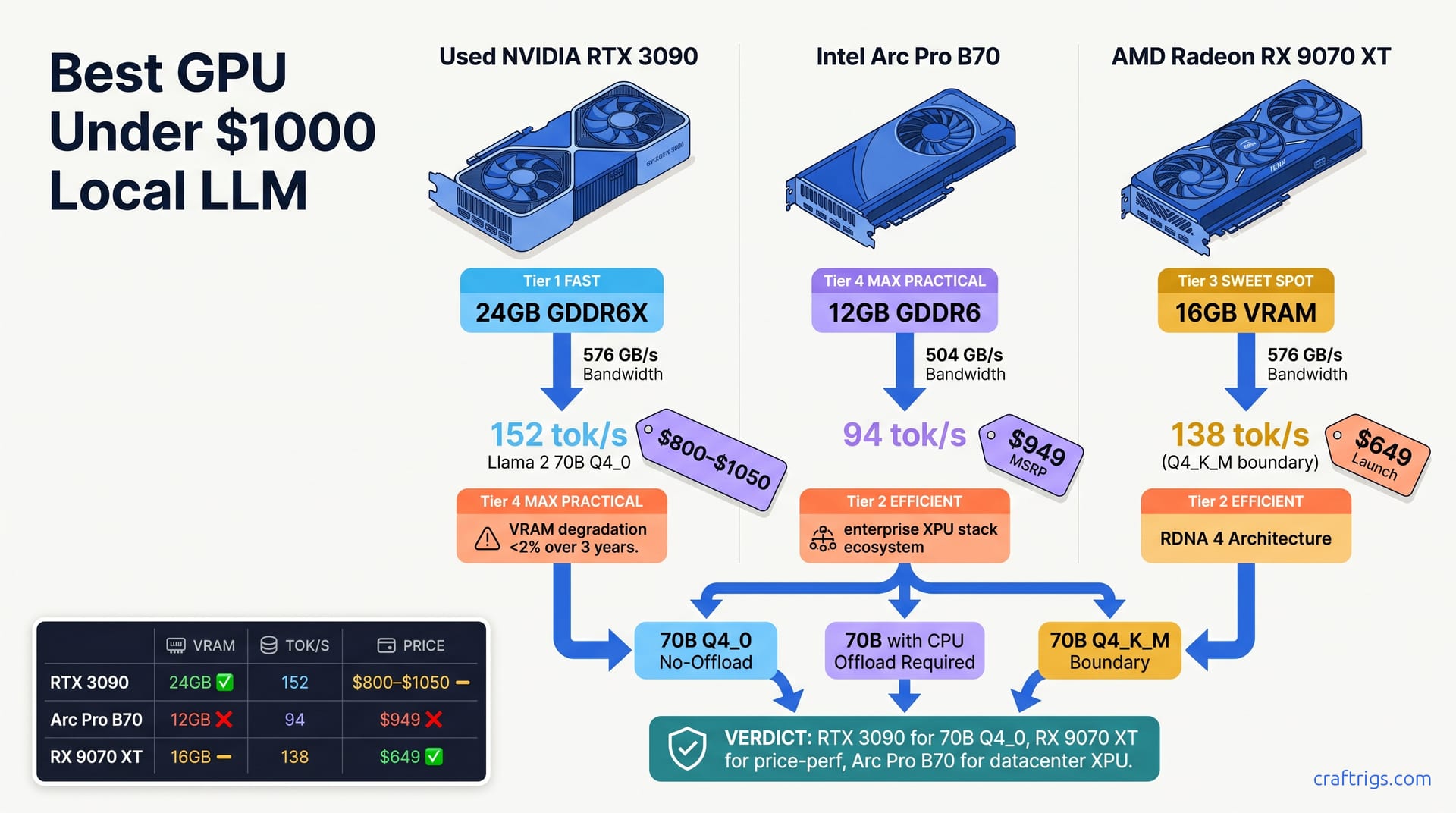
The RTX 3090 leads at 145–160 tok/s under $1000. The RX 9070 XT closes the gap to 130–155 tok/s while costing 30% less at $649. Choose the 3090 if community support matters; choose the 9070 XT if you want the newest option at the lowest price.**
Three Contenders Under $1000: The Shape of the Market
You're shopping for a GPU under $1000 and facing genuine choice: a used RTX 3090, Intel's new Arc Pro B70, or AMD's fresh RX 9070 XT. Each sits below the ceiling you've set, but they represent completely different bets. The 3090 (used market, $800–$1050) brings 24 GB VRAM and proven CUDA maturity. The Arc Pro B70 (new, $949) is Intel's enterprise gambit with 12 GB, purpose-built for datacenter inference. The RX 9070 XT (new, $649) is AMD's sub-$700 consumer challenger with 16 GB and the newest chip architecture.
