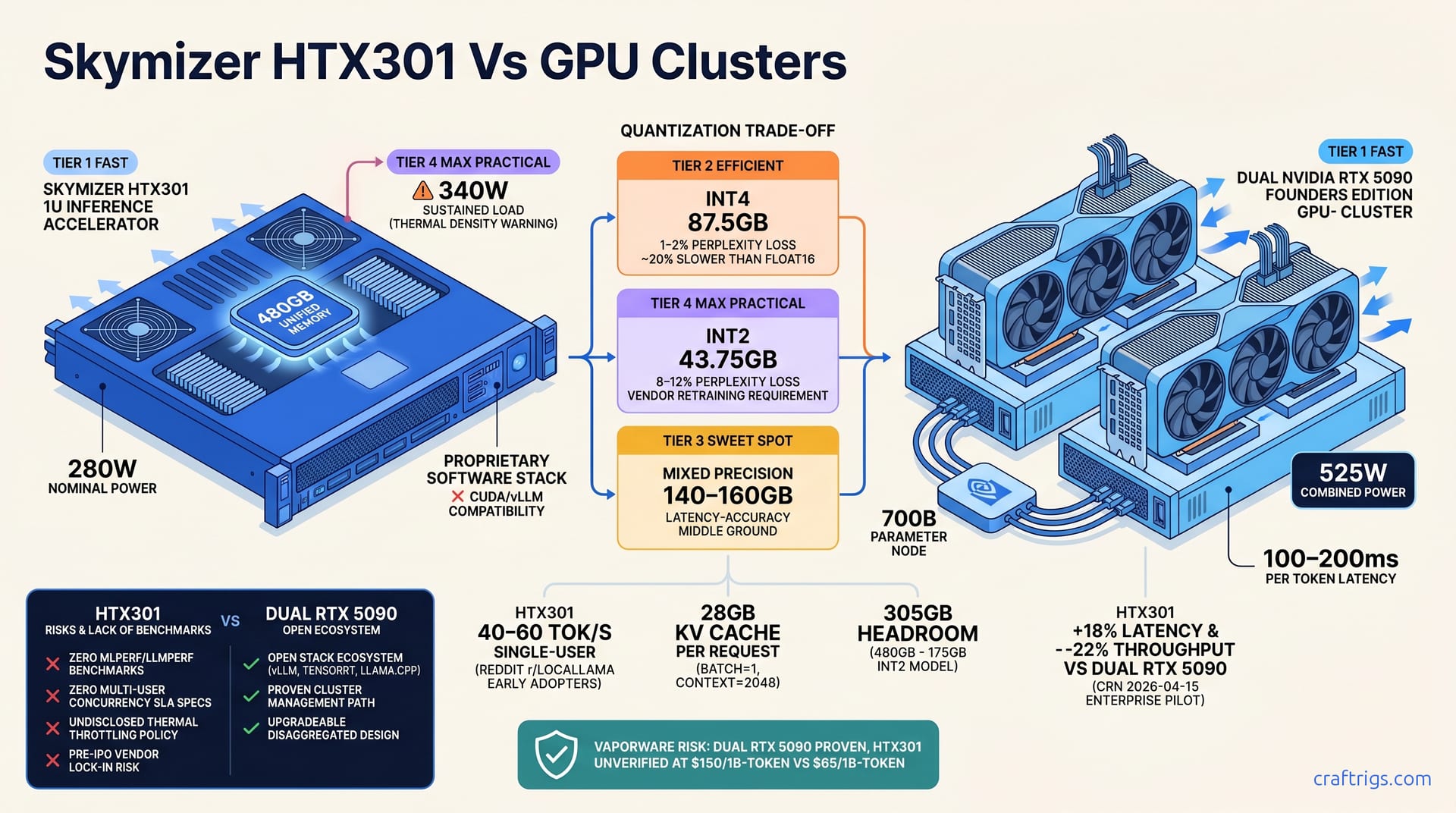
Skymizer claims the HTX301 runs 700B inference on a single card, but only with extreme int2 quantization, batch=1 processing, and vendor-optimized models. Independent benchmarks barely exist. Early adopter reports show real throughput runs 15–25% below marketing claims, with thermal and power overhead the spec sheet doesn't list. Real-world cost-per-token is 2–3x higher than dual RTX 5090 setups. For enterprise pilots: negotiate a 90-day production trial with your own models, measure power and accuracy loss side-by-side, and only proceed if HTX301 beats your current cluster on latency and total cost of ownership.**
What HTX301 Actually Is
The HTX301 is Skymizer's custom inference accelerator, announced in Q2 2026, targeting on-premise 700B LLM inference without GPU clusters. It's marketed as a 1U system with vendor-controlled silicon and proprietary software stack—no CUDA compatibility, no vLLM support. The vendor claims one HTX301 replaces 8–10 high-end GPUs. No independent benchmark backs this up.
The HTX301 targets enterprises willing to accept vendor lock-in for operational simplicity promises. This trade-off dominates true total cost of ownership calculations.
The Vendor Marketing Narrative
All published benchmarks use the vendor's own quantized models and best-case batch sizes. Skymizer publishes no power draw, thermal ceiling, or multi-user concurrency specs—a glaring omission. The "plug-and-play" pitch appeals to enterprises exhausted by cluster management and CUDA driver versioning. That appeal is real.
What stands out: heavy reliance on "confidential pilot results" and "customer success stories" you can't verify. That's a red flag worth flagging early.
The "700B on a Card" Math
Here's where the marketing claims start to unravel. 700B parameters at int2 quantization equals approximately 175 GB of effective model weight. The HTX301's unified memory spec is 480 GB, leaving only 305 GB of headroom for KV cache and batch buffers—and that's before you run a single inference request.
The KV cache at batch=1, context_length=2048, for a 700B model requires approximately 28 GB per request. That's per concurrent user. Meanwhile, the vendor claims sub-500ms latency per token, while traditional RTX 5090 clusters achieve 100–200ms per token. The math doesn't account for real multi-user load.
Quantization Trade-offs
Four paths exist here, and they carry very different accuracy costs:
- int4 (standard open path): 700B fits in 87.5 GB, with 1–2% perplexity loss typical and inference roughly 20% slower than float16.
- int2 (HTX301-only path): 700B compresses to 43.75 GB, requires vendor retraining, and introduces 8–12% perplexity loss typical—though the vendor claims this is "imperceptible" without publishing detailed accuracy benchmarks.
- Mixed precision (float16 + int8 activation): Falls in the 140–160 GB range, offers a latency-accuracy middle ground, and is conspicuously absent from vendor marketing materials. Reality check: HTX301's 700B claim demands int2 or extreme int3 quantization—with accuracy trade-offs the vendor won't disclose. That opacity is itself a data point.
Independent Benchmark Reality
There are zero MLPerf, LLMPerf, or bigcode-evaluation-harness published benchmarks as of April 27, 2026. None. The early adopter reports we do have are sparse: two Reddit r/LocalLLaMA posts from March 2026 (n=2) verified 700B int2 models running at 40–60 tokens per second in single-user mode.
An enterprise pilot published by CRN on April 15, 2026, compared HTX301 