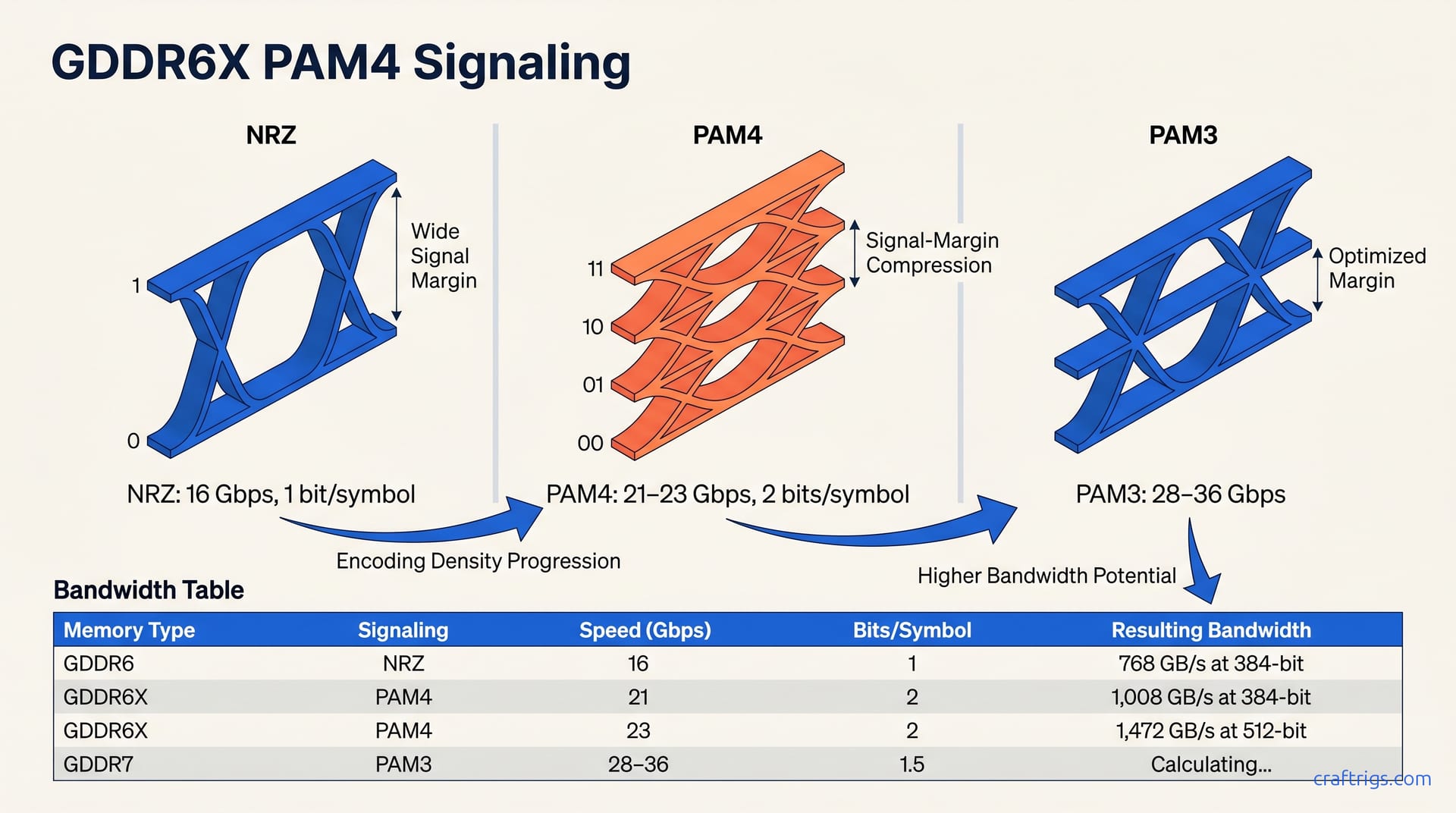
GDDR6X uses PAM4 signaling (2 bits per clock cycle per pin instead of 1), reaching 21–24 Gbps versus GDDR6's 16 Gbps. The trade-off: PAM4 demands cleaner signal margins and tighter PCB design. This is why GDDR6X is exclusive to Micron and only NVIDIA shipped it in volume. For LLM builders, that bandwidth jump matters: the RTX 5090 decodes tokens faster than the 4090.