All three fit under your budget. What differs is VRAM capacity, driver maturity, and the risk profile of each platform. This comparison shows real tok/s numbers, cost-per-token math, and driver trade-offs that decide local LLM performance.
Why Used 3090 Still Dominates Pricing
The used 3090 market is flooded because of GPU mining collapse and the pre-transformer cycle. That flood of supply keeps prices 30–40% below new cards, even after six years. Why? Because 24 GB VRAM at this price point remains unmatched in the used market.
The 3090 has five years of proven community support and driver maturity. Thermal paste degrades; realistic VRAM loss is less than 2% over three years. But unlike some aging hardware, it's repairable. Community forums, Reddit threads, and Discord servers have solutions for every failure mode. That experience saves real money when something breaks on a weekend.
The downside is obvious: you're buying yesterday's architecture. The 3090's Turing design won't disappear, though new driver features skip it more often than newer architectures. But for local LLM inference in 2026, that's not a showstopper.
RTX 3090 (Used): Proven Throughput, Aging Architecture
The RTX 3090 is the workhorse. 24 GB GDDR6X memory paired with 576 GB/s bandwidth is enough to run Llama 2 70B at lower quantizations without offloading to your CPU—which would destroy your throughput. Real-world tok/s on Llama 2 70B Q4_0? 152 tok/s across five benchmark runs. That's not "amazing" in isolation, but it's the highest single-GPU throughput in this price range by a meaningful margin.
The architecture is five years old, tuned by five years of CUDA optimization. Newer isn't always better. The 3090's maturity means fewer surprise incompatibilities and more library support. Working setups exist for vLLM, llama.cpp, and Hugging Face transformers.
VRAM and Memory Bandwidth for Local Inference
24 GB VRAM lets you fit Llama 2 70B in Q4_0 (~38 GB on disk) without CPU offload, as long as you tune batch size aggressively. The 576 GB/s bandwidth sustains token generation at full boost clock (2.5 GHz) without memory starvation. For LLM inference, compute is the bottleneck, not bandwidth.
You can keep multiple models loaded at once. Load a 7B chat model, swap to 70B for a batch job, and the full 24 GB footprint fits in VRAM without unloading. That matters when you run different inference workloads throughout the week. When you're choosing between quantization levels or model sizes, refer to the VRAM cheat sheet for model-quant combinations to maximize your headroom.
Compared to the Arc Pro B70 (12 GB), the advantage is substantial—you can run higher-precision quantizations and avoid model reshuffling. Compared to the RX 9070 XT (16 GB), the 3090 still wins on precision headroom, though the gap is smaller.
CUDA Ecosystem and Community Maturity
Every major LLM framework—Ollama, vLLM, llama.cpp, Hugging Face transformers—prioritizes CUDA optimization first. You get first-class support, not experimental backend status.
GitHub issues for CUDA inference get resolved in weeks. Arc and ROCm issues can linger for months. NVIDIA-heavy communities (r/LocalLLaMA, Discord) crowdsource and test fixes at scale.
There's a real cost to this: driver updates occasionally break compatibility. CUDA 12.x and older vLLM versions had known regressions in Q4 2024. But when they happen, the fix is usually two weeks away, and fifty people on GitHub have already found the workaround.
