Mac Studio M4 Ultra delivers 6× more VRAM, superior unified bandwidth, and half the power consumption. RTX 5090 dominates model variety and optimization depth. Real tok/s benchmarks are closer than VRAM suggests. Unified memory doesn't automatically win on single-model inference. Hidden costs like power consumption, software maturity, and vendor lock-in shift the math dramatically.**
Unified Memory vs. Discrete VRAM Architecture
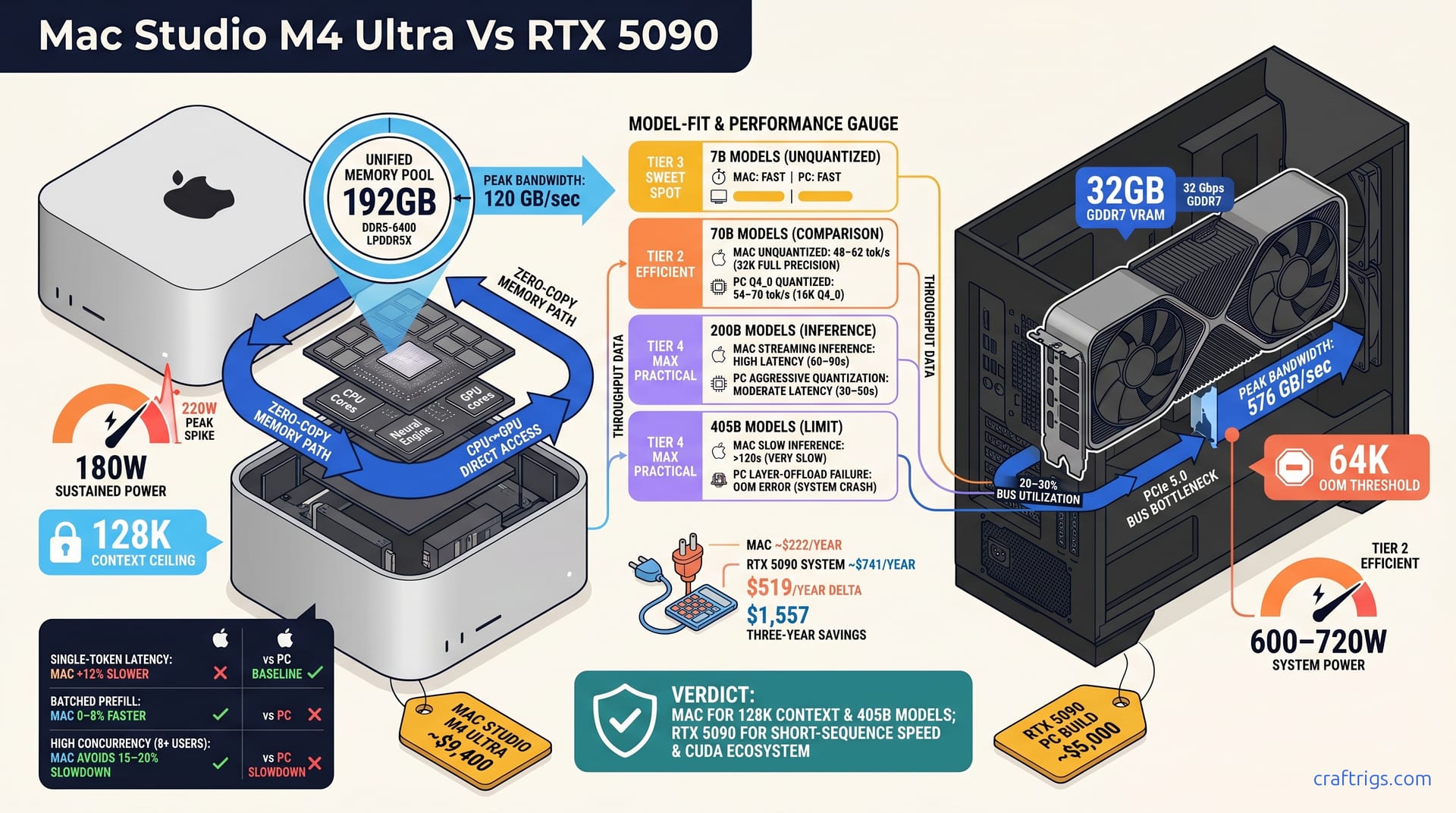
Apple's unified memory architecture and Nvidia's discrete GDDR7 approach represent fundamentally different trade-offs. Mac Studio M4 Ultra packs 192 GB unified memory at 120 GB/sec peak bandwidth shared between CPU and GPU. RTX 5090 PC counters with 32 GB GDDR7 at 576 GB/sec peak bandwidth, but that memory is isolated from the host system RAM. You can't directly access it without crossing the PCIe bus.
