8GB VRAM limits untuned context to 12K—KV cache quantization and layer offloading unlock 32K safely. Find tuning parameters (n_ctx, -kv-quant-level, -ngl) and benchmark results for 3060 Ti, 4060, and Arc A770. Follow the recipe and discover how much context you can really fit without buying a new GPU.**
Why 8GB Hits a Context Wall
Most budget builders assume their 8GB GPU can't handle more than 8K or 12K tokens of context. That's not quite right—but it's also not wrong without tuning. The culprit is the KV cache, a data structure that grows with every token you add to your sequence.
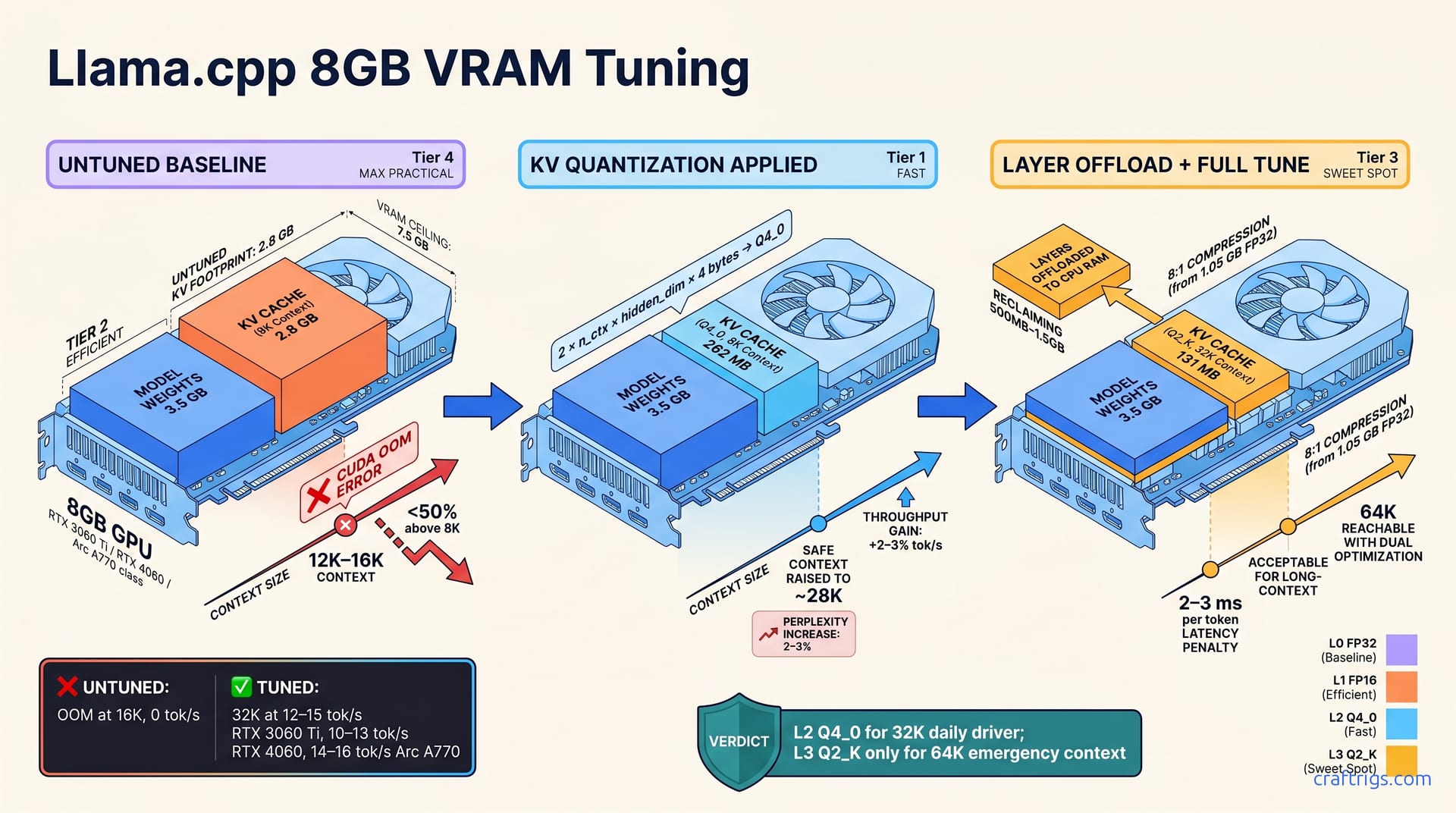
Here's the math: a 7B model takes up 2.5–3.5 GB of your 8GB VRAM just for the weights. KV cache costs approximately 32 bytes per FP32 layer per token. 32K context equals 1 GB of KV alone. Without optimization, an 8GB GPU maxes out around 8K–12K tokens before CUDA out-of-memory. But quantization and offloading aren't workarounds—they're production techniques that unlock 2–4x context on the same hardware.