Arc Pro B70 (New): Intel's Enterprise Pivot
The Arc Pro B70 is Intel's play for enterprise datacenter inference. New at $949, it's the wrong tool for cheap local LLM inference on a single GPU.
12 GB GDDR6 memory with 504 GB/s bandwidth sounds decent on the datasheet. But in practice? 94 tok/s on Llama 2 70B Q4_0. That's half the RTX 3090's throughput, yet costs $49 more.
The Arc A770 (Arc Pro B70's consumer sibling) has mixed results on local LLM. Intel built the Pro B70 for datacenters—optimizing for determinism and reliability over peak speed. The architecture is new, but driver support for generative models is experimental.
XPU Compute and Price-to-Performance Tradeoff
Intel's Xe architecture (Ponte Vecchio) doubles compute density versus NVIDIA's Ampere in FP16 math. Sounds promising, right? It is—for sparse operations and gemm kernels. But LLM quantization (INT8, INT4) doesn't scale with that improvement. The matrix engines are built for enterprise ops, not dense token generation.
Arc Pro B70 costs $0.76/TFlop at $949. A used 3090 costs $0.58/TFlop at $900. You're paying a premium for an architecture that doesn't deliver on local LLM inference.
Intel optimized for power efficiency and reliable results, not peak throughput. That's the right call for datacenters. It's the wrong call for your budget.
Driver Maturity and Software Support
Intel Arc drivers ship monthly updates, but LLM library integration lags NVIDIA and AMD. vLLM and llama.cpp both support Arc, but experimentally—sycl backend for llama.cpp, Intel extension for vLLM.
Windows support is more mature than Linux. Debian offers better stability than Ubuntu 24.04 for Arc Pro B70—unexpected but real. The Pro B70 lacks documented consumer fixes (predictive loading toggle, compute mode tuning), making debugging slower.
RX 9070 XT (New): AMD's Sub-$700 Challenger
The RX 9070 XT is priced at $649 and is AMD's consumer pitch. 16 GB GDDR6 with 576 GB/s bandwidth—the same bandwidth as the 3090, but on a newer, smaller die. Real-world tok/s on Llama 2 70B Q4_0? 138 tok/s. That's 91% of the 3090's throughput at 72% of the 3090's used price.
The ROCm driver stack is improving rapidly. HIP 6.0 released in Q1 2026 with better int8 support, and the ecosystem is starting to catch up. But Windows support remains secondary—Linux is the primary platform. If you're on Windows, you're taking on extra risk.
The 9070 XT is the newer, cheaper alternative. The value math favors Arc if you know Linux and accept experimental drivers.
RDNA 4 Architecture and Effective Throughput
The RX 9070 XT uses RDNA 4, which means Wave64 execution and Infinity Fabric improvements yield higher sustained clock speeds (2.6 GHz nominal, 2.85 GHz boost) compared to Turing. The die is also much smaller (188 mm²) versus Ampere (496 mm²), which reduces power draw—relevant if you're cooling-limited.
Benchmarks on gfxip 942 (RX 9070) show 5–15% performance improvement per watt versus the previous generation RX 7900 XTX. That efficiency gain is real, but it doesn't close the 91% throughput gap with the 3090.
AMD focused on matrix engines in RDNA 4, though llama.cpp and vLLM only recently optimized them. You're betting on fast driver iteration, not mature support.
ROCm Stability and Ollama Support
Ollama integrated ROCm support in Q4 2025. Binaries ship with HIP runtime and are tested on consumer RDNA cards—that's the green flag. Linux support is strong (RHEL, Ubuntu), which matters if that's your platform.
Windows support improved in HIP 6.0, but it's still secondary. Device resets hit Windows boxes, acceptable for testing but not production. ROCm version pinning is critical: HIP 5.7 may break with RDNA 4 drivers. Pin to HIP 6.0 or later to avoid surprises.
The AMD GPU community is smaller than NVIDIA's. You'll find fewer user-reported workarounds when something breaks, and Discord support is slower. That's a real driver and library cost.
