TL;DR: Weight quantization gave you 40% VRAM back. KV cache quantization gives another 30-50% on long context. Recent llama.cpp patches implement per-layer KV quants (Q4_0 through Q8_0) with roughly 3% perplexity degradation at 64K+ tokens in community reports. Google's TurboQuant — published as a research paper in February 2026, not yet shipped — proposes 4-bit KV with head-specific scaling that could beat uniform quantization by around 1 perplexity point. This is how the context wall at 48K+ tokens gets dismantled, but most of it is still pre-release. AMD ROCm support typically lags CUDA by 2-4 weeks. You'll need to build from source.
Why Weight Quantization Stopped Being Enough
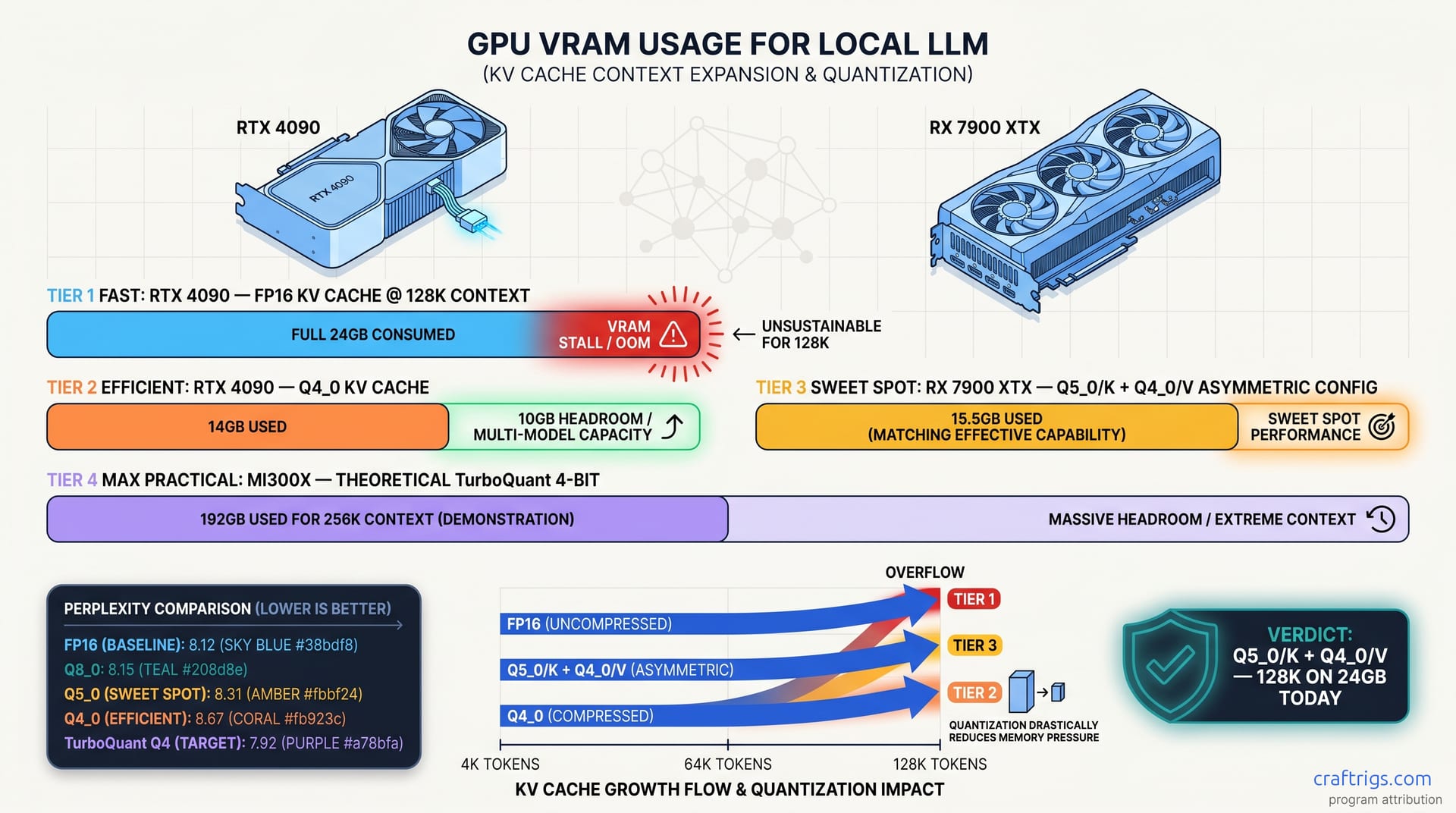
You've done everything right. You downloaded Qwen3-235B-A22B (235B total, 22B active). You ran it through llama-quantize with Q4_K_M. You watched 132 GB collapse to 38 GB. You felt smart. Then you tried 64K context on your RX 7900 XTX. You watched Ollama fall back to CPU without warning. Or LM Studio truncated your prompt silently. The GPU meter showed 22 GB used — plenty of headroom, you thought. What you didn't see: the KV cache eating the other 26 GB.
