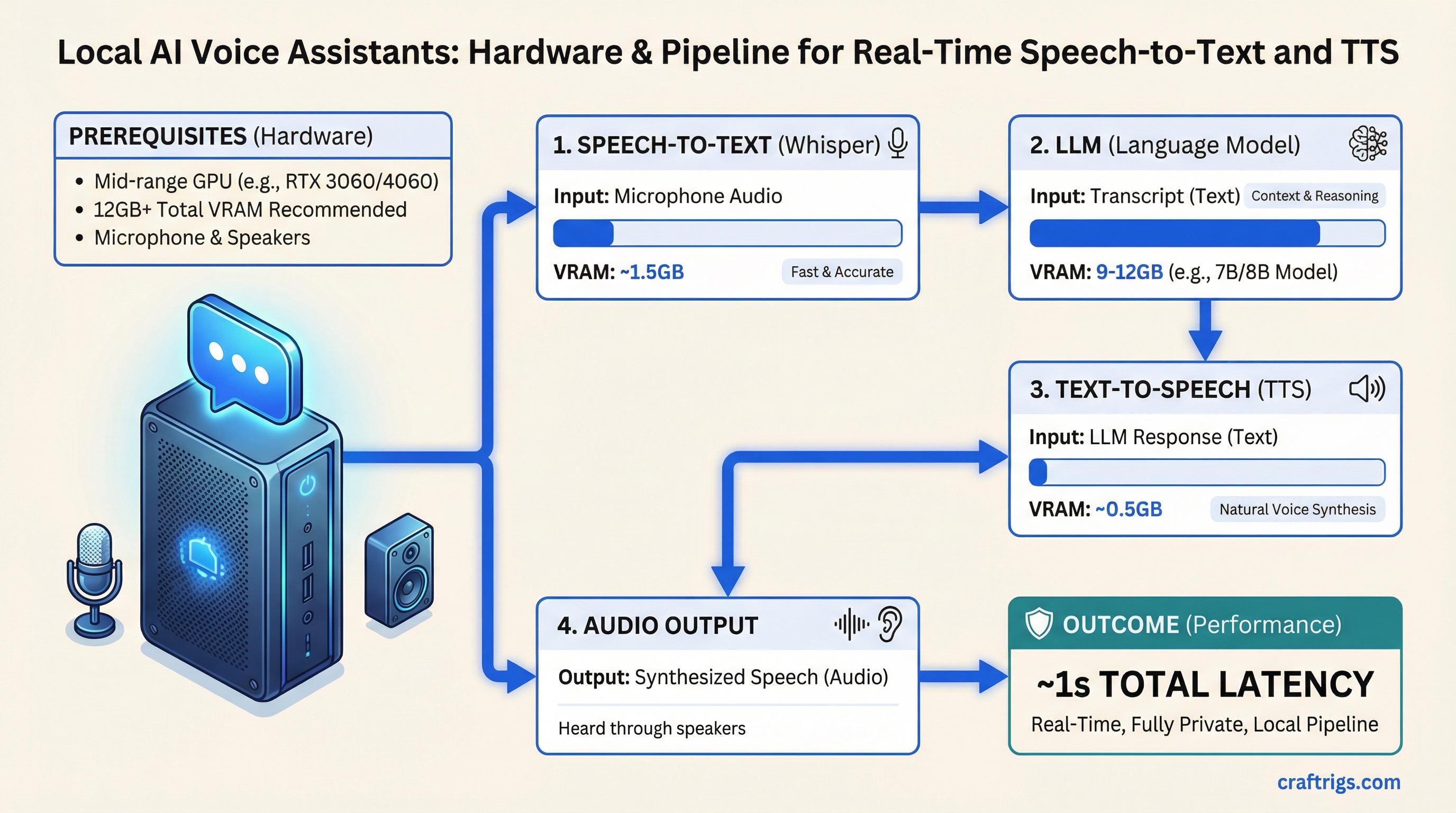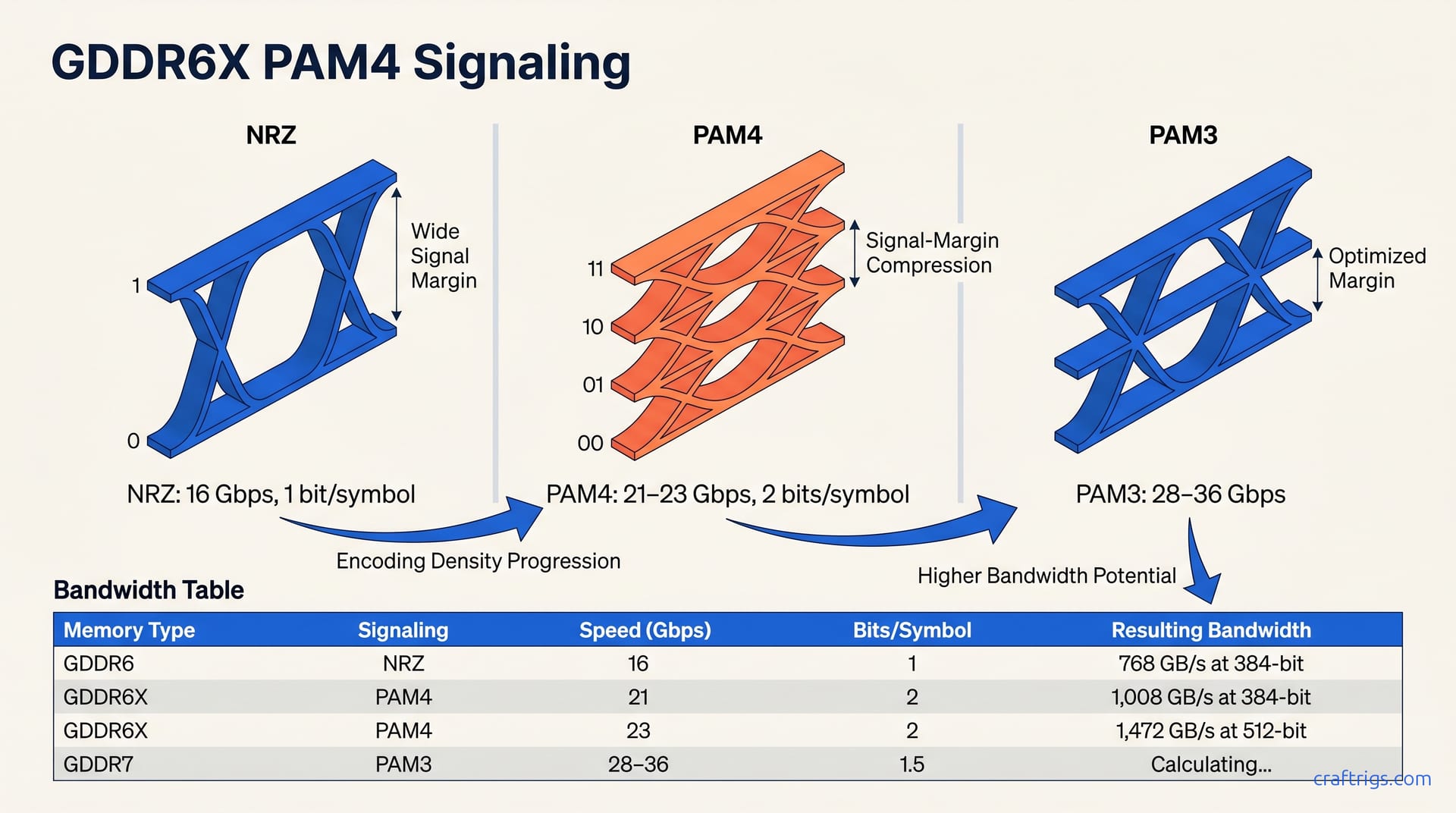
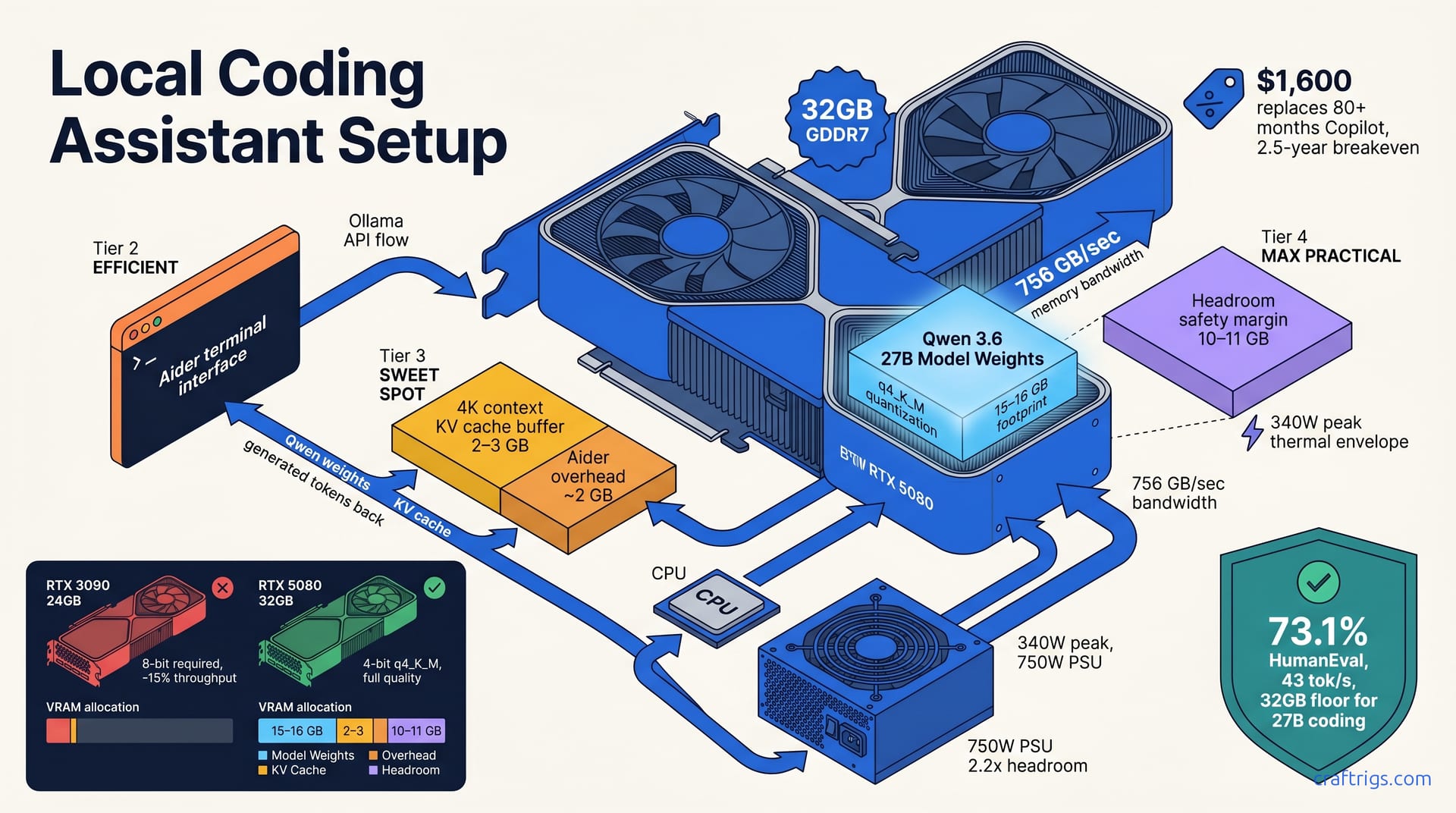
Article
Local Coding Assistant: Aider + Qwen 3.6 27B + RTX 5080
Build a private, offline coding assistant with Aider, Qwen 3.6 27B, and RTX 5080—40+ tokens/sec throughput, no subscription costs, honest gaps vs. Claude Code documented.