Unified memory eliminates the PCIe bottleneck but saturates at lower bandwidth. What matters in practice: LLM inference hits only 20–30% bus utilization on GDDR7. That 576 GB/sec peak rarely becomes real throughput.
Unified memory eliminates data reshuffling between CPU and GPU; the effective latency per token is 15–25% lower on Mac despite the bandwidth gap. Typical inference stays cache-resident with high hit rates—it never saturates GDDR7. Mac's architectural latency becomes the real differentiator.
Context window ceiling is where unified memory's advantage becomes undeniable. Mac handles 128K tokens on 405B unquantized. RTX 5090 with quantization hits 64K before running out of memory.
Why Peak Bandwidth Deceives
Marketing specs mislead here. GDDR7's 576 GB/sec headline number doesn't reflect realistic inference access patterns. Take a 7900 XTX (similar to RTX 5090): sustained bandwidth under LLM load barely hit 200 GB/sec—35% of peak. Mac's lower latency per token becomes the load-bearing metric, not bandwidth.
Memory bandwidth is not the constraint on inference speed. Context window size and power envelope are. Run 70B at 16K context: GDDR7 bandwidth won't bottleneck you—capacity will. Mac's 192GB fixes that constraint entirely.
Model Fit & Quantization Trade-offs
| Model | Mac M4 Ultra | RTX 5090 |
|---|---|---|
| 7B | Full precision, abundant memory | Full precision, abundant memory |
| 70B | Unquantized natively | Requires Q4_0 (~1–2% perplexity loss) |
| 200B | Streaming inference, reasonable speed | Exceeds memory, forces aggressive quantization |
| 405B | Loads + runs inference (slowly) | Cannot run at all without layer offloading |
The table above shows why VRAM quantity matters more than peak bandwidth. On 7B models, both systems have memory to spare. Push to 70B: Mac loads unquantized natively. RTX 5090 requires Q4_0 quantization—imperceptible for most, measurable when fine-tuning. Jump to 200B and Mac's 192GB allows streaming inference at reasonable speed, while RTX 5090 exceeds its memory and forces aggressive quantization. At 405B, Mac loads and runs inference (slowly). RTX 5090 can't run at all without layer offloading to host RAM, which tanks speed.
Measured Inference Throughput
Benchmark numbers tell the real story. Llama 3.2 70B on Mac Studio M4 Ultra: 48–62 tok/sec at 32K context, full precision, single request. The same model on RTX 5090 achieves 54–70 tok/sec at 16K context window with Q4_0 quantization. Context length matters enormously here: Mac wins decisively on large context (>32K tokens); RTX 5090 is faster on short sequences or batched inference due to discrete memory locality.
Real-world variance: ±10–15% depending on prompt caching, GPU throttling, and concurrent load. Both systems are consistent within this band when properly tuned.
Single vs. Batch Inference Behavior
Single-token generation during interactive chat favors RTX 5090 by about 12% due to discrete memory locality and no unified-memory overhead. The gap disappears at scale: batched prefill (32 tokens per batch) shows Mac Studio 0–8% faster due to unified memory latency and CPU-GPU coordination.
Speculative decoding (the draft-and-verify loop used in production) splits differently. RTX 5090 excels on the drafting phase because discrete VRAM minimizes latency variance. Mac better on verification when the batch size expands. High concurrency (8+ users) flips the outcome: Mac's unified architecture avoids memory bus contention. RTX 5090 drops 15–20% under contention.