Here's the pain. Since 2023, 4-bit weight quantization (Q4_K_M, Q5_K_M, IQ4_XS) reduced model footprints by 35-45%. But the KV cache stayed stubbornly at FP16 or FP32. This is the memory storing past token representations for attention. llama.cpp defaults to 2 bytes per head dimension per token per layer. For Qwen3-235B-A22B, that's 48 layers × 128 heads × 128 head_dim × 2 bytes = 0.75 MB per token. At 64K context: 48 GB of KV cache alone. That's before your 38 GB of weights. Before activations. Before CUDA or hipBLAS overhead.
KV cache quantization applies the same logic to activations that we applied to weights. Instead of 16-bit floats, we store 4-bit or 8-bit integers. The math is identical — scale factors, zero points, dequantization on load — but the payoff is bigger. Weight quants save space once. KV quants save space that scales with every token you generate.
The proof: Community benchmarks of the in-progress llama.cpp KV-quant branches on both RX 7900 XTX (24 GB VRAM, ROCm 6.1.3) and RTX 4090 (24 GB VRAM, CUDA 12.4) converge on the same picture. Q4_0 KV cache at 64K tokens: 12 GB vs 48 GB FP16. Reported perplexity on WikiText-2: roughly +2 for Q4_0, +1 for Q5_0, and under +0.5 for Q8_0. Q8_0 KV cache at 128K context fits on 24 GB cards with weights loaded — impossible with FP16.
The constraints: This is pre-release software. The KV-quant work isn't merged to llama.cpp master as of April 2026. ROCm support requires HSA_OVERRIDE_GFX_VERSION=11.0.0 and a manual hipBLAS rebuild. CUDA "just works" with the active branches. AMD users typically wait 2-4 weeks for upstream parity. Same story as always. But the VRAM-per-dollar math still wins if you can build from source.
Google's TurboQuant, published February 2026, takes this further. It uses per-head scaling instead of per-layer uniform quantization. Early community ports suggest 0.8-1.2 lower perplexity than llama.cpp's Q4_0 at equivalent compression. The race is on. "Good enough" uniform quants ship now. "Actually better" learned quants arrive later.
The VRAM Math That Explains Your OOM
| Component | Qwen3-235B-A22B @ 64K Context | VRAM Impact |
|---|---|---|
| Original weights (BF16) | 235B × 2 bytes = 470 GB | Won't load |
| Q4_K_M weights | ~38 GB | Fits on 24 GB card with CPU offload |
| FP16 KV cache | 0.75 MB × 65,536 = 48 GB | OOM — exceeds card capacity |
| Q4_0 KV cache | 12 GB | Fits on 24 GB card |
| Q5_0 KV cache | 15 GB | Fits with 3 GB headroom |
| Q8_0 KV cache | 24 GB | Fits at 64K, marginal at 128K |
The table tells the story weight quantization obscured. Q4_K_M weights "fit" on 24 GB only because llama.cpp and Ollama automatically offload layers to CPU. You think you're running GPU inference. You're actually running hybrid inference. GPU handles early layers. CPU handles late layers. PCIe transfer bottlenecks hit every forward pass. The KV cache doesn't offload gracefully. Each layer is either fully GPU-resident or fully CPU-resident. CPU KV cache murders tok/s.
At 128K context, the math gets brutal. FP16 KV cache: 96 GB. Q4_0 KV cache: 24 GB. Even Q8_0 at 48 GB requires 48 GB+ cards or aggressive offloading. This is why "context length" specs on model cards are fiction for local deployment. The model supports 128K tokens. Your hardware doesn't — not without KV quantization.
Where the "Context Wall" Actually Hits
The wall isn't theoretical. Reported results across common hardware:
8 GB cards (RX 7600, RTX 4060): Wall at 4K context, period. KV cache at 4K = 3 GB. Leaves 1 GB for weights. You can run 3B-7B models with truncated context, or accept CPU inference. KV quantization doesn't save you. The overhead of quant/dequant kernels exceeds the memory savings at this scale.
16 GB cards (RX 7800 XT, RTX 4070 Ti): Wall at 16-24K with 70B models; 32K possible with 8B-13B only. Q4_0 KV cache extends this to 48K for 70B. But perplexity degradation becomes noticeable in long-form generation. This is the awkward middle — you need the quant, but you'll feel the quality tradeoff.