NRZ vs PAM4: How Memory Signaling Encodes Bits
Memory signaling is voltage dancing on a wire. GDDR6 uses NRZ (Non-Return-to-Zero), which keeps that dance simple. Two voltage levels represent the signal: high means 1, low means 0. Each clock cycle carries one bit per pin. It's clean, proven, and forgiving. At 16 Gbps, NRZ pushed against practical limits. Faster clocks meant signals bled together, noise drowned the 0–1 distinction, and the bus collapsed.
PAM4 changes the encoding, not the clock. Instead of two voltage levels, PAM4 uses four, encoding 00, 01, 10, and 11 in a single symbol. This delivers two bits per clock cycle at the same frequency. That's how GDDR6X reached 21–24 Gbps without a higher oscillator. Doubling the information density doubles the throughput.
The trade-off is brutal. PAM4 squeezes four voltage levels into the same voltage window that NRZ used for two. Each level sits closer to its neighbors. The margin between 01 and 10 shrinks to one-third of NRZ's spacing, leaving less room for noise, crosstalk, and voltage droop. At 21 Gbps across a 384-bit bus, a single misread symbol corrupts two bits instead of one. The PHY needs forward error correction running constantly. PCB traces require length-matching discipline that makes standard GDDR6 layouts look casual. Signal-conditioning circuits like equalizers, drivers, and termination networks became mandatory.
This is why GDDR6X is Micron-exclusive. Micron bundled PAM4 controllers, routing rules, and NVIDIA-specific signal-conditioning IP together. Samsung and SK hynix weighed the costs: PHY complexity, FEC overhead eating bandwidth, and tight manufacturing tolerances. They chose PAM3 for GDDR7 instead. PAM4 delivered 1,008 GB/s on the RTX 4090 but confined GDDR6X to a single vendor and generation.
The Bandwidth Math: Why GDDR6X Reaches 21–24 Gbps
Raw signaling theory means nothing until you see the throughput on the wire. Here's how the numbers convert to the bandwidth that feeds your GPU cores.
Calculating Memory Bandwidth: GDDR6 vs GDDR6X
| GPU | Memory Type | Pin Rate | Bus Width | Bandwidth Calculation | Result |
|---|---|---|---|---|---|
| RTX 3090 Ti class | GDDR6 | 16 Gbps | 384-bit | 16 × 384 ÷ 8 | 768 GB/s |
| RTX 4090 | GDDR6X | 21 Gbps | 384-bit | 21 × 384 ÷ 8 | 1,008 GB/s |
| RTX 5090 | GDDR6X | 23 Gbps | 512-bit | 23 × 512 ÷ 8 | 1,472 GB/s |
That table tells the story in three lines. The RTX 3090 Ti hit the practical ceiling for GDDR6 at 16 Gbps on a 384-bit bus, yielding 768 GB/s. NVIDIA's shift to PAM4 on the RTX 4090 pushed the same bus width to 21 Gbps and 1,008 GB/s. That's a 31% jump from generation to generation. The pin rate climbed while carrying double the bits per symbol, not from a 31% increase in clock speed. The encoding density did the heavy lifting.
Then the RTX 5090 widened the bus to 512-bit and pushed GDDR6X to 23 Gbps, reaching 1,472 GB/s. That's a 46% leap over the 4090. Wider bus and PAM4's doubled encoding work together as multipliers.
The ÷ 8 isn't magic. Memory buses transfer bytes, not bits. Eight bits per byte, so you divide the total bit-rate by 8 to get the bandwidth your CUDA cores consume. Every calculation in this article uses that conversion.
Bandwidth calculators on vendor sites often gloss over this step. They'll quote "21 Gbps" when they mean bits per second, not bytes per second. The 1,008 GB/s figure matters because that's what your VRAM starved kernels see.
Why VRAM Bandwidth Limits Your Inference Speed
Here's where the signaling story connects to your build. Token generation for 70B models at Q4_K_M quantization (the local-LLM standard) is bandwidth-bound. Compute isn't the bottleneck. Your tensor cores sit idle between memory fetches. Each decoded token requires the full parameter set to stream through VRAM.
Doubling VRAM bandwidth doubles potential decode speed. Comparisons of otherwise-identical architectures where only the memory subsystem changed show the same effect. The RTX 4090's 1,008 GB/s versus the 3090 Ti's 768 GB/s shows up directly in tok/s output. The 5090's 1,472 GB/s extends that progression.