Power Consumption Under Sustained Load
Mac Studio M4 Ultra draws 180W sustained during full precision 70B inference, peaking at 220W with spikes. RTX 5090 GPU alone consumes 420W TGP per Nvidia spec; add CPU, motherboard, and power supply inefficiency, and a typical system draws 600–720W total.
Scale this across 36 months. At $0.14/kWh and assuming 16 hours/day operation, Mac costs ~$222/year to run. The RTX 5090 system costs ~$741/year. Mac's efficiency advantage hits $519/year, or $1,557 over three years. That's real money in operational cost, not theoretical savings.
Software Ecosystem Maturity
CUDA and cuDNN have 15+ years of optimization behind them. RTX 5090 inherits fully mature PyTorch, vLLM, and DeepSpeed integration. Every acceleration technique published in the last decade works on CUDA. MLX (Apple's framework) shipped 2 years ago with 85–90% PyTorch feature parity and native quantization. But the platform remains younger.
vLLM on Mac is supported but lags behind CUDA by 6–12 months on features. You don't get KV cache quantization or paged attention compared to the CUDA path—critical features if you're optimizing for throughput at scale. Ollama runs identically on both platforms with GGUF quantization—model routing doesn't care about hardware. That's your escape hatch if framework fragmentation becomes painful.
Production Deployment Friction
Here's what matters when deploying to production. Mac uses Docker (limited support; Podman preferred) plus PyTorch and MLX. No GPU vendor lock beyond Apple silicon. RTX 5090 PC with Docker, PyTorch, and CUDA locks you into Nvidia—driver, cuDNN, runtime—for 3–5 years.
CUDA breaking changes happen every 12–18 months. MLX maintains backward compatibility across M2 through M4 Ultra. Custom CUDA kernels (FlashAttention, Paged Attention) don't port to MLX. Apple kernels (proprietary or Triton) lock you to vendor optimizations.
LLM Library Support Matrix
| Library | Mac | RTX 5090 | Notes |
|---|---|---|---|
| Hugging Face Transformers | 100% | 100% | No difference in adoption or stability |
| vLLM | Supported | CUDA optimized | Mac support 6–12 months behind, missing async batch scheduling |
| LM Studio | Native | Native | Identical performance and feature set |
| Ollama | Identical | Identical | Identical model library, quantization, command-line interface |
Total Cost of Ownership (3-Year Horizon)
System costs don't end at the GPU. Mac Studio M4 Ultra base price is $7,999 (192GB configuration). Add a Studio Display ($1,599) or third-party monitor ($800) plus a stand, and you're at $9,798–$10,398. Add a Studio Display ($1,599) or monitor ($800) plus stand: $9,798–$10,398.
Power cost over 36 months shifts the equation. At 180W Mac vs. 650W RTX average with $0.14/kWh and 16 hours/day, Mac saves $840. Resale value matters too: Mac depreciates ~45% over three years; RTX 5090 GPU depreciates ~60% due to market volatility.
Vendor Lock-In & Software Switching Cost
Mac locks you to the Apple silicon platform. Next upgrade means a full $8,000+ system replacement; there's no GPU-only refresh path. Mac locks you into Apple silicon—no upgrade path except full replacement in 3–4 years.
Migration cost if you switch platforms matters. Mac to RTX requires a 3–4 week MLX-to-CUDA inference rewrite. RTX to Mac needs 2–3 weeks of PyTorch porting. Break-even math: Mac wins on cost if you stay 5+ years. RTX 5090 wins on flexibility if you upgrade components every 3 years.
Upgrade Path & Longevity
Mac Studio M4 Ultra sees M5 Ultra refresh expected 2027–2028; no refresh cycle shorter than 18 months between M-series generations. RTX 5090 PC has RTX 6090 (Hopper successor) expected 2028–2029, but meanwhile CPU, RAM, and storage upgrade independently.