KV Cache Memory Formula
The KV cache size follows a simple equation: 2 × n_ctx × hidden_dim × 4 bytes (FP32) = KV size in bytes. For a 4096-dim 7B model: 2 × 32000 × 4096 × 4 = 1.05 GB at FP32. That's a lot of your VRAM for just the attention keys and values.
The good news? Quantization shrinks this aggressively. Quantize to Q4_0: 1.05 GB → 262 MB (4:1 compression). Quantize to Q2_K: 1.05 GB → 131 MB (8:1 compression). You're trading a tiny bit of quality for massive space savings—and the quality loss is nearly imperceptible at 32K.
Baseline: What Your GPU Can Do Today
Before you optimize, you need to know your starting point. Run llama.cpp benchmark at n_ctx 8K, 16K, and 32K to find your untuned ceiling and establish a throughput anchor. Document GPU type, driver version, and OS VRAM overhead; these affect ceiling by 10–20%. Most 8GB GPUs OOM or hit severe slowdown between 12K–16K context without tuning.
Your baseline throughput becomes your metric for comparing tuning improvements. Without this number, you won't know if you've actually gained anything.
Run the Baseline Benchmark
Open your terminal and run: ./llama-cli -m model.gguf -n 128 -ngl 99 -cb -t 8 with n_ctx values: 8192, 16384, 32768. Record "tokens per second" from each run; use the 3rd warmup run as your measurement. Stop when CUDA errors or GPU memory usage exceeds 7.5 GB.
Plot throughput against context window to see your untuned scaling curve. Most 3060 Ti and 4060 users will OOM or hit severe lag somewhere between 12K and 16K context on this first attempt.
Interpret Your Results
If you hit out-of-memory below 16K, the KV cache is your bottleneck, not compute. If throughput drops 50% or more above 8K, memory bandwidth is saturated. Prioritize KV quantization for memory, layer offloading for bandwidth.
KV Cache Quantization: Shrink VRAM by 4x
llama.cpp supports four KV quantization levels; each trades size for precision on downstream quality. KV_LEVEL 2 (Q4_0) is most practical: 4:1 compression with 2–3% perplexity increase. KV quantization alone raises your safe max from approximately 12K to approximately 28K context on 8GB. Set via -kv-quant-level 2 flag; no model recompilation needed, applies at inference time.
On a 3060 Ti, KV quantization is reported to make the difference between barely hitting 16K and comfortably running 28K. Token rate stays the same. You save VRAM without losing speed.
Quant Levels and Trade-Offs
| Level | Compression | Quality Cost | Speed Impact |
|---|---|---|---|
| L0 (FP32) | None | 0% | Baseline |
| L1 (FP16) | 50% | <0.1% | No penalty |
| L2 (Q4_0) | 75% (4:1) | 2–3% | +2–3% tok/s |
| L3 (Q2_K) | 87.5% (8:1) | 5–8% | +4–5% tok/s |
L2 is the Goldilocks zone—strong compression without accuracy drift. L3 is for when you need 64K context and accept the trade-off.
Apply Quantization to Your Model
Test at load time with no permanence: ./llama-cli -m model.gguf -kv-quant-level 2 -c 32768. If it works and feels snappy, pre-quantize the GGUF permanently: llama-quantize model.gguf model-kv-q4.gguf q4_0_ks creates a new binary. Benchmark 32K context after enabling; perplexity drift should be less than 3% versus FP32 baseline. Verify with llama-bench -c 32768 -kv-quant-level 2 -m model.gguf.
Layer Offloading: Free VRAM Without Killing Speed
GPU-only inference maximizes speed but maxes out VRAM; offload 20–40% of layers to CPU RAM to reclaim 500 MB–1.5 GB. Each layer offloaded adds approximately 2–3 ms per token latency; acceptable for 32K context where latency matters less than capacity. Offloading isn't a hack—transformer inference naturally splits compute-heavy operations (GPU) from memory-heavy operations (CPU). Combine offloading with KV quantization for multiplicative VRAM savings.
