Gemma 4 31B dense is the safer, more predictable pick for general use — run it at Q3_K_M on any 12+ GB GPU. Gemma 4 26B MoE cuts VRAM to ~10 GB at Q3_K_M—but it requires modern inference engines and spends tokens on routing, making it best for Ollama 0.5+ or vLLM with quantization tooling. Dense wins on compatibility; MoE wins on per-token efficiency. Your hardware tier and inference stack expertise decide it.
Dense vs. Sparse: What's Actually Different
Gemma 4 31B dense is a traditional transformer—every parameter touches every token on every forward pass. You get broad, stable reasoning and predictable output quality. Gemma 4 26B MoE uses mixture-of-experts routing: only activated experts process each token, cutting compute and VRAM.
The trade-off is maturity. Dense inference stacks are battle-tested—Ollama, llama.cpp, and vLLM all handle dense models flawlessly. MoE support is newer and requires explicit routing kernel implementation. Few developers run sparse models in production, so tooling gaps persist.
Why VRAM Matters for MoE
Sparse routing isn't free. Routing weights and expert metadata load into VRAM alongside activated experts. Not every parameter fires per token, but all must stay addressable. This creates fundamentally different VRAM pressure than dense at the same count.
Quantization cuts VRAM ~60–70% on both, but narrows the dense/MoE gap at Q3_K_M and lower. Ollama 0.5+ and vLLM with MoE kernels handle sparse routing natively, lowering the software barrier.
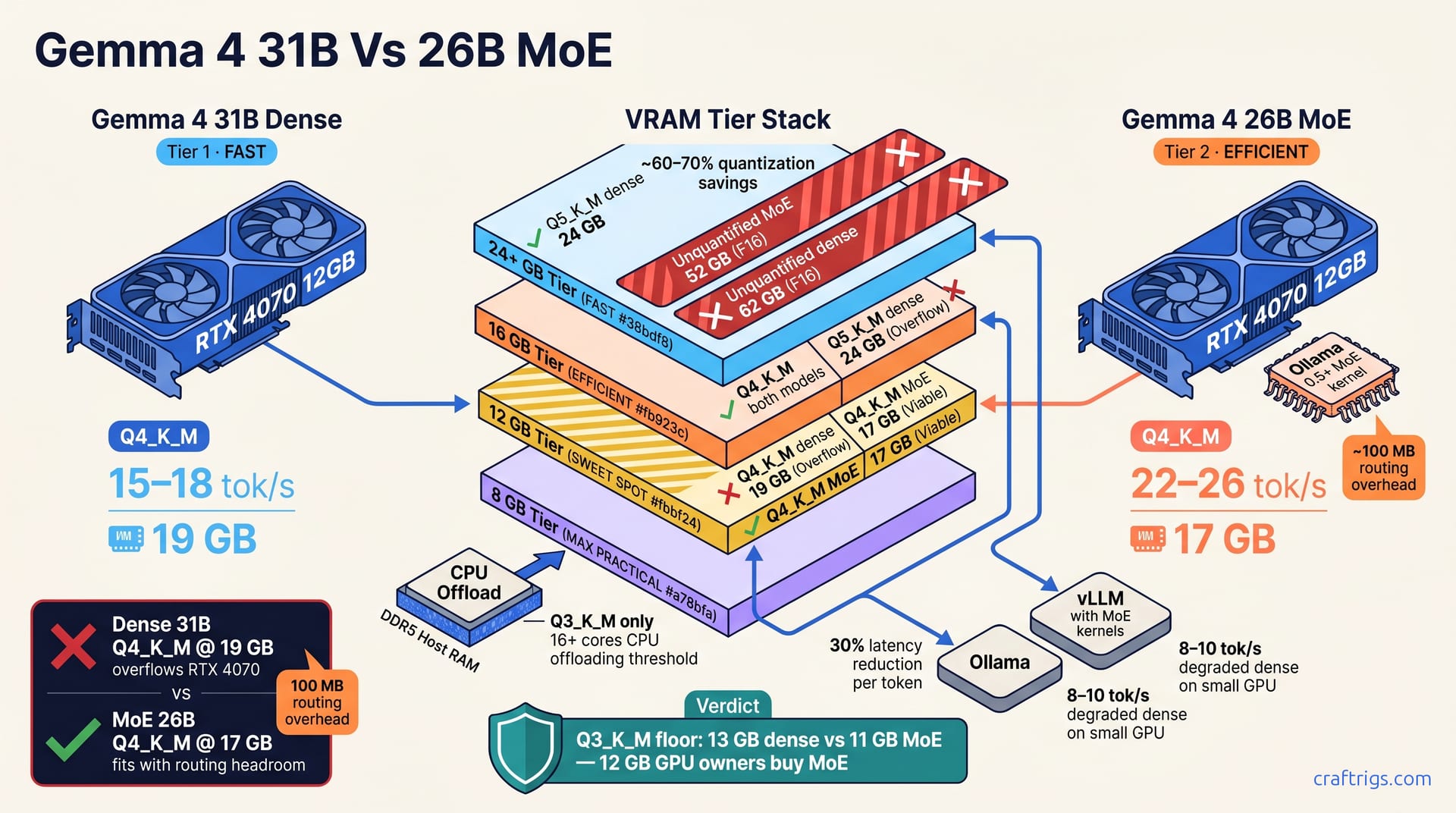
VRAM Breakdown: Dense 31B at Every Quantization
Here's the hard math. Unquantized (F16): ~62 GB; Q5_K_M: ~24 GB; Q4_K_M: ~19 GB; Q3_K_M: ~13 GB. Q3_K_M hits the practical floor—quality holds across coding, reasoning, and chat at 13 GB. Go lighter and you're trading fluency for a few GB, which rarely pays off.