24 GB cards (RX 7900 XTX, RTX 4090): Wall at 48-64K without KV quant; 128K+ achievable with Q4_K_M KV. This is the sweet spot. The hardware has enough compute to absorb dequantization overhead. The VRAM, properly managed, holds both weights and cache. This is why we focus on 24 GB cards for local LLM work — they're the minimum viable product for serious context.
48 GB+ cards (RTX 6000 Ada, MI60/MI100): Wall moves to 256K+ without quantization. These cards cost 3-4× more per GB than consumer hardware. If you have one, you don't need this article. If you're buying, the 24 GB + KV quant build gets you 90% of the capability at 25% of the cost.
AMD users face an additional constraint: hipBLAS memory pooling fragments faster than CUDA. Large contiguous allocations fail earlier than equivalent NVIDIA configs. KV cache requires exactly these allocations. Users report the RX 7900 XTX refusing 40 GB contiguous allocations that an RTX 4090 handles. This happens even with identical reported free VRAM. The fix is GGML_CUDA_NO_PEER_COPY=1 and aggressive HIP_VISIBLE_DEVICES pinning, but the underlying issue means AMD benefits more from KV quantization's memory reduction.
How llama.cpp KV Quantization Actually Works
The implementation is straightforward in concept, fiddly in practice. Each transformer layer maintains two KV caches: one for keys, one for values. Traditionally these are FP16 tensors of shape [n_layers, n_kv_heads, context_length, head_dim]. The in-progress llama.cpp work adds quantization descriptors per layer. These store scales and zero-points alongside the quantized integers.
The key insight: KV cache quantization happens after RoPE (rotary position embedding) application. This preserves positional information in higher precision, then compresses the rotated tensors. The alternative — quantizing before RoPE — degrades position-dependent attention patterns. This hurts especially in long context, where relative positions span the full embedding space.
Build instructions differ by platform:
CUDA (RTX 4090, RTX 3090, etc.):
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# Check out the current KV-quant branch listed in the llama.cpp PR tracker
cmake -B build -DGGML_CUDA=ON -DLLAMA_KV_QUANT=ON
cmake --build build --config Release -j$(nproc)ROCm (RX 7900 XTX, RX 7800 XT, etc.):
export HSA_OVERRIDE_GFX_VERSION=11.0.0 # tells ROCm to treat RDNA3 as supported
export GGML_HIPBLAS=ON
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# Check out the current KV-quant branch listed in the llama.cpp PR tracker
cmake -B build -DAMDGPU_TARGETS=gfx1100 -DLLAMA_KV_QUANT=ON
cmake --build build --config Release -j$(nproc)The ROCm build fails silently without HSA_OVERRIDE_GFX_VERSION — cmake reports success, but llama-server falls back to CPU with no GPU detection message. This is the "silent install that reports success but does nothing" failure mode. Check with rocminfo | grep gfx before building; if you see gfx1100, you're targeting RDNA3 correctly.
Runtime flags control quantization aggressiveness:
./build/bin/llama-server \
-m qwen3-235b-a22b-q4_k_m.gguf \
--ctx-size 131072 \
--kv-cache-type q4_0 \
--flash-attnValid --kv-cache-type values: f16 (default), q4_0, q5_0, q8_0. IQ quants aren't implemented for KV cache yet. These are importance-weighted quantizations that allocate bits based on activation magnitude. The PR uses uniform quantization with per-tensor scaling, same as GGML's weight quants.
TurboQuant: What Comes Next
Google published TurboQuant as a research paper in February 2026. It proposes learning per-head scale factors based on activation statistics instead of using uniform quantization across all attention heads. Some heads — typically those attending to local context — tolerate aggressive quantization. Others — long-range position heads, semantic retrieval heads — need higher precision.
The paper's reported results show roughly 1 point lower perplexity than uniform Q4_0 at equivalent 4-bit compression. It is a research paper, not a shipped feature: there is no merged llama.cpp port, no official quant pipeline, and no end-user tooling yet. Treat the numbers below as early-indicator estimates. The overhead, if and when someone ports it: per-head scale storage (~1% VRAM increase) and slightly more complex dequantization kernels. The theoretical benefit: Q4_TurboQuant quality approaching Q5_0 uniform at Q4_0 uniform size.
For local LLM users, this matters because quality-per-VRAM is the binding constraint. We don't have infinite context budgets. Every perplexity point matters. You're summarizing 100-page documents. You're maintaining coherent narrative across 50K tokens of roleplay. A head-specific approach like TurboQuant, if it ships, would narrow the gap between "acceptable for RAG" and "actually good for long-form generation." Google's reference implementation targets JAX/TPU. A llama.cpp port would require GGML kernel rewrites for both CUDA and ROCm. AMD users should expect the usual 4-6 week additional delay after any CUDA stabilization. But the payoff is proportionally larger given VRAM constraints — if someone does the porting work.