Apr 26, 2026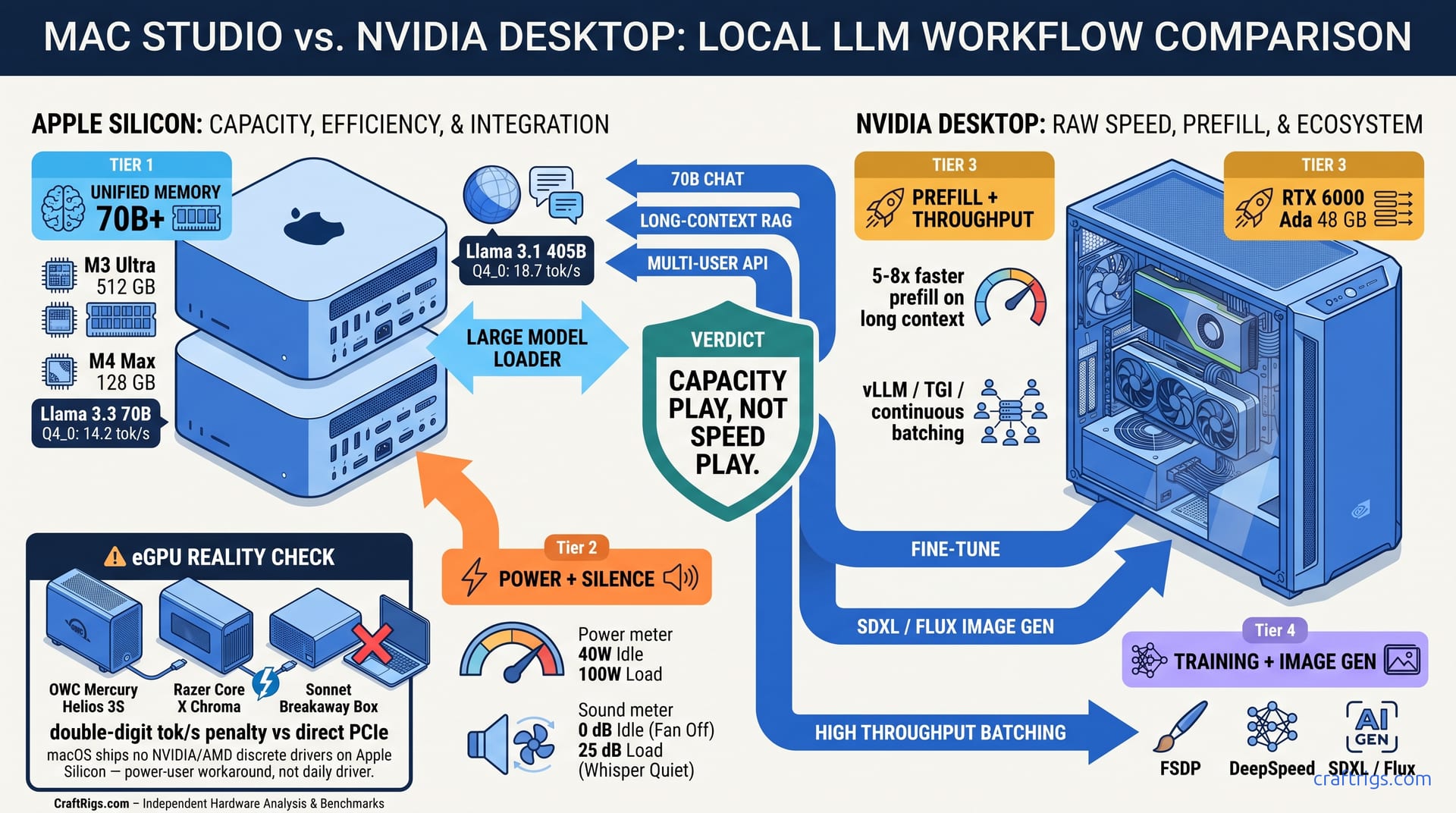


![$2,700 Local AI Desktop: 70B Models on a Real Budget [2026]](/images/auto-hero/2700-ai-desktop-case-study-local-llm.jpg)
![AMD Radeon AI PRO R9700 32GB Review: RDNA4 for Local AI [2026]](/images/auto-hero/amd-radeon-ai-pro-r9700-32gb-review-local-llm.jpg)