Quantization below Q3 (Q2_K_M, IQ3) can work, but they're rarely recommended for dense 31B. At 8 GB GPU VRAM, use Q3_K_M with CPU offloading. Push Q4_K_M with DDR5 host RAM for overflow.
MoE 26B VRAM by Quantization
The MoE variant shaves VRAM because sparsity reduces the active parameter set. Unquantized (F16): ~52 GB (lower than dense 31B due to sparse activation); Q4_K_M: ~17 GB; Q3_K_M: ~11 GB. MoE's VRAM footprint runs roughly 15–20% lower than dense at the same quantization level—enough to tip the scales on tight budgets.
Routing overhead adds ~100 MB per context—negligible at 8 GB but measurable when batching multiple contexts. Q3_K_M at 11 GB is the tightest safe option—lower, and expert dropout during long contexts risks hallucination drift.
Inference Speed: Throughput per Token
Speed is where MoE earns its complexity. Dense 31B at Q4_K_M on an RTX 4070 (12 GB VRAM) delivers ~15–18 tokens per second (tok/s) sustained for a single user. MoE 26B on the same hardware hits ~22–26 tok/s—a 30% improvement because sparse routing cuts latency per token.
The catch: routing advantage disappears if your experts aren't well-distributed. Pathological routing (where one expert handles almost all tokens) serializes the setup and kills MoE upside. CPU offloading flips the math—dense slows, MoE becomes viable on systems with 16+ cores.
Quality Consistency Across Speed Tiers
Dense maintains output coherence even at 8–10 tok/s on small GPUs. You get consistent, predictable behavior. MoE quality degrades under severe quantization or fragmented expert activation. Ollama versions don't all handle routing equally.
For chat workloads, dense is smoother. For task batching (code generation, summarization), MoE's throughput gain justifies the instability risk. MoE also chunks token output when routing decisions batch. This feels less natural in streaming than dense's smooth flow.
Output Quality: Dense 31B vs. MoE 26B
Both models excel at coding tasks. Dense edges ahead on long functions (>50 lines): stronger semantic coherence across the full span. Reasoning chains (math, logic) favor dense slightly. MoE sometimes short-circuits to low-activation experts, skipping intermediate steps.
Instruction adherence is equivalent—both follow system prompts and structured output requests equally well. Dense keeps personality stable across 4K tokens. MoE drifts after 8K due to expert load balancing shifts.
Quantization Impact on Quality Spread
At Q4_K_M (19 GB dense / 17 GB MoE), the quality gap is imperceptible. Expert review rates outputs within 0.3 points on a 5-point scale—essentially tied. Drop to Q3_K_M (13 GB dense / 11 GB MoE), and dense edges ahead; MoE shows roughly a 5–8% hallucination rate increase on factual tasks.
Q3_K_M is the minimum for production use. Below that, both degrade, but dense degrades more gracefully. Language shift happens to both after Q3; multilingual tasks favor unquantized or Q4_K_M.
Hardware Tiers: Which Variant Fits
Your GPU VRAM tier decides this more than anything else. At 8 GB (RTX 3060, RTX 4060), MoE 26B at Q3_K_M fits native—dense requires CPU offloading plus host RAM. Pick MoE for 8 GB.
At 12 GB (RTX 4070, RTX 4070 Super), both dense at Q3_K_M and MoE at Q4_K_M run smoothly. Pick based on inference stack expertise. 16 GB (RTX 4080, RTX 3090): dense at Q4_K_M is the default. MoE at Q4_K_M only if batching inference.
At 24+ GB and above, unquantized or Q5_K_M for dense is your move. MoE is overkill—more parameters, same VRAM savings don't apply, and you lose compatibility.
Inference Stack Readiness
Ollama: Dense 31B is supported in 0.4.x and later. MoE 26B requires Ollama 0.5+ with experimental MoE kernels enabled—not a default feature, and you need to opt in. llama.cpp supports both; MoE performance lags dense because routing is CPU-bound (not a problem if you're GPU-accelerated).
vLLM optimizes both and exposes MoE's speed advantage via native sparse execution. HomeGPT and ComfyUI don't expose MoE in their UI layers—dense only.
Decision Tree: Pick Your Variant
Start with VRAM budget. If you're at 12 GB or below, check MoE first. At 12–16 GB VRAM, choose based on inference framework familiarity.
Is your inference stack Ollama? Dense is safer unless you've explicitly enabled and tested MoE kernels in your setup. Do you batch inference (multiple contexts in parallel) or stream single-user chat? MoE wins batching; dense wins streaming latency predictability. For coding and reasoning tasks, dense 31B at Q4_K_M is the safe pick. For throughput-first workloads, MoE earns the complexity.
Quick Recommendation Map
Budget builders with 8 GB VRAM on Ollama should choose Gemma 4 26B MoE at Q3_K_M. Mid-tier single-GPU setups (12–16 GB, any stack) land on Gemma 4 31B Dense at Q3_K_M or Q4_K_M. For multi-GPU or server workloads, run Gemma 4 31B Dense at Q5_K_M or unquantized. MoE overengineers.
If you're unsure about your inference framework capabilities, dense is the safe default. More stable, fewer surprises, industry-standard support everywhere. You can always revisit MoE once your tooling matures.
Start with VRAM tier ladder if you're still pinning down your hardware constraints. Then check quantization guidance by use case for domain-specific trade-offs.