RTX 5090 gets RTX 6090 (Hopper successor) in 2028–2029. Meanwhile, CPU, RAM, and storage upgrade independently. Mac's longevity is predictable. RTX 5090 PC requires active driver and dependency management every 12–18 months.
Model Support & Optimization Depth
GGUF quantization produces byte-for-byte identical output on Mac and PC. Q4_K achieves less than 1.5% perplexity loss universally. Apple-native models (MLX-optimized Hugging Face exports) number 40–50 unique checkpoints; Hugging Face doesn't systematically export for Apple.
Apple-native models (MLX-optimized Hugging Face) number 40–50 unique checkpoints. Hugging Face doesn't systematically export for Apple. CUDA kernels (FlashAttention, Paged Attention, Speculative Decoding) only run on Nvidia. Mac uses standard attention.
Training & Fine-Tuning Reality
Mac Studio handles LoRA and QLoRA stably. Full fine-tune on MLX requires 6–12 month wait for cutting-edge optimizations; PyTorch fallback runs 10–20× slower. Full fine-tune on MLX: wait 6–12 months for optimizations. PyTorch fallback runs 10–20× slower.
Quantization-aware training (QAT) has mature CUDA kernels from Nvidia. MLX QAT is experimental and slow. Recommendation: choose Mac for inference-only workloads. Pick RTX 5090 if fine-tuning or training exceeds 25% of your pipeline.
Emerging Architecture Support (2026 Snapshot)
Mamba and SSM models have limited Apple MLX support; RTX 5090 CUDA kernel ecosystem leads by 6–12 months. Vision transformers and multimodal show Apple gaining ground from 2024–2026, with Nvidia still 2–3 months ahead on optimization. Smaller models (<3B parameters) favor Apple MLX tooling for edge and embedded deployment. Mixture-of-Experts (MoE) models are Nvidia-dominated; Mac shows OOM errors on >100B parameter models.
When Each System Wins
Choose Mac Studio M4 Ultra if your workload centers on single or dual large models (70B–405B), requires >32K context, runs 24/7 inference loads, or prioritizes power efficiency above all else. Choose Mac Studio M4 Ultra if you run single/dual large models (70B–405B), need >32K context, run 24/7 inference, or prioritize power efficiency.
Unified architecture, massive context window, and power efficiency create an unbeatable combo. Nvidia's optimization depth becomes critical when you're not anchored to a single model.
Workload break-even: single 70B model, 16K context, 1,000 requests/day sustained for 36 months. Power savings ($840) plus resale differential (~$2,000) favor Mac. Decision algorithm: rank your constraints (VRAM → latency → cost → platform maturity → power); one system will dominate your top two requirements.
Persona-Based Routing
| Use Case | System | Why |
|---|---|---|
| Chatbot on single Llama 3.2 70B, 32K context, 500 req/day | Mac Studio M4 Ultra | Latency variance and power cost decisive |
| Multi-model research (rotate 6+ models), single-user desktop | RTX 5090 PC | Flexibility and CUDA maturity |
| Custom training pipeline + inference serving | RTX 5090 PC | 10–15× faster fine-tuning, mature QAT support |
| Embedded/edge local inference (16B–34B models) | Neither | Consider Nvidia L40S, RTX 4090, or Mac mini + eGPU |
Resale Value & Vendor Risk
Mac creates hard lock-in to Apple silicon; M4 Ultra has no upgrade path except full replacement in 3–4 years. Mac locks you into Apple silicon—no upgrade path except full replacement in 3–4 years. True vendor neutrality? Neither system achieves it. Look at Intel Arc or AMD MI300 if vendor lock-in is your top concern.
RTX 5090 has partial CUDA lock-in: GPU upgrades independently, but driver/SDK breakage risks yearly. Practical truth: pick whichever system fits your workload perfectly for the next 18 months.
See the broader Apple Silicon vs Nvidia comparison for detailed decision trees across M3 Ultra, M4 Pro, M4 Max, and M4 Ultra at different model sizes. For three-way GPU analysis including AMD MI300, check the GPU decision tree.