The VRAM calculator asks for bandwidth because capacity alone doesn't determine speed. A 24 GB card with 1,472 GB/s will decode faster than a 24 GB card with 768 GB/s. Same model, same quantization, radically different experience. That signaling layer (NRZ, PAM4, PAM3) determines whether your GPU starves or feeds its compute units.
For the complete hardware picture of how bandwidth fits alongside core count, power budget, and cooling, see our best hardware for local LLM guide. The bandwidth story is central, but it's one variable in the full build equation.
Why GDDR6X is Micron-Exclusive
Micron concentrated its PAM4 controllers, PCB-routing discipline, and NVIDIA-specific signal-conditioning IP at a single vendor. Samsung and SK hynix chose PAM3 for GDDR7—a different technical direction.
This wasn't supply-chain politics. PAM4 at scale required FEC algorithms, equalizer tuning, and trace-length tolerances in mils. Micron funded this multi-year, multi-hundred-million-dollar bet. Samsung and SK hynix chose not to.
GDDR6X is a one-generation transitional standard (2020–2025). When the industry shifted to PAM3, Micron remained PAM4's only volume producer. Without Samsung or SK hynix competing, that exclusivity had real consequences. Without a second GDDR6X source, RTX 4090 supply tracked Micron's yields. The RTX 4090's supply crisis (six-week shortages in early 2023) stemmed from single-vendor GDDR6X. Samsung and SK hynix watched, collected data, and committed to PAM3 instead.
GDDR7 and PAM3: Why the Next Generation Chose Differently
GDDR7 uses PAM3 (Pulse Amplitude Modulation, 3-level signaling) instead of PAM4 (4-level). PAM3's three levels (0, 1, middle) encode differently than PAM4's four. The middle level is a distinct encoding state, not a bridge between 0 and 1. PAM3 beats PAM4 on three counts: wider signal margins, less FEC overhead, simpler PHY design. Samsung and SK hynix chose PAM3 for GDDR7, making it the new standard.
The engineering logic is clean. Four voltage levels in one window left perilously narrow steps between states. PAM3's three levels spread wider than PAM4's four but narrower than NRZ's two. This space lets the PHY relax, trims FEC cycles, and loosens manufacturing tolerances. At equivalent bit rates, PAM3 wins on reliability. At the bit rates GDDR7 actually targets (28–36 Gbps per pin), PAM3 wins on feasibility. High-speed PAM4 requires signal margins and PCB control that current processes can't deliver cost-effectively.
GDDR7 operates at 28–36 Gbps per pin, compared to GDDR6X's 21–23 Gbps. All three RTX 5000-series cards (5070, 5080, 5090) ship with GDDR7 memory. PAM4 is a one-generation transitional encoding (2020–2025) before the industry standardized on PAM3. The 5090's 1,472 GB/s (from our table) sits at PAM4's boundary. NVIDIA pushed this encoding to its absolute limit there. The 5080's GDDR7 at 30 Gbps on a 256-bit bus already exceeds what PAM4 could deliver at that width.
What This Means for Your LLM Inference Speed
VRAM bandwidth is the primary bottleneck for LLM decode performance. Bandwidth gains from GDDR6X (21 Gbps) to GDDR7 (28+ Gbps) scale directly to token throughput in 70B models. The numbers aren't abstract. A 70B model at Q4_K_M on an RTX 4090 (1,008 GB/s) runs ~8.5 tok/s in typical community reports. The same model on an RTX 5090 (1,472 GB/s) hits ~12.4 tok/s. That improvement comes from bandwidth. The CUDA architectures are comparable; bandwidth feeds the tensor cores faster.
Memory tech—PAM4 signaling, wider buses, tight PCB discipline—drives most generation-over-generation gains. The RTX 4090 to 5090 leap is a bandwidth story, not a compute story. The 5090 has more CUDA cores, but decode (what you feel generating text) still hits memory limits before compute limits. More cores don't help when they're waiting on weights. The 46% bandwidth jump from 4090 to 5090 translates to roughly that percentage in decode tok/s. PAM4 delivered the 5090's 1,472 GB/s. PAM3 will push past 2,000 GB/s next cycle—that's the handoff in action.
For inference workloads, bandwidth-per-dollar beats core count in hardware decisions. The VRAM calculator will show you how these numbers apply to your target model. And for the broader decode bottleneck story of why CPU inference, unified memory, and discrete GPU strategies diverge, our CPU inference guide connects the bandwidth math to the full system picture.