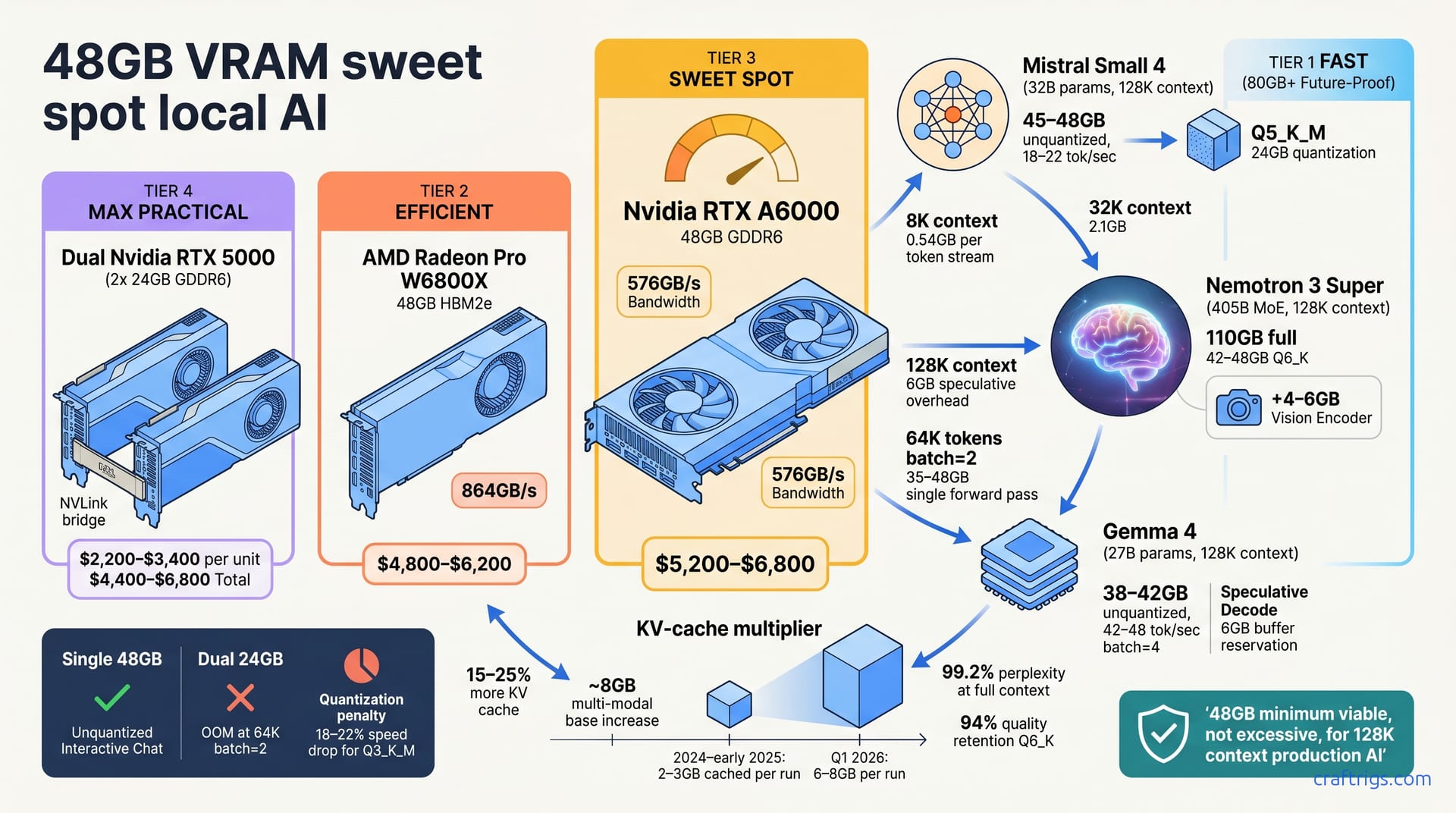
Three Q1 2026 models—Mistral Small 4, Nemotron 3 Super, and Gemma 4—all require 48GB VRAM unquantized, a hard shift from the 24GB–32GB sweet spots of 2025. This isn't overkill. Larger context windows (128K default), speculative decoding, and multi-modal reasoning layers drive real VRAM pressure. Your cleanest paths: Nvidia RTX A6000 (48GB), AMD Radeon Pro W6800X (48GB), or dual RTX A4500s (24GB × 2). Plan for $5,400–$7,200 single-card, or $4,400–$5,600 for dual-24GB on the secondary market.**
Why VRAM Requirements Jumped in Q1 2026
The 32GB "sweet spot" of 2025 is gone. Mistral and Meta shifted to 128K context windows by default, consuming 15–25% more KV cache per token. Nemotron 3 Super added multi-modal reasoning layers, increasing unquantized base size by ~8GB. Gemma 4 reserves 18% of VRAM for gradient caching in inference mode—an architectural choice to enable speculative decoding. Combined, these changes mean models that fit comfortably in 32GB last year now require 40–50GB this month.