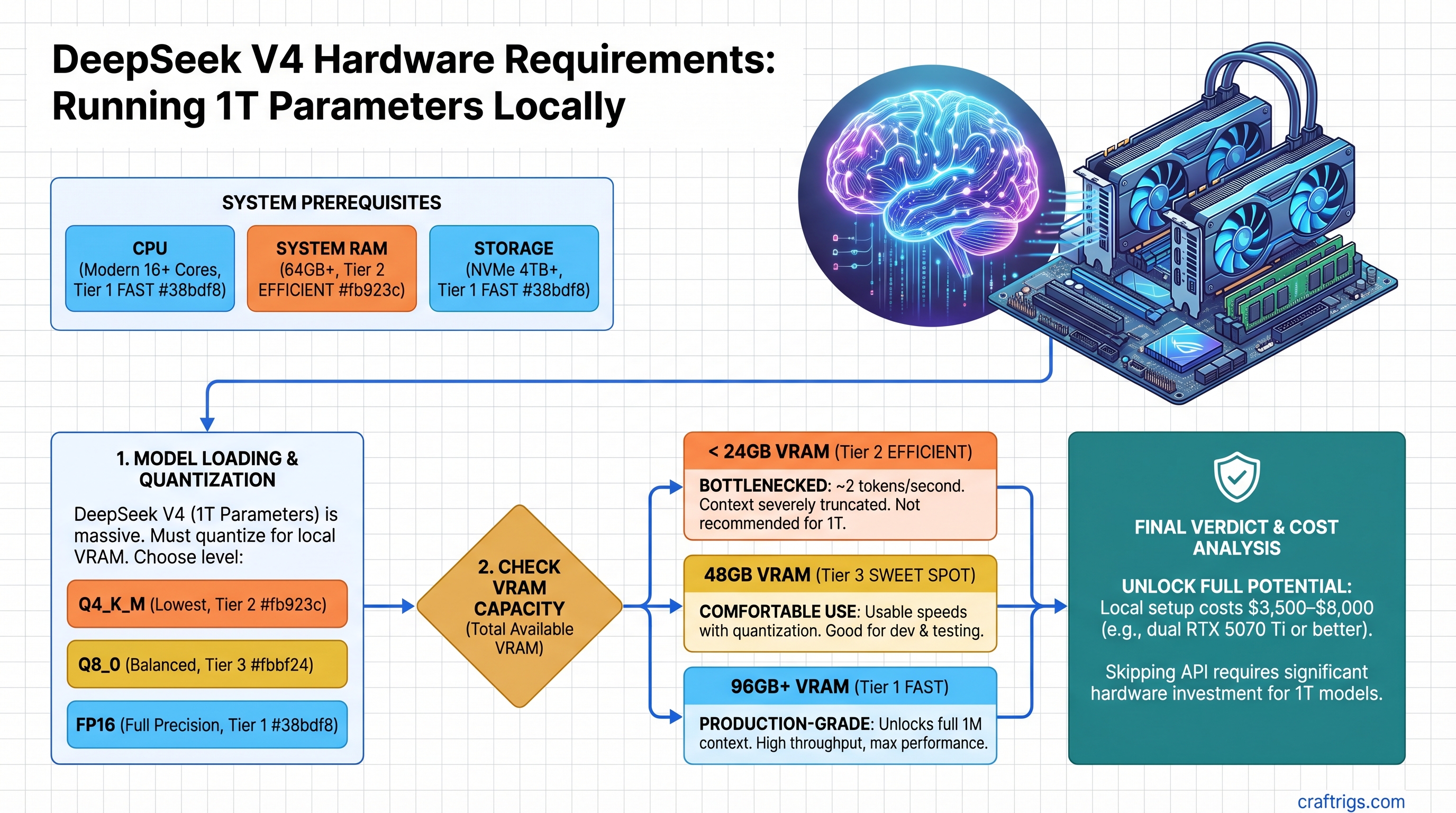
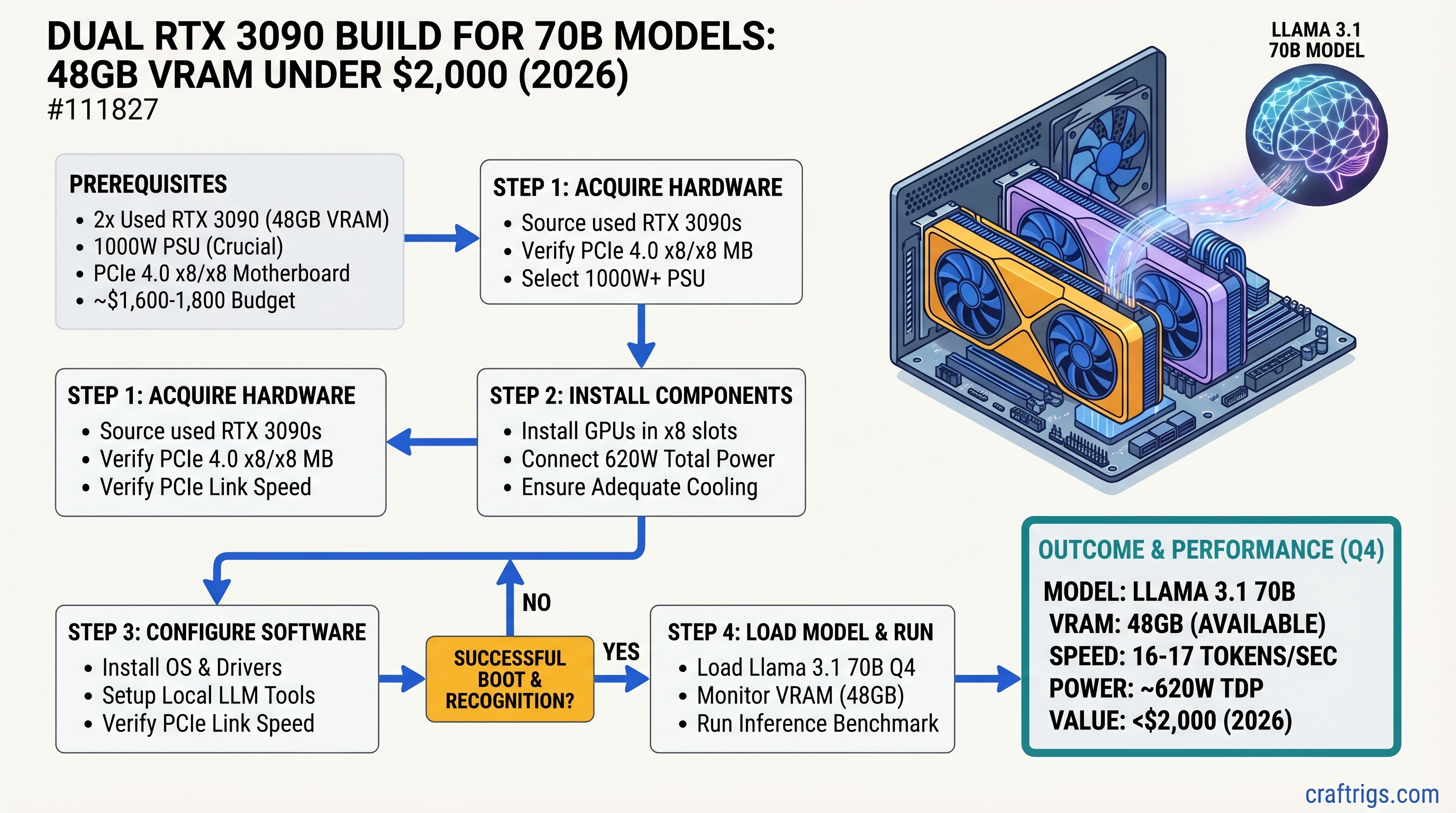
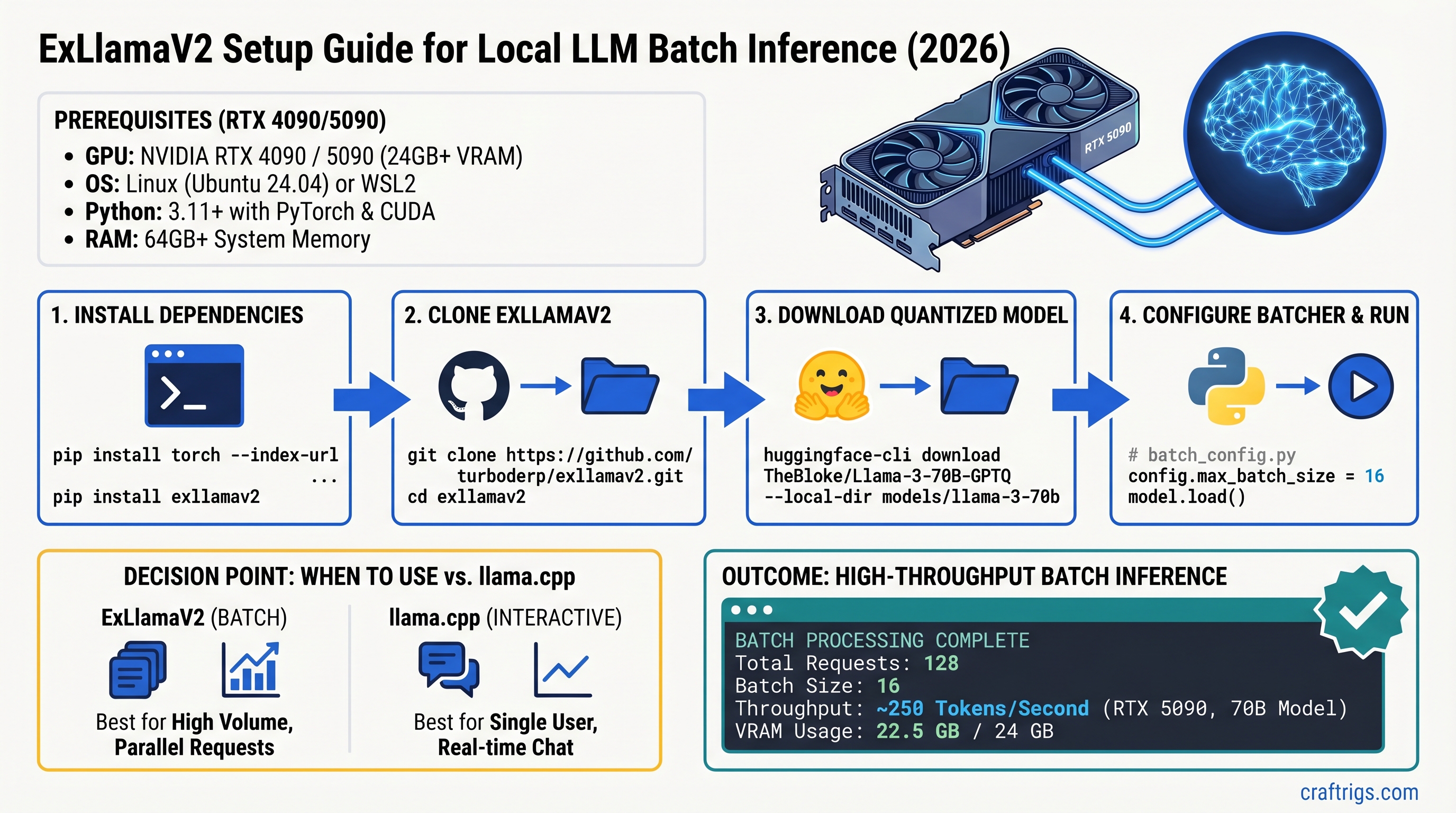
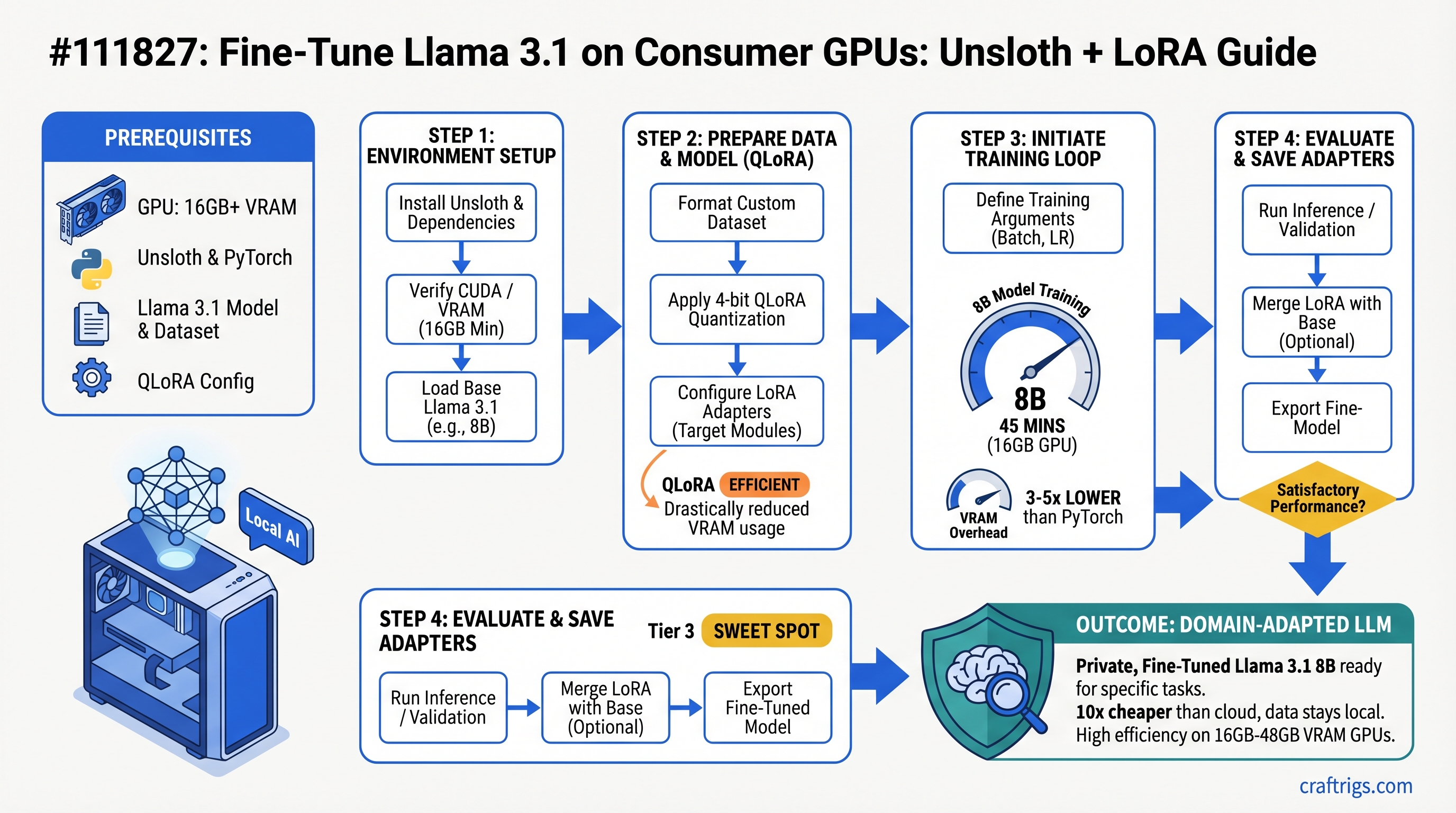
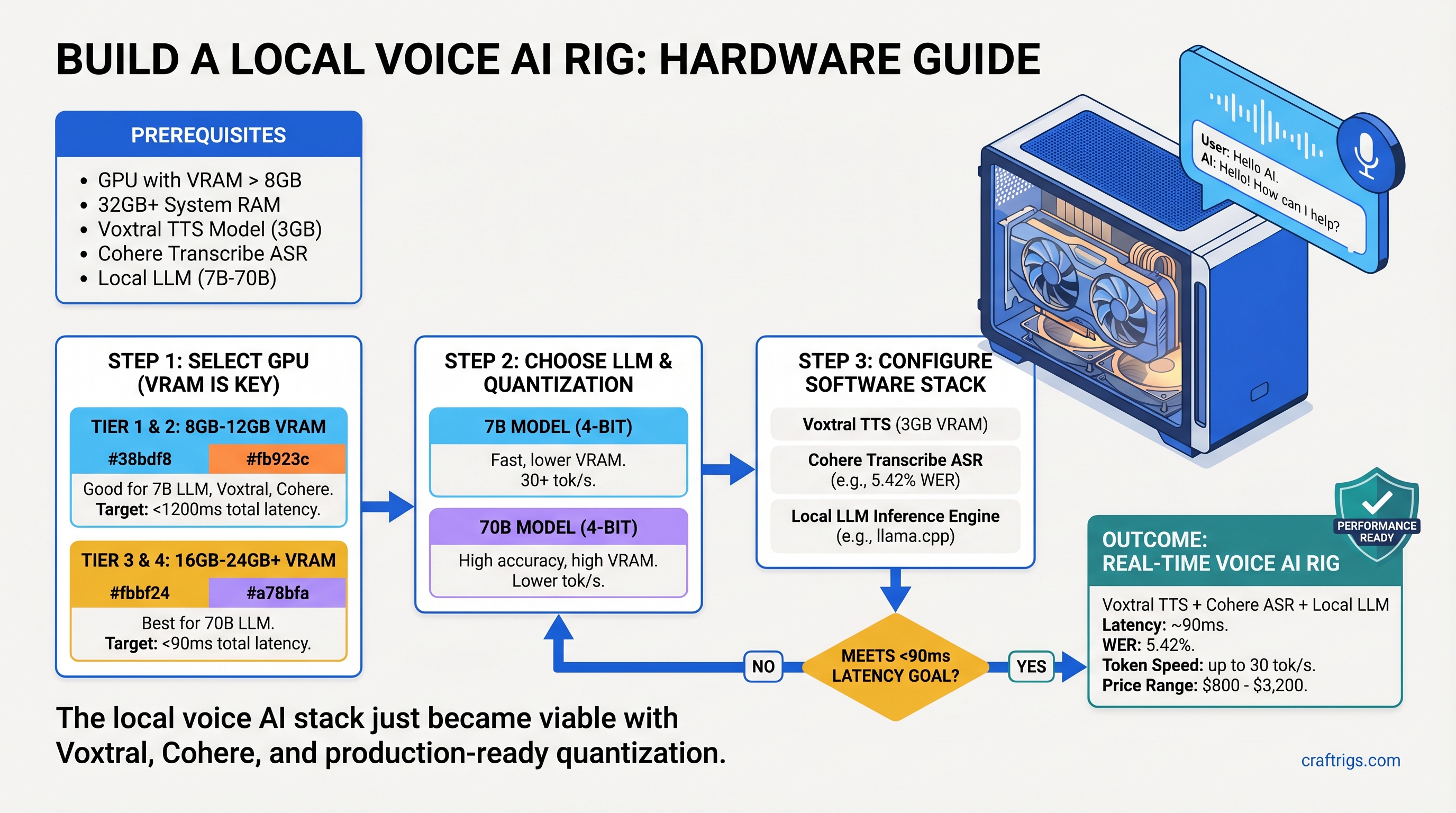
![Mac Studio M4 Max: Q4 Quantized 70B Models at 15–22 Tokens/Second [2026 Tested] — guide diagram](/images/mac-studio-m4-max-128gb-local-llm-what-runs/mac-studio-m4-max-128gb-local-llm-what-runs-diagram.jpg)
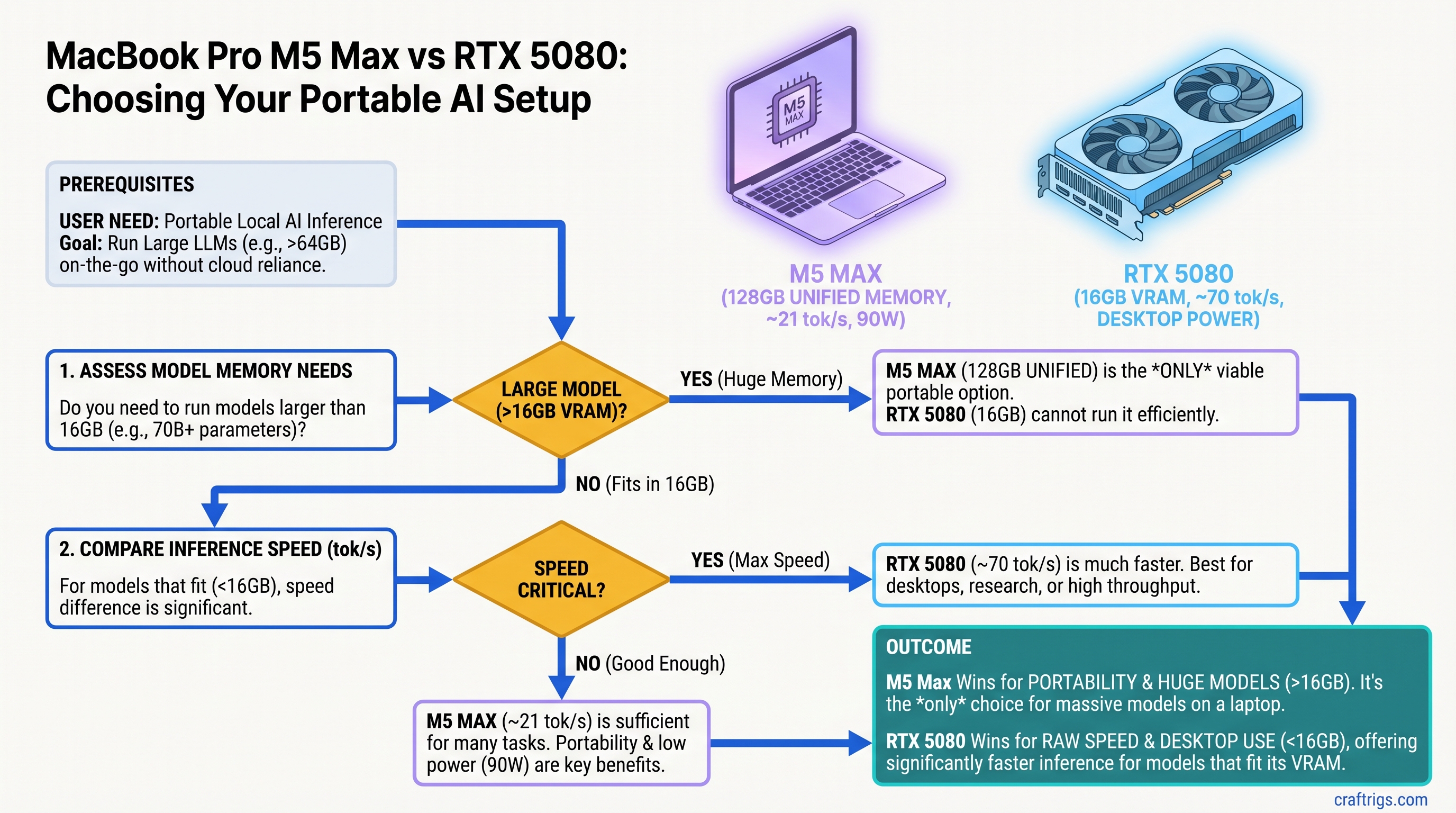

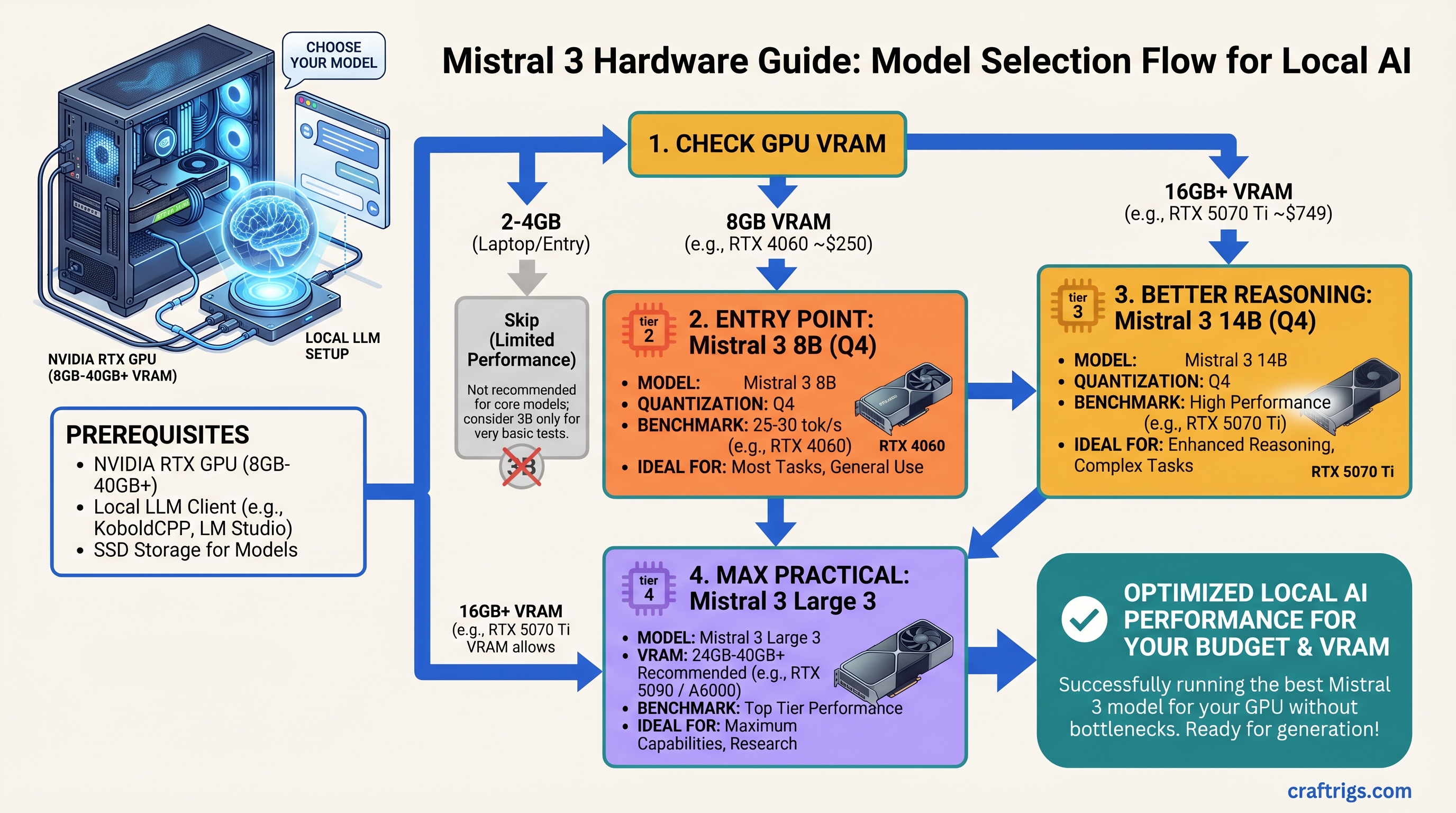
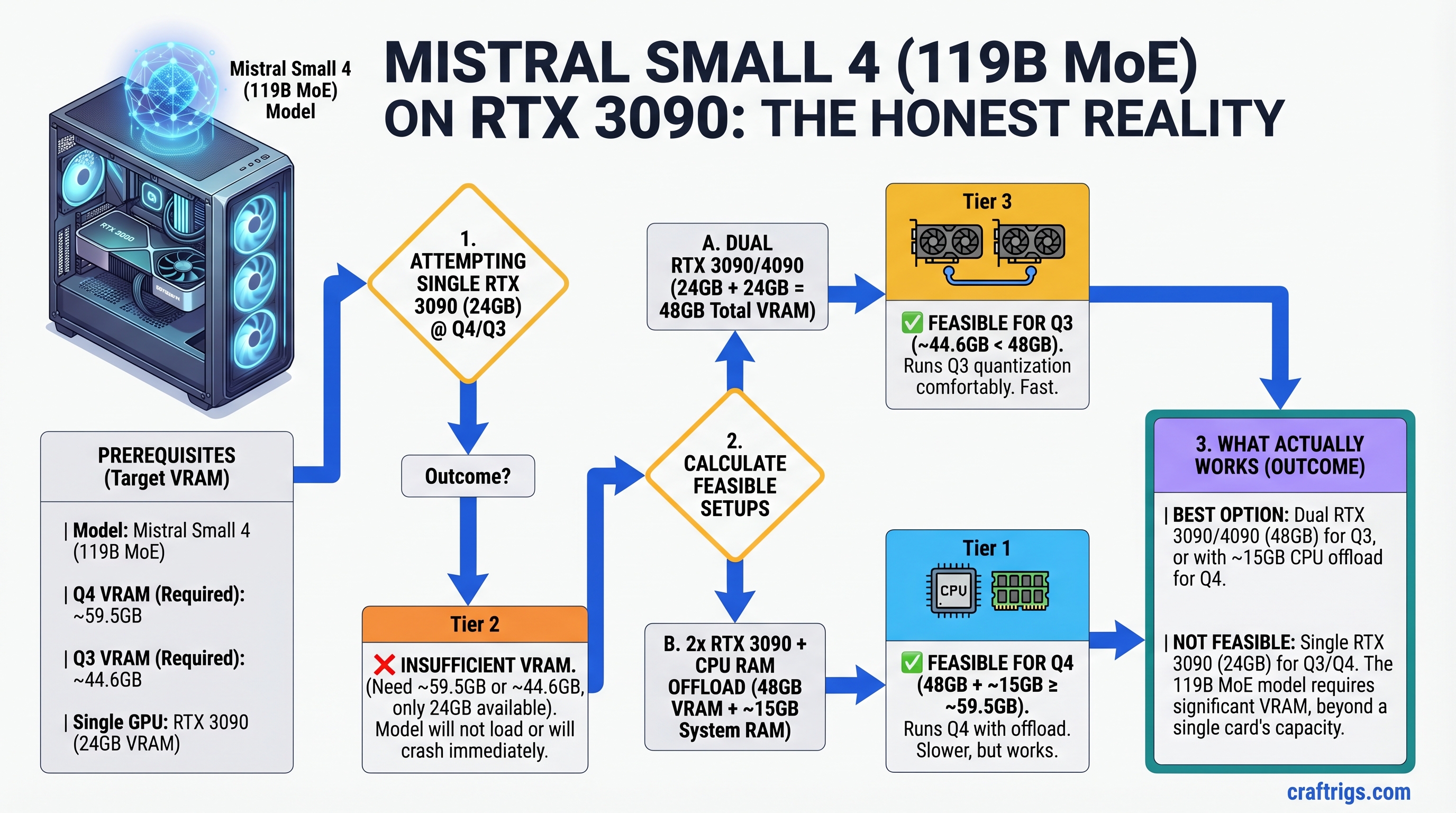

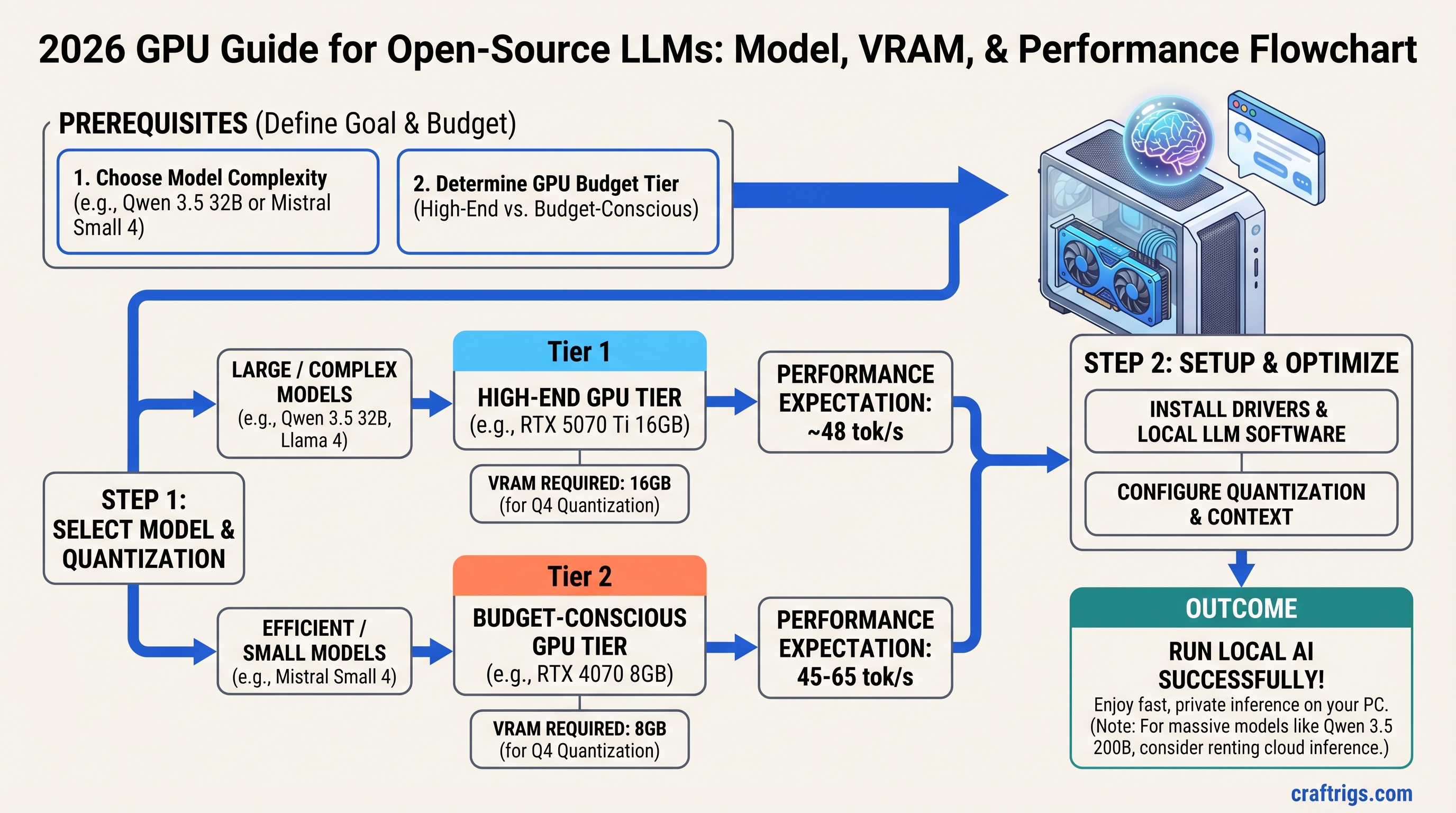