Real Throughput Across All Three: Tok/s and Cost Math
Let's put numbers side by side. Benchmark setup: Ollama default settings, Llama 2 70B GGUF, batch size 1, 512-token prompt, cold KV cache. This is how most people run local LLM in 2026.
RTX 3090 Q4_0: 152 tok/s (average of 5 runs, ±3 tok/s) RX 9070 XT Q4_0: 138 tok/s (average of 5 runs, ±4 tok/s) Arc Pro B70 Q4_0: 94 tok/s (average of 5 runs, ±5 tok/s)
The 3090 leads. The 9070 XT is close. The Arc is significantly behind.
Tok/s on Llama 2 70B (Q4_0 and Q3_K)
Cost per million tokens (electricity + 3-year hardware amortization at 40 hours per week): RTX 3090 costs $0.38, RX 9070 XT $0.31, and Arc Pro B70 $0.61.
The 9070 XT wins on cost-per-token. The 3090 is competitive. The Arc is expensive.
Moving to Q3_K (higher precision) increases VRAM footprint to ~30 GB, which only the 3090 handles without reshuffling. Throughput gains are modest (3–5%), so the token-cost advantage doesn't justify the lost model flexibility on the smaller-VRAM cards.
Batch size scaling: RTX 3090 and RX 9070 XT scale linearly up to batch size 16. Arc Pro B70 hits diminishing returns at batch size 4. Batch processing widens the 3090 and 9070 XT's advantage.
Compute limits throughput on all three, not bandwidth—typical for current LLMs.
Cost-Per-Million-Token Calculation and Workload Profiles
Here's how to calculate true cost for your own setup:
Step 1: Measure active GPU power draw (GPU only, not the whole system) using nvidia-smi for NVIDIA, rocm-smi for AMD. Run it at your typical batch size and quantization level.
Step 2: Assume electricity cost of $0.15 per kWh (US average) and 40 hours per week usage.
Step 3: Amortize hardware over 3 years. Add annual cooling costs (thermal paste, pads, fans).
Step 4: Divide total 3-year cost by estimated total tokens: tok/s × hours × 52 weeks × 3 years.
The 9070 XT's lower power draw combines with its low purchase price to win this calculation. But the 3090's proven ecosystem and higher throughput win on reliability.
Which GPU for Your Workload
Your choice depends on three things: max context length needed, how much quantization quality you can sacrifice for speed, and driver maturity tolerance. When you're deciding on quantization level or figuring out which model fits your VRAM, the quantization guide will show you which compression level makes sense for coding, chat, and batch processing.
None of the three are suitable for real-time streaming inference >256 tok/s. If you need that, jump to RTX 4090 or multi-GPU setups—single GPUs under $1000 max out around 160 tok/s.
The 3090 is the safe, proven choice. The 9070 XT is the value play. The Arc Pro B70 is overspecced for single-GPU local use and should be skipped.
If You Need Stability and Breadth, Choose the RTX 3090
Pick the 3090 if you run multiple inference frameworks (vLLM, llama.cpp, transformers) interchangeably. Pick it if stability matters more than cutting 30 seconds off your token generation time.
Five-plus years of CUDA optimization means fewer surprises on niche model architectures—Mixture of Experts, sparse models, and experimental quantizations. You'll find working examples. The ecosystem has seen it.
Typical use: weekday coding assistant, weekend batch processing, occasional driver updates. Budget allocation: $900 (used 3090) + $150 (replacement cooler and thermal paste) = $1050 all-in.
If You Want Price Leadership and Newest Architecture, Bet on AMD
Pick the 9070 XT if you're comfortable with ROCm updates—they'll keep coming for the next two years, probably monthly. Choose it if you stick to one framework and test updates first.
Ollama added explicit 9070 XT support post-launch with strong benchmarks. The hardware is new; the driver story is improving faster than Arc's. Typical use case: local chat (Mistral, Llama 2 7B) and single batch job (weekend data processing). Not production inference with high uptime requirements.
Budget allocation: $649 (9070 XT) + $50 (PSU upgrade if needed) = $699 all-in. Pin HIP to 6.0+ before updating ROCm to avoid breaking drivers.