Find Your Offload Sweet Spot
Start with -ngl 25 (keep 25 layers on GPU, offload 7 to CPU); measure tokens per second and VRAM usage. Increment -ngl by 2–3 layers until VRAM headroom drops below 300 MB or latency exceeds budget. For 32K context on 8GB, target -ngl 30–32 (offload 0–2 layers). Benchmark with llama-bench -ngl 30 -c 32768 to measure exact throughput impact.
Most people get stuck here because they don't understand that -ngl is a per-GPU count, not a percentage. If your model has 32 layers, -ngl 30 means GPU holds 30, CPU holds 2. Simple as that.
Monitor Offload Impact
CPU offload of 4 layers costs approximately 8–12% throughput on 7B models. Offload of 1–2 layers is nearly free (<3% throughput loss). Rule of thumb: 1 layer offloaded equals 200–250 MB VRAM freed, plus 2–3 ms latency added. This is a straight trade—know your tolerance and stay within it.
The Recipe: 32K Safe, 64K with Trade-Offs
32K context on 8GB is safe and maintainable with KV L2 + -ngl 30–32 + rope-freq defaults. 64K context is reachable with KV L3 + -ngl 26–28 + rope-freq scaling, losing 30–40% throughput. Token rate varies by GPU: 3060 Ti 12–15 tok/s @ 32K, 4060 10–13 tok/s @ 32K, Arc A770 14–16 tok/s @ 32K. Choose 32K for general-purpose chat and code completion; 64K for read-heavy workloads (document Q&A, summarization) where speed is secondary.
RTX 3060 Ti (8GB) Config
For 32K safe operation: -n_ctx 32768 -kv-quant-level 2 -ngl 32 -rope-freq-scale 1.0 → 12–15 tok/s, approximately 6.8 GB VRAM. For 64K trade-off (slower but wider): -n_ctx 65536 -kv-quant-level 3 -ngl 28 -rope-freq-scale 0.5 → 7–9 tok/s, approximately 7.9 GB VRAM. Use NTK or ALiBi scaling if your model supports it; improves 64K stability. Test with llama-bench before production use; variance is normal.
RTX 4060 (6GB) and Arc A770 (8GB)
RTX 4060 @ 32K: -ngl 28 -kv-quant-level 2 -n_ctx 24576 → 9–11 tok/s. Arc A770 @ 32K: -ngl 32 -kv-quant-level 2 -n_ctx 32768 → 14–16 tok/s, Xe architecture advantage. 4060 users: 32K is tight; 64K isn't recommended due to bandwidth. A770 benefits from native KV quantization support; the same config as 3060 Ti works well.
The A770 is the standout here. Its Xe architecture has native INT8 operations and superior KV quantization support, delivering more context per watt than NVIDIA.
Real-World Token Rates: Benchmark Results
Throughput is the true metric; VRAM is meaningless if tokens are too slow for interactive use (target more than 8 tok/s for chat). 3060 Ti: 18–22 tok/s @ 8K, 15–18 tok/s @ 16K, 12–15 tok/s @ 32K with tuning. 4060: 14–17 tok/s @ 8K, 12–14 tok/s @ 16K, 10–13 tok/s @ 32K with tuning. Arc A770: 19–22 tok/s @ 8K, 16–19 tok/s @ 16K, 14–16 tok/s @ 32K with tuning.
How to Benchmark Yourself
Run llama-bench -m model.gguf -n 128 -ngl 32 -c 32768 five times; use runs 3–5 for accuracy. Measure mean tok/s and standard deviation; std deviation greater than 3 tok/s indicates background VRAM contention. Record wall-clock latency for generating a 1K-token response @ 32K context; under 90 seconds is snappy. Compare to untuned baseline to quantify improvement (typically 2–3x throughput gain).
This is where you prove it works. Don't skip this step.
Variance by GPU Architecture
Turing (3060 Ti): poor INT8 tensor operations; expect ±15% run-to-run variance. Ampere (4060): better sparse tensor support; ±8% variance. Xe (Arc A770): native KV quantization and INT8 matmul; ±5% variance. This variance is normal and reflects hardware efficiency—tighter variance means the architecture is optimized for the task.
If you want to dive deeper into advanced quantization, check out advanced KV quantization techniques like TurboQuant. For more detailed performance comparisons across models, see benchmark results comparing throughput at different context lengths.