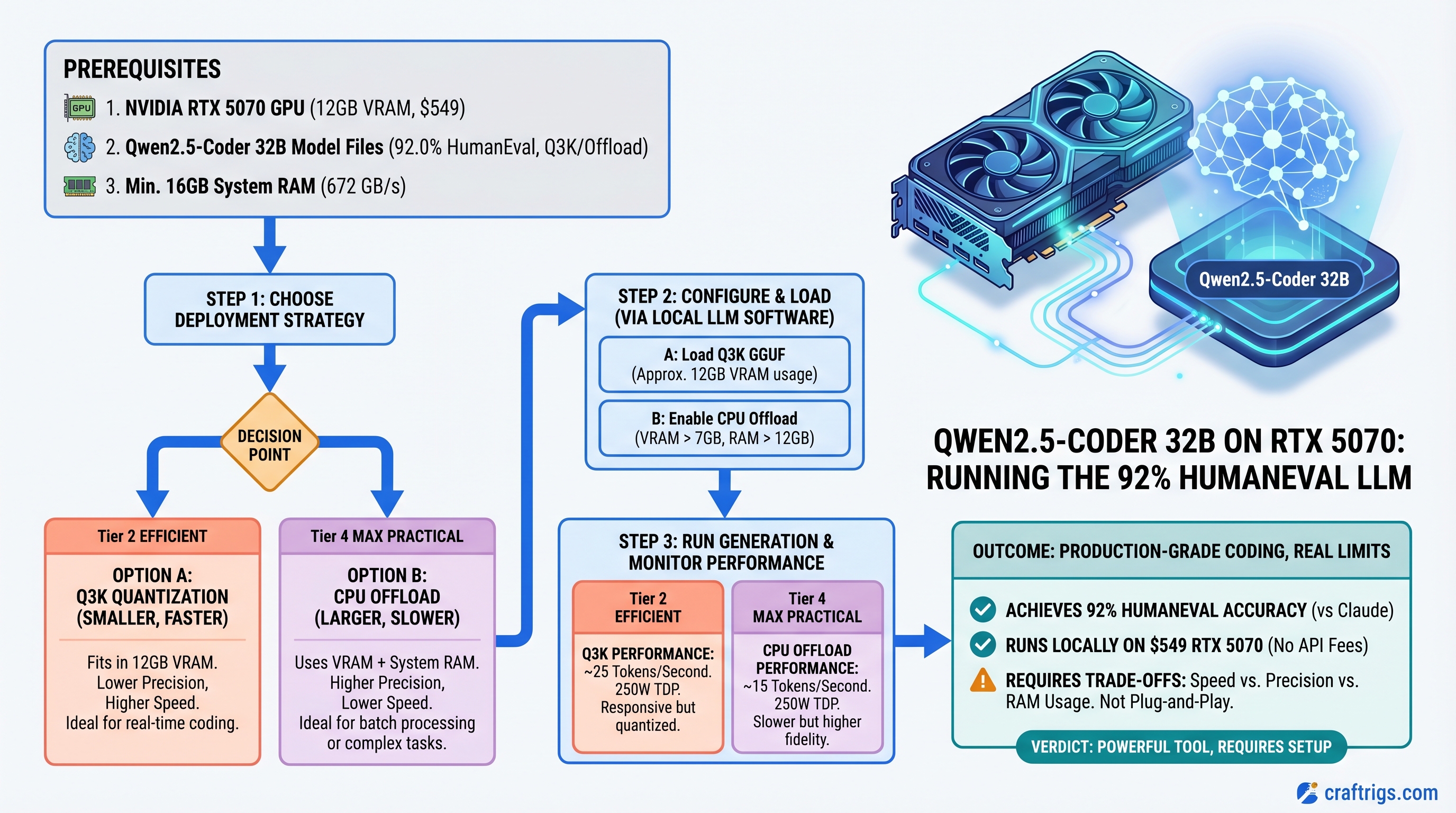
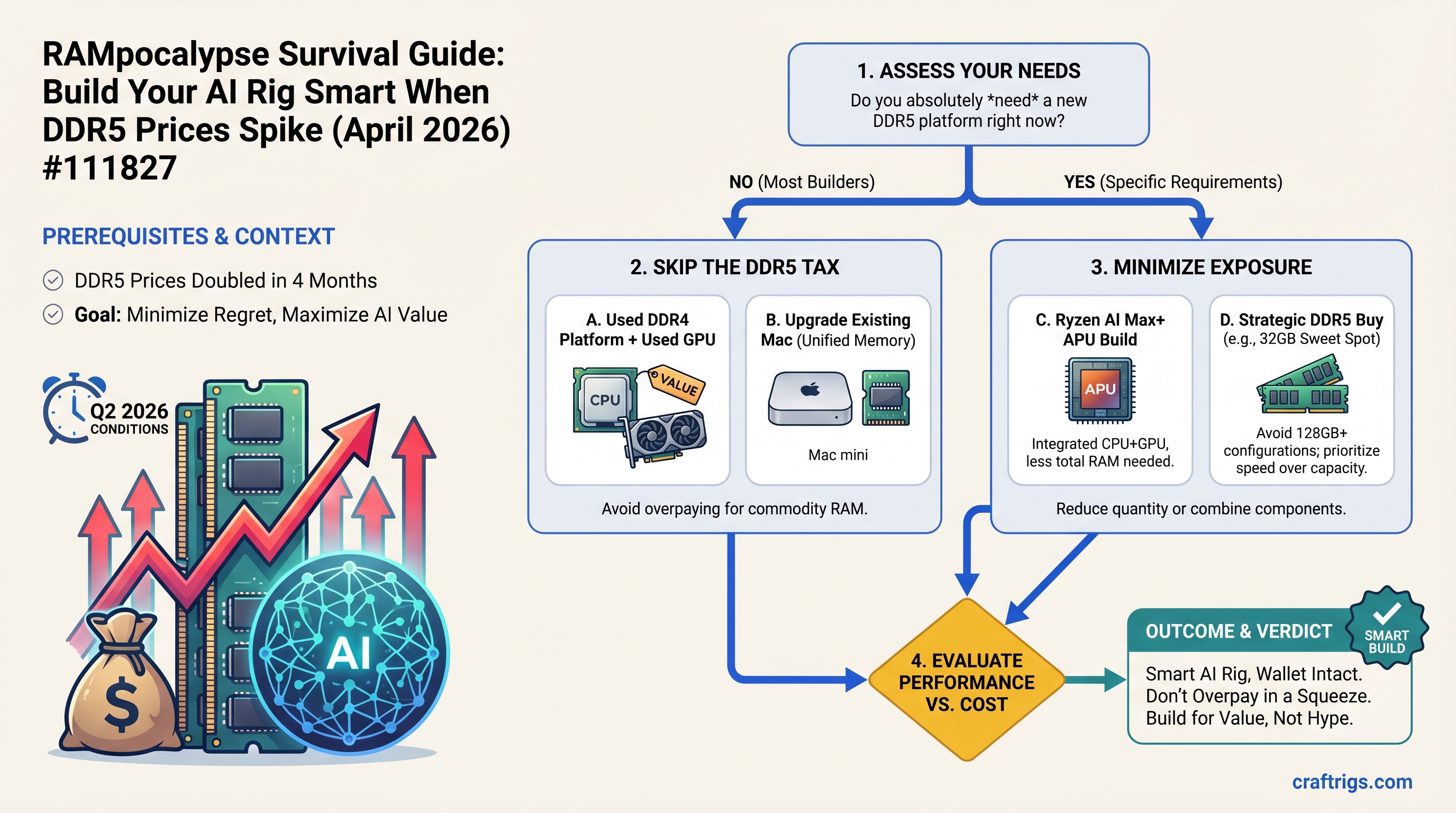
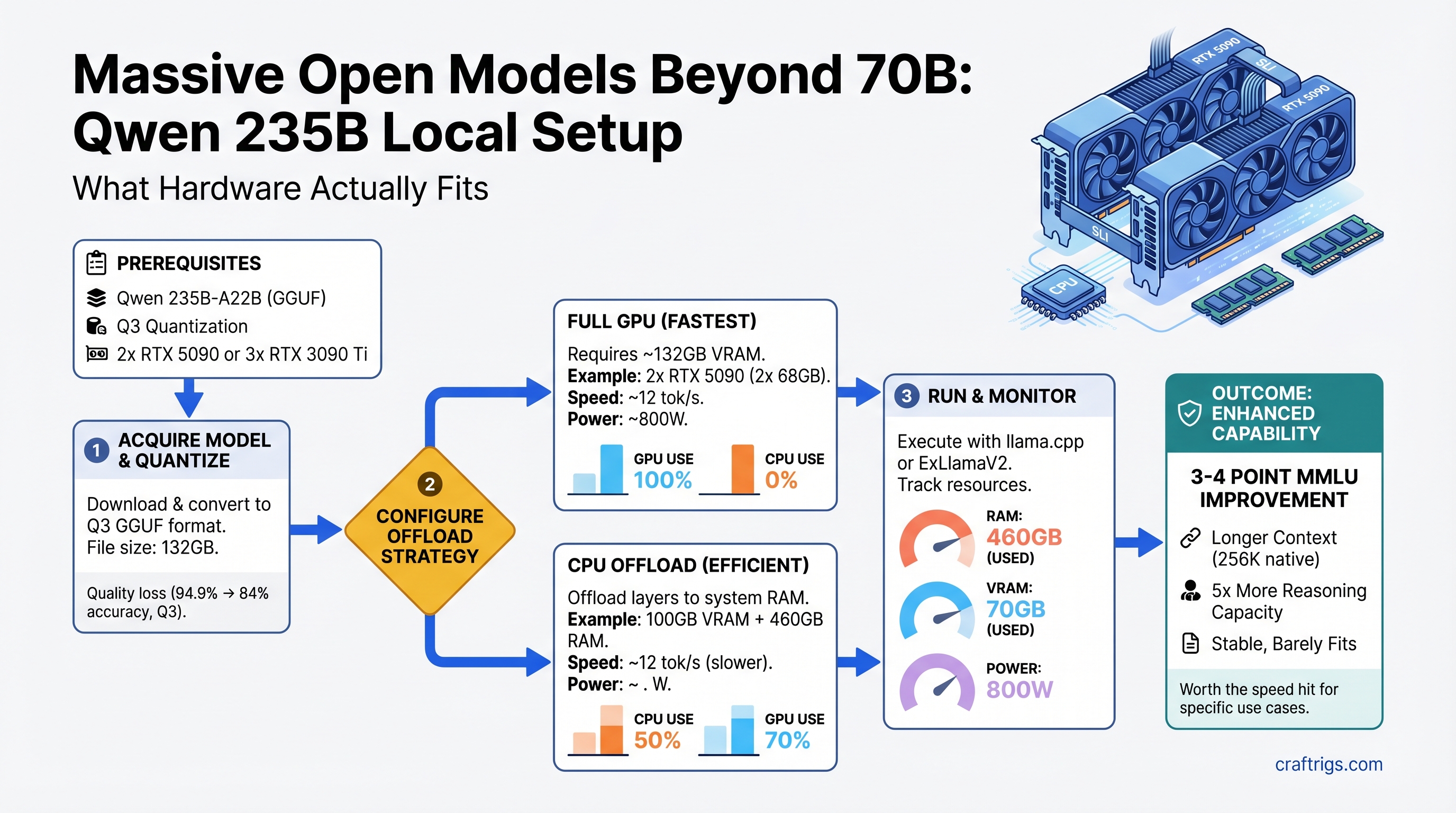
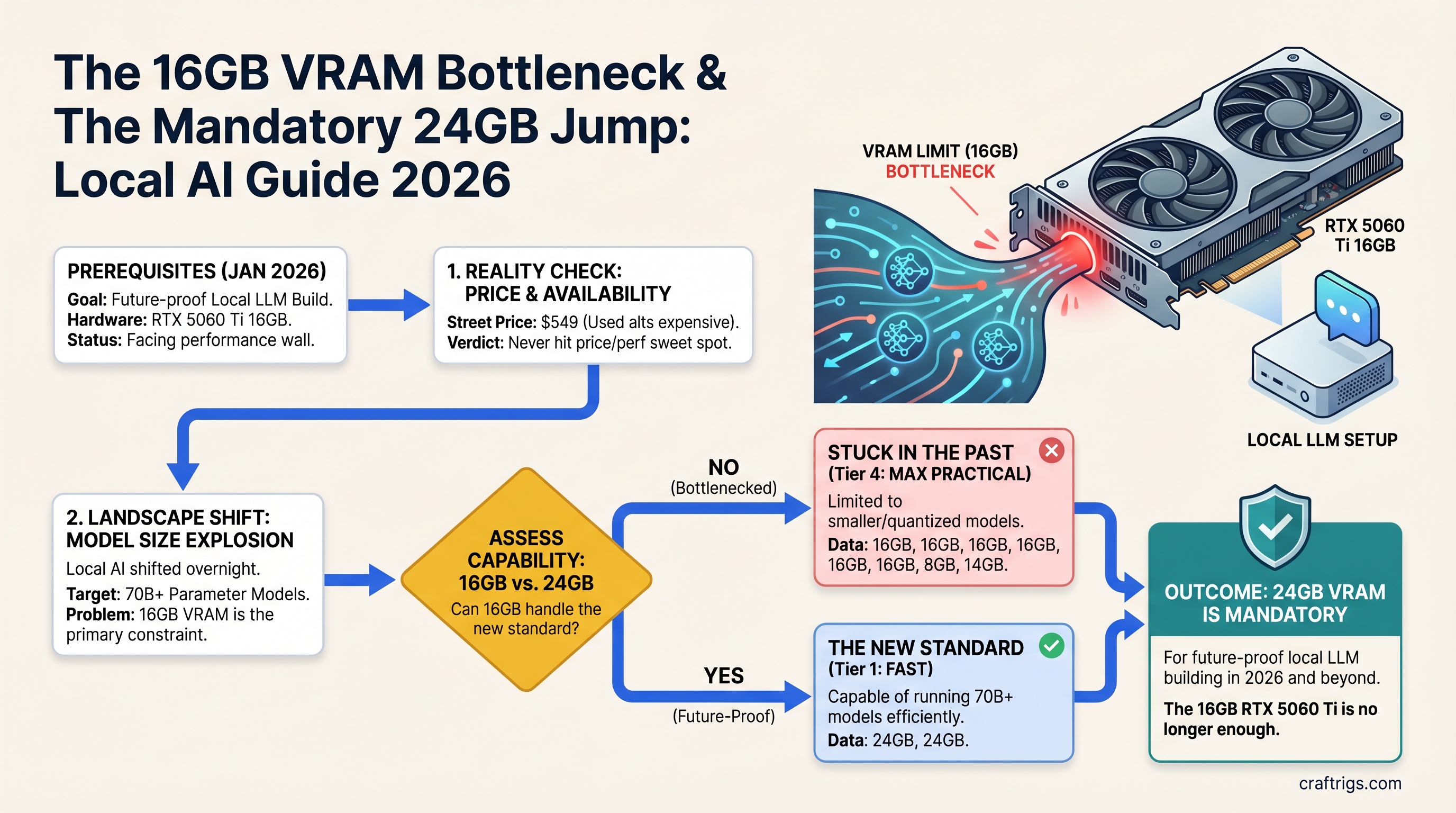

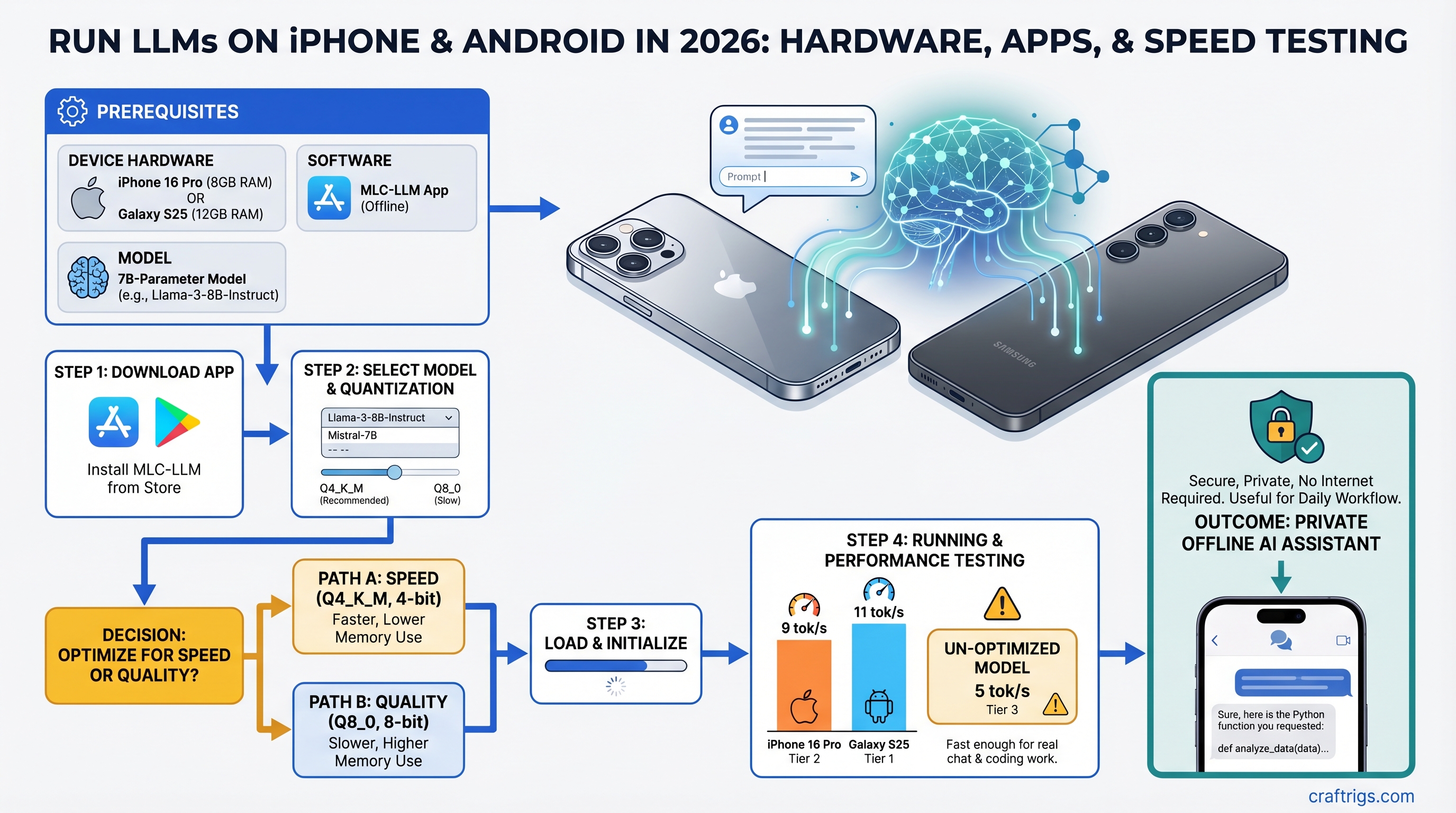
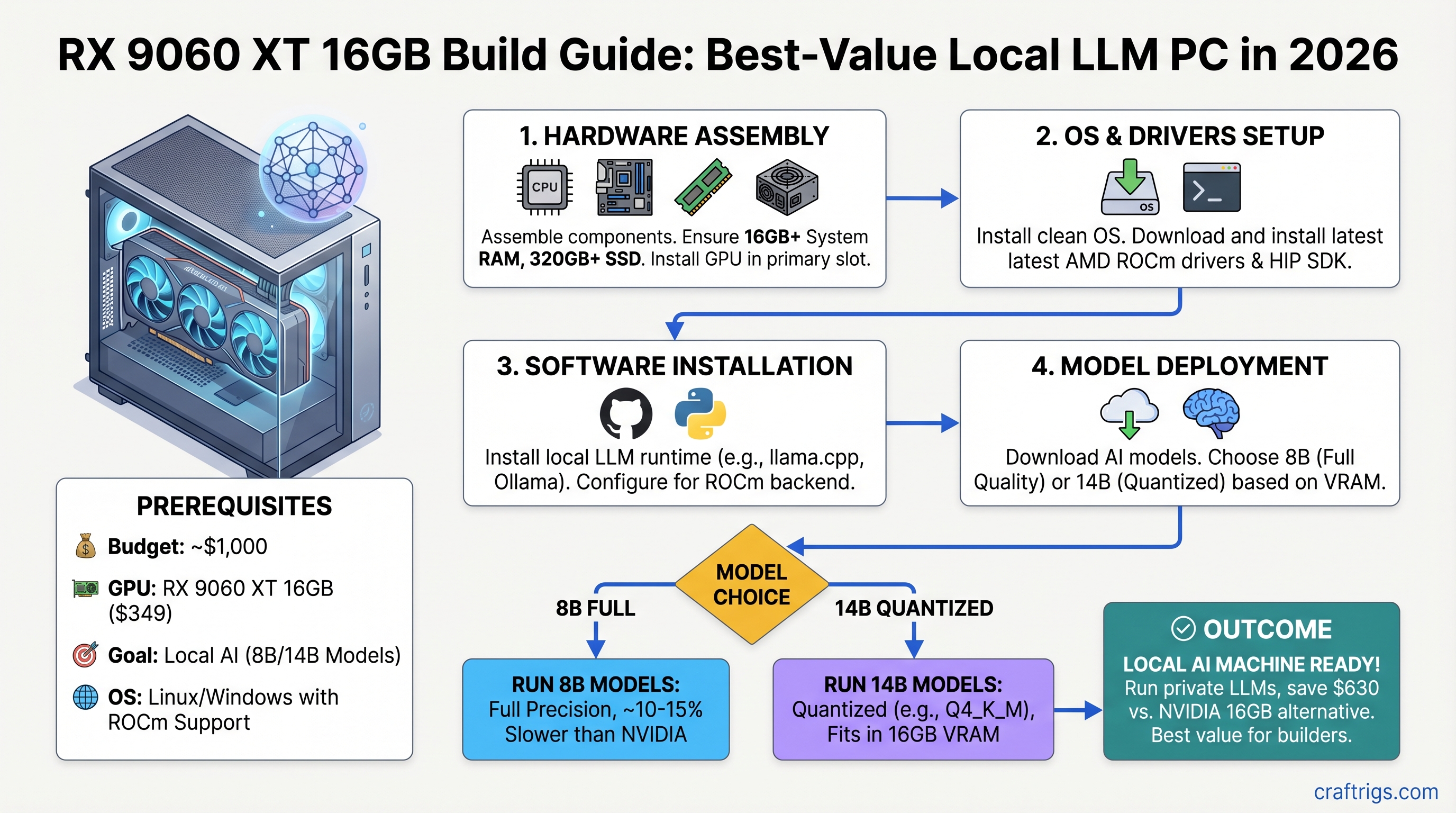
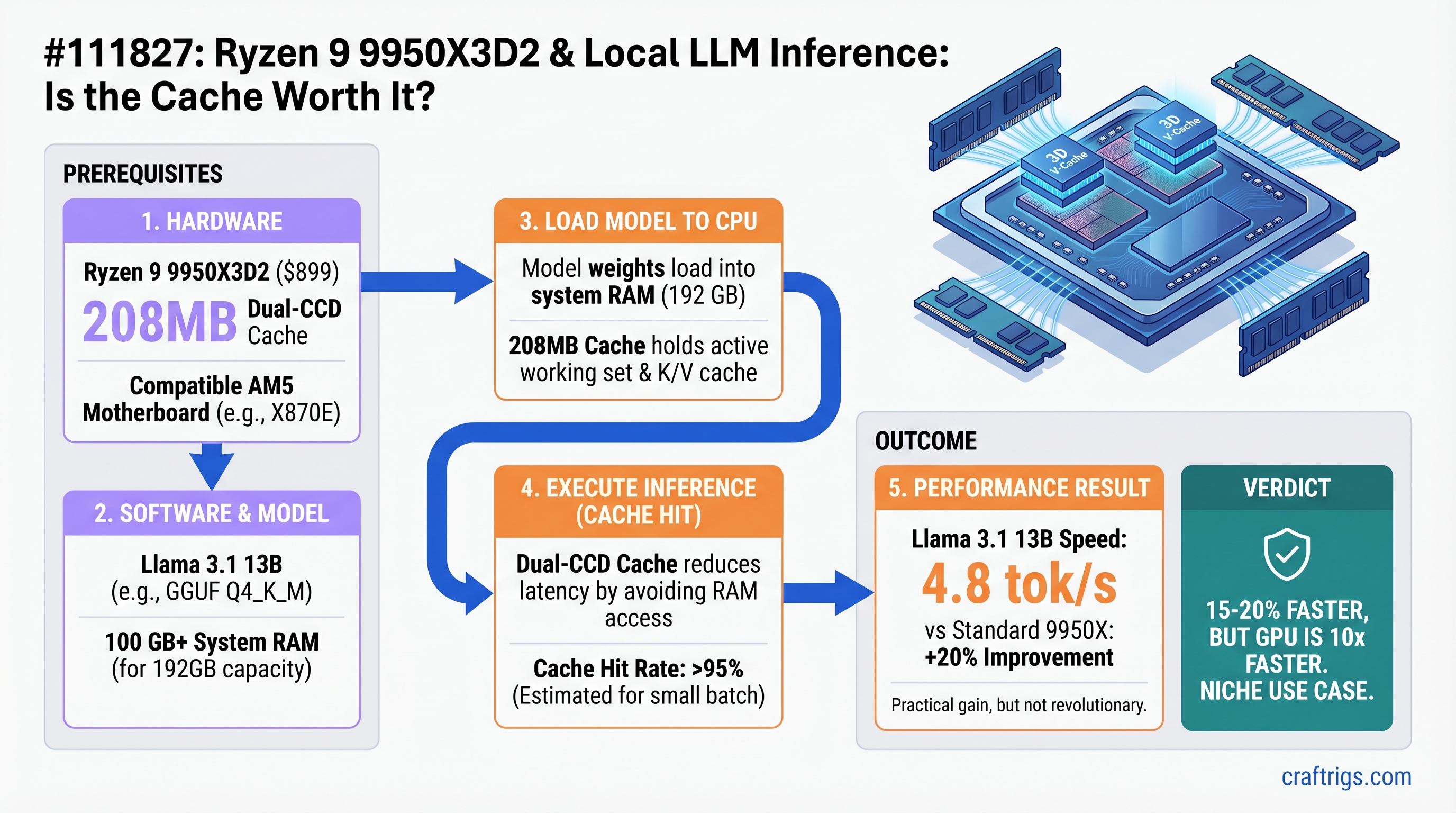