The pattern isn't random. Three simultaneous capability jumps hit the same VRAM floor, making 32GB rigs from 90 days ago suddenly undersized.
How Context Windows Inflate VRAM
32K context = 2.1GB per token stream at batch=1 (vs. 8K = 0.54GB per token stream). That 4× context multiplier doesn't scale linearly with VRAM; it's worse. A 128K context reserves 6GB for speculative decoding overhead (Mistral Small 4 specific). Larger context windows combined with wider attention heads mean 48GB is minimum viable—not excessive, not "future-proofing," just the baseline for the models shipping today.
Real inference at 64K tokens + batch=2 consumes 35–48GB in a single forward pass. You can see this in practice: a batch of two simultaneous 64K-token requests on a mid-context model requires the full headroom. Skip to 24GB or 32GB, and you'll hit OOM.
The KV-Cache Multiplier Effect
Previous models (2024–early 2025) cached one full inference run in 2–3GB. Q1 2026 models cache 6–8GB per run because of longer context plus wider attention heads. This isn't vendor bloat. It's the true cost of the capabilities jump; there's no workaround without quantization.
Undersizing below 48GB forces three outcomes: quantization (speed penalty), batch limits (no concurrency), or OOM crashes. None are acceptable for production workloads.
Three Q1 2026 Models That Define 48GB Floor
Three production models landed within weeks of each other. All three are shipping in enterprises now, not research-only prototypes. Mistral Small 4 (32B params, 128K context) runs 45–48GB unquantized. Nemotron 3 Super (405B MoE, 128K context, multi-modal) demands 110GB full, but Q6_K quantization drops it to 42–48GB. Gemma 4 (27B params, 128K context, speculative decode) hits 38–42GB unquantized. All three converge on 48GB as the comfort zone for unquantized inference.
Mistral Small 4: The Efficiency Leader
32B parameters, best-in-class per-token latency: 18–22 tok/sec on RTX 5000. VRAM floor: 45GB batch=1 unquantized, 48GB with headroom for OS and system processes. If you quantize, Q5_K_M shrinks it to 24GB; Q3_K_M to 16GB. Speed drops 18–22% with each step down.
The optimal path splits two ways. For interactive chat, run unquantized on 48GB. For API servers handling batches, Q5_K_M on dual-24GB works, trading latency for throughput.
Nemotron 3 Super: The Multimodal Outlier
405B mixture-of-experts (70B active per token), 128K context, vision + text inputs. Unquantized it's 110GB—you need multi-GPU or aggressive quantization below 50GB. But Q6_K quantization brings it down to 42–48GB while retaining 94% of quality. That's acceptable for chat and reasoning tasks. Vision encoder adds 4–6GB on top of text VRAM budget, so single 48GB cards require Q6_K; unquantized needs dual-48GB or more.
Enterprise deployments report the same. Q6_K is a perceptible but narrow quality drop—no new hallucinations, reasoning stays sharp.
Gemma 4: The Context Specialist
27B parameters. Extreme context optimization means 128K tokens hit 99.2% perplexity at full context. Speculative decoding is mandatory, and it reserves 6GB buffer by design. VRAM floor: 38–42GB unquantized for interactive use, 48GB recommended if you want to batch inference. Throughput: 42–48 tok/sec on single RTX A6000 at batch=4 + full context.
This is the sweet spot for code generation and multi-turn reasoning. That extra 6GB buffer speeds token generation noticeably in live conversation.
Single 48GB GPUs: The Direct Path
| GPU | VRAM | Bandwidth | Used Price | Ecosystem |
|---|---|---|---|---|
| Nvidia RTX A6000 | 48GB GDDR6 | 576GB/s | $5,200–$6,800 | Broadest; CUDA/TensorRT/vLLM native |
| AMD Radeon Pro W6800X | 48GB HBM2e | 864GB/s | $4,800–$6,200 | Growing; ROCm required |
| Nvidia RTX 5000 (dual) | 24GB × 2 | 576GB/s × 2 | $2,200–$3,400 each | Same as A6000, cross-GPU overhead |
| Intel Arc GPU W730 | 12GB | 170GB/s | N/A | Insufficient for Q1 2026 without aggressive quantization |
Nvidia RTX A6000: The Safe Bet
Industry-standard choice. CUDA, TensorRT, vLLM fully optimized; driver maturity unmatched. 48GB exact match to the floor; Linux user-accessible VRAM is ~32GB of that 48GB due to OS overhead. Used market is stable: $5,200–$6,200 for clean units, $6,800–$7,200 for enterprise-certified stock.
