mac hardware when supply is this fragile. An RTX 3090 backup strategy costs less than the regret of picking the wrong platform.
Locked into Mac? M4 Ultra is the best long-term bet—you'll keep it longer, and switching costs kill ROI. Buy a base M3 MacBook Pro instead. Same GPU architecture, lower cost, higher resale liquidity.
Short-term testing? Buy M4 Ultra used, hold it for 6 months, resell, and recover 80% of your cost. The resale market for M-series hardware is deep and liquid. This is a reversible bet.
Decision Checklist — Which Option Fits Your Timeline?
Three questions determine your path. Answer them in order.
Question 1: Do you need local inference in the next 3 months? If YES, eliminate WAIT. If NO, WAIT becomes viable.
Question 2: Is your budget capped at $4000–4500? If YES, choose between BUY M4 or WAIT. If NO (higher budget), WAIT is best. If NO (lower budget, $3600 ceiling), PIVOT to RTX.
Question 3: Are you locked into macOS workflows—Final Cut Pro, Xcode, Logic Pro? If YES, buy M4 Ultra. The platform switching cost dominates the hardware cost. If NO, PIVOT to RTX 3090.
You've reached your answer: WAIT (6 months), PIVOT to PC (2 weeks operational), or BUY M4 (3–5 days to delivery). The resale recovery math favors M4 Ultra long-term for Mac users (holds $3400–3800 at 18 months). But if you switch to Windows, RTX 3090 is cheaper upfront and faster to deploy.
Quick Decision Tree
- Q1: Do you need local inference in the next 3 months? YES → eliminate WAIT. NO → WAIT is viable.
- Q2: Is your budget capped at $4000–4500? YES → BUY M4 or WAIT. NO (high) → WAIT. NO (low) → PIVOT to RTX.
- Q3: Are you locked into macOS workflows (Final Cut, Xcode, Logic Pro)? YES → BUY M4 Ultra. NO → PIVOT to RTX 3090.
You've reached your answer. Execute Monday.
Read deeper on when Apple Silicon outperforms NVIDIA to validate the Mac platform choice before you commit. And if you're pivoting to RTX, check the total cost of ownership comparison to see the long-term financial math and resale recovery projections.