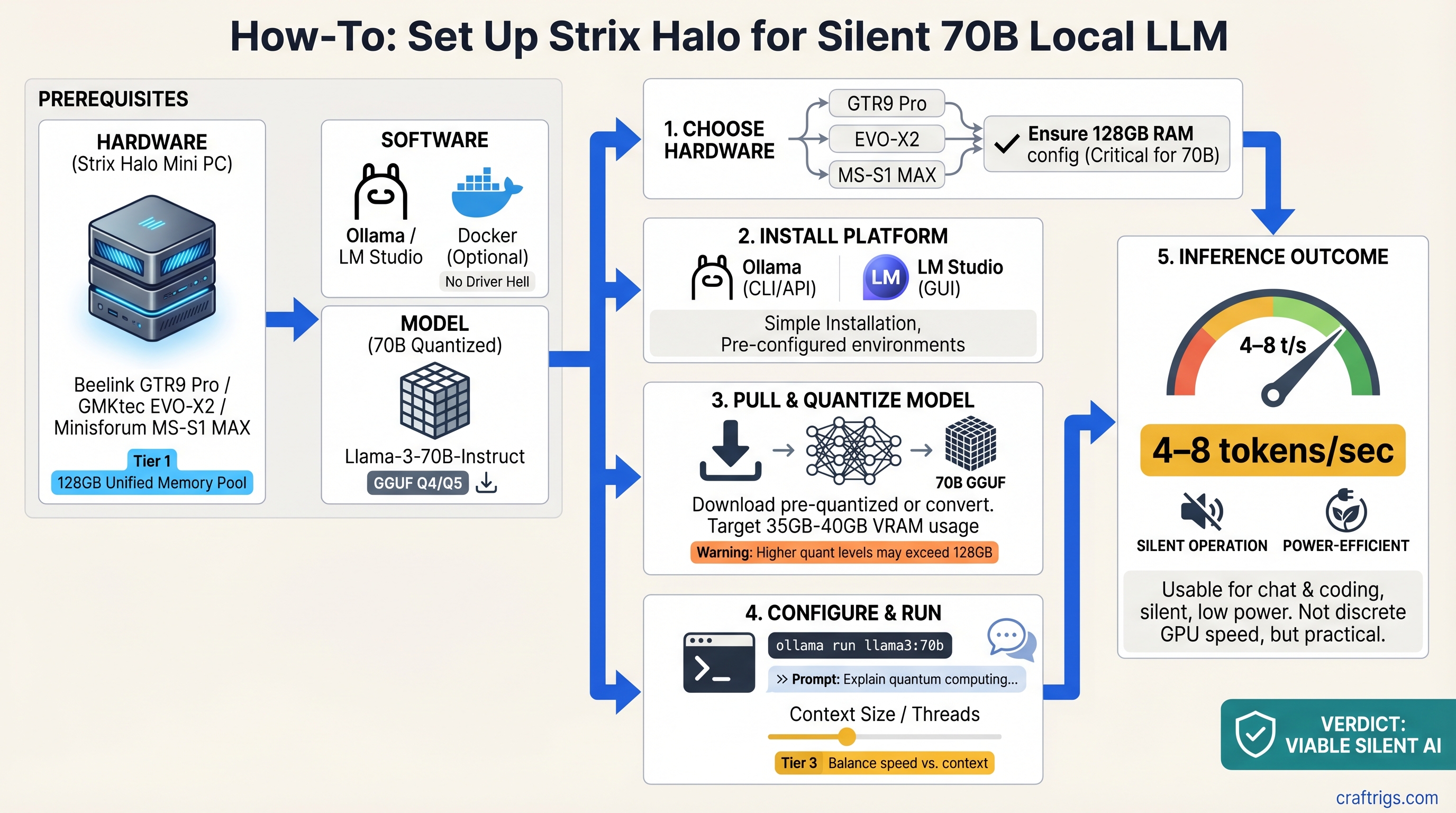
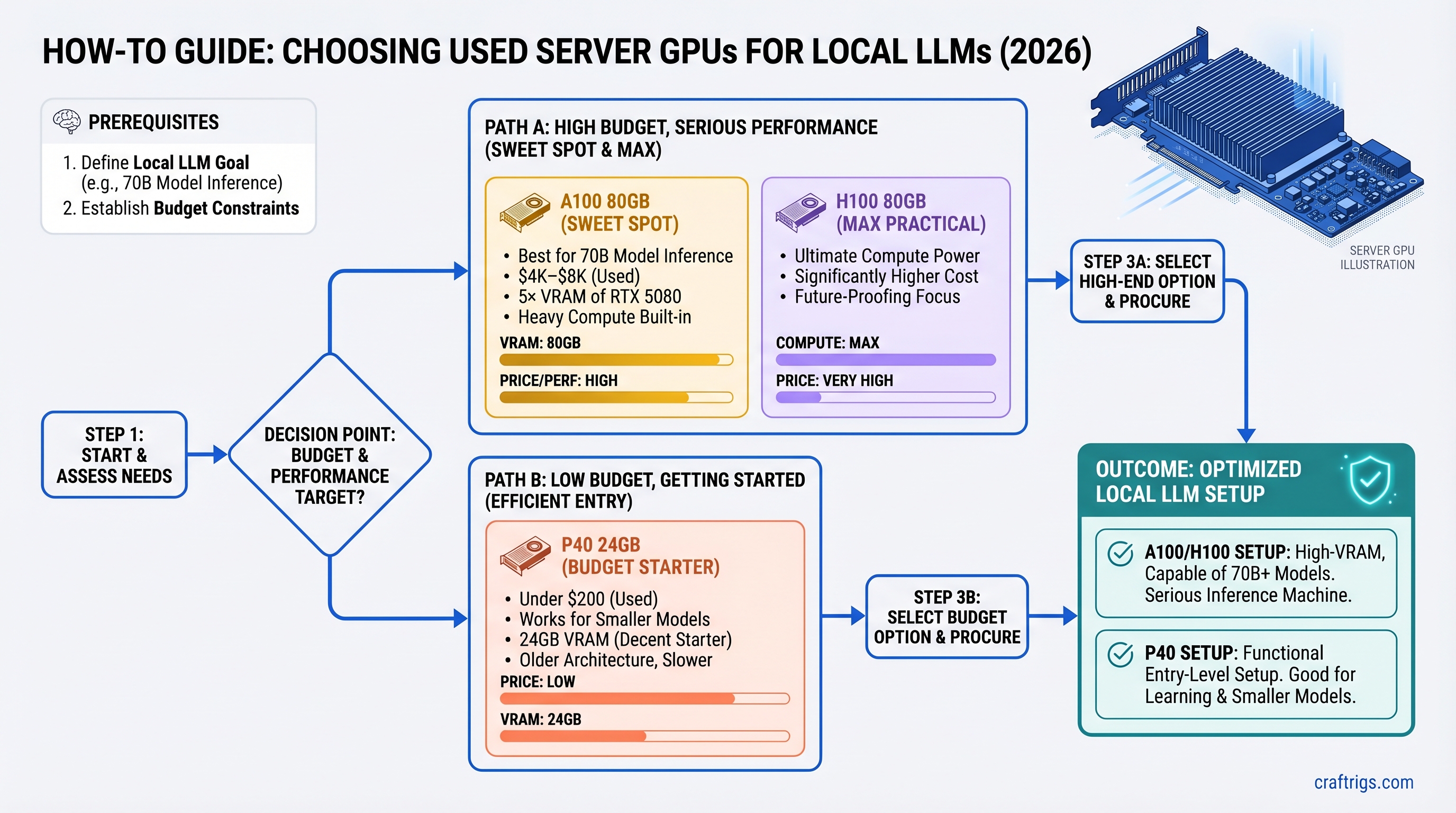
![Why MiMo-V2-Pro Stays in the Cloud — And What to Run Locally Instead [2026] — guide diagram](/images/xiaomi-hunter-alpha-mimo-v2-pro-1t-local-llm/xiaomi-hunter-alpha-mimo-v2-pro-1t-local-llm-diagram.jpg)