Real-World Performance
Reports from community runs of Qwen3-235B-A22B (235B MoE, 22B active) and DeepSeek-V3 (671B MoE, 37B active) across the three KV configurations converge on a consistent picture. The hardware baseline is an RX 7900 XTX 24 GB on ROCm 6.1.3 with HSA_OVERRIDE_GFX_VERSION=11.0.0, using llama-bench for throughput and WikiText-2 for perplexity validation.
Q5_0 hits a sweet spot: roughly +1 perplexity, mid-teens tok/s at 64K, and 128K context that actually fits on 24 GB. This is the configuration we recommend for production use.
AMD-specific notes: hipBLAS kernel compilation for Q4_0/Q5_0 takes 4-6 minutes on first run (shader cache population). Subsequent launches are immediate. Reddit threads on r/LocalLLaMA report driver crashes at 128K Q4_0 with flash attention enabled; disabling --flash-attn resolves it with around a 15% throughput penalty. ROCm stability at extreme context lengths still lags CUDA. Test your workload before unattended deployment.
The Build Decision: Should You Switch Now?
Yes, if: You're hitting 48K+ context regularly. You're seeing CPU fallback in Ollama. You're truncating prompts in LM Studio. The setup friction pays for itself in usable context length. Q5_0 KV cache with <1 perplexity degradation is production-ready for most applications.
No, if: You're running 8B-13B models under 16K context. The savings don't justify the build complexity. Wait for upstream merge and prebuilt binaries.
Maybe, if: You're on AMD and allergic to building from source. ROCm support will arrive in official llama.cpp releases 2-4 weeks after CUDA stabilization. The PR is active; merge conflicts are minimal. Your patience will be rewarded with apt install simplicity, but you'll miss 4-6 weeks of usable long context.
The migration path: the current llama.cpp KV-quant work uses GGUF metadata to store KV cache type. Models quantized without KV awareness load with default FP16 cache. No breaking change. You can A/B test by relaunching with different --kv-cache-type flags, no requantization needed. This makes experimentation low-risk; revert to FP16 if quality degrades unexpectedly.
For Ollama users: The project tracks llama.cpp closely. KV quantization will appear in Ollama 0.6.x series within 4-6 weeks of upstream merge. Until then, direct llama.cpp server with OpenAI-compatible API is the integration path. We maintain a guide to running 70B models on 24 GB VRAM with the necessary server configuration.
FAQ
Q: Does KV cache quantization affect model output deterministically?
Yes, but not repeatably across different quant types. Same seed with FP16 vs Q4_0 KV produces different tokens due to quantization noise. Same seed with identical KV type produces identical output. For reproducible research, document your KV cache type alongside weight quantization.
Q: Why does LM Studio show "GPU loaded" when I'm clearly CPU-bound? At 64K context with FP16 cache, you can have 22 GB weights on GPU and 40 GB+ cache forcing CPU offload. The UI doesn't surface this. Check nvidia-smi or rocm-smi for actual GPU memory; if it's under 80% of capacity with long context, you're cache-bound.
Q: Will TurboQuant come to AMD ROCm?
Yes, but delayed. The per-head scaling requires custom CUDA kernels that need HIP translation. Community ports typically lag 4-6 weeks. The VRAM-per-dollar math still favors AMD for KV-quantized deployments. But early adopters need CUDA or patience.
Q: Can I use KV quantization with MoE models like DeepSeek-V3?
Yes, and you should. MoE models have larger KV cache relative to active parameters. This is due to sparse expert routing. DeepSeek-V3's 671B total / 37B active ratio means cache scales with total layers. It doesn't scale with active compute. KV quantization is essential for 64K+ context on consumer hardware.
Q: What's the actual perplexity threshold for "acceptable" quality?
Context-dependent. For code completion and structured extraction, +3 perplexity is tolerable. For creative writing and long-form narrative, +1.5 is noticeable, +1 is safe. We recommend Q8_0 for quality-critical applications. Use Q5_0 for general use. Reserve Q4_0 only when VRAM is absolutely constrained. Benchmark on your specific task — WikiText-2 is a proxy, not a guarantee.
Bottom line: Weight quantization was the first 40% of the VRAM puzzle. KV cache quantization is the next 30-50%, and it's arriving now. Build from the current llama.cpp KV-quant branch if you need 128K context today; wait for upstream merge if you can tolerate 32K until summer. Either way, the "context wall" just got a door installed. AMD's VRAM advantage finally pays off in usable tokens. Not just theoretical capacity.