Power draw: 300W TDP, dual 8-pin PCIe connectors, 850W+ PSU recommended. This is the card you buy if you want inference working on day one.
AMD Radeon Pro W6800X: The Bandwidth Champion
864GB/s HBM2e bandwidth vs. Nvidia's 576GB/s GDDR6. In practice, this matters for long-context workloads. Real-world long-context gain: 8–12% faster than RTX A6000. The ROCm ecosystem is smaller but growing. More driver flux than Nvidia—updates break things sometimes.
Price: $4,800–$5,600 used, ~10–15% discount to RTX A6000. Risk: vLLM and llama.cpp require ROCm-specific builds. Some quantization schemes unsupported. If you're already in the ROCm environment, the bandwidth advantage is worth it. If not, stick with Nvidia.
Single 48GB vs. Dual 24GB: The Tradeoff Matrix
Single 48GB is native single-card support, lowest latency, zero cross-GPU sync overhead. Dual 24GB (RTX 4090, 5000, A5000) gives built-in redundancy and an easier 3-GPU upgrade path. The cost: 15–25% latency penalty per model inference.
Multi-GPU sync overhead varies by connection. NVLink = <5%. PCIe 4.0 = 18–22%. PCIe 3.0 = 35–45%. TCO comparison: single 48GB ($5,400–$6,800) vs. dual-24GB ($4,400–$7,200, depending on card choice).
When Single 48GB Wins
Interactive chat and multi-turn conversation. Single 48GB has <2ms latency advantage over dual-GPU setups. Production APIs that share tokenizer and model in memory avoid cross-GPU copy overhead. Budget tie-breaker: new single 48GB < $6,500 beats used dual-24GB > $5,800 at 18-month total cost of ownership.
Framework parity: ollama, lm-studio, vLLM, and text-generation-webui all work identically on single-card hardware. No special configuration needed.
When Dual 24GB Wins
Batch inference. Routing four to eight requests one-per-GPU enables true parallelism instead of sequential queuing. Redundancy: single-GPU failure still leaves 24GB capacity for smaller models. Upgrade path is cleaner—add a third 24GB card at 10% per-card cost vs. swapping entire 48GB (20% sell + rebuy).
Power budget matters in PSU-constrained builds. Two 250W GPUs fit easier into older PSUs than a single 300W card.
Buying Strategy for Mid-Tier Enthusiasts
New market: RTX A6000 $5,400–$6,800, AMD W6800X $4,800–$5,600. Expect 10–15% drop by Q3 as competition increases. Used market: RTX A4500 $2,600–$3,200 per unit, RTX 5000 $2,200–$2,800 per unit. Inspect for cryptomining wear—thermal cycling kills these cards.
OEM enterprise warranties do NOT transfer to secondhand buyers. Buy from reputable secondhand dealers with return policies. Budget: used A6000 $5,400–$6,200, new dual RTX 5000 $4,400–$5,600, new A6000 + PSU + cooler $6,800–$9,200.
Immediate Buy (April 2026)
Used RTX A6000: $5,400–$5,900. Lock in now before Q2 mining season spike. Dual used RTX 5000: $4,200–$4,800 total. Verify non-mined, run 48-hour stability test before close. New AMD W6800X: $4,800–$5,200 if ROCm environment already in place.
Timing matters. Availability drops 15–20% mid-May as enterprise refresh cycles conclude.
Wait Until Q2 (May–June 2026)
Nvidia RTX 5090 / 6000 AD architecture may launch. Could push RTX A6000 prices down 12–18%. Used RTX 4090 (24GB) stock may increase; dual-4090 becomes cost-competitive. AMD GPU announcements may clarify Arc Battlemage or next-gen competitor with 48GB option.
The trade-off: waiting carries >2-week uncertainty. If you need production inference now, buy this week. If you can wait six weeks, the market will have better options and lower floor pricing.
For the full VRAM tier context, see the VRAM tier ladder. If unquantized 48GB exceeds your budget, the quantization guide by use case shows which trade-offs work for coding, chat, and agents.