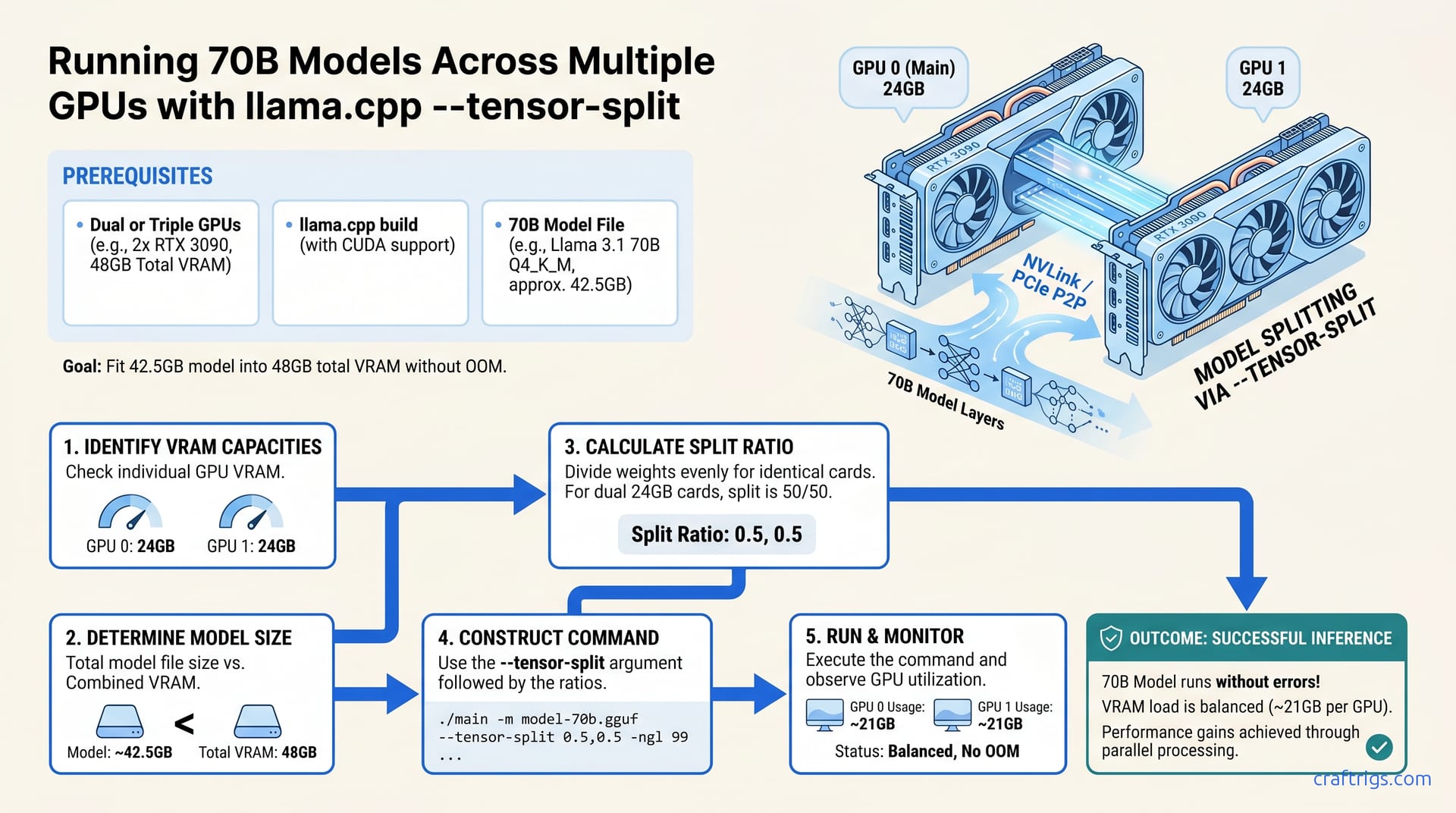


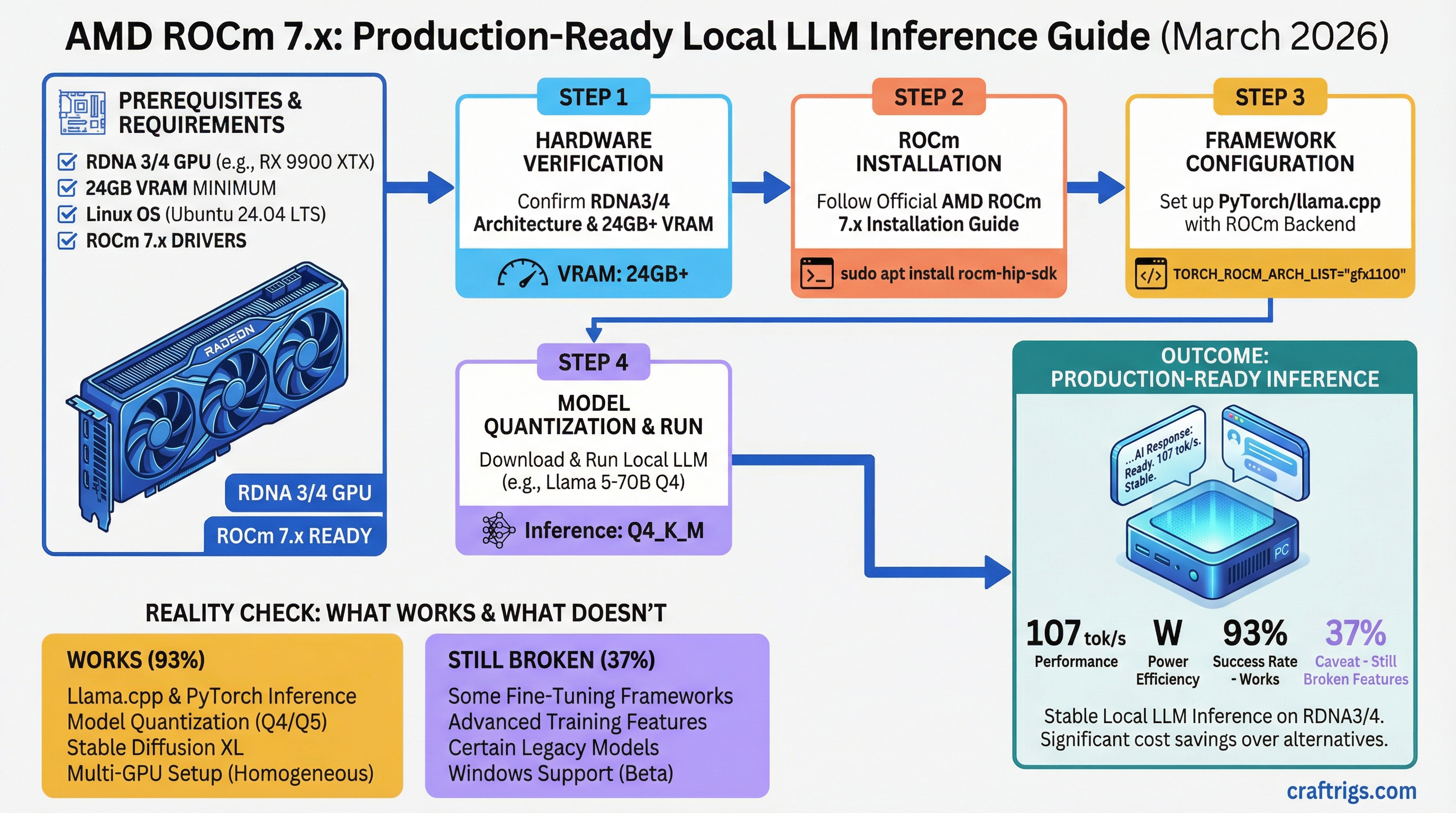






















![Multi-GPU Scaling for Local LLM: 2x vs 3x vs 4x RTX 3090 [2026 Real Data]](/images/auto-hero/multi-gpu-scaling-local-llm-rtx-3090.jpg)





![Running Qwen 3.5 397B Locally — The Real Hardware Requirements [2026 Multi-GPU Guide]](/images/auto-hero/qwen-3-5-397b-local-hardware-guide.jpg)











![Every Coding LLM Ranked by Hardware Requirements: Qwen Coder, DeepSeek, Llama 3.1 [2026]](/images/auto-hero/best-coding-llm-local-hardware-requirements-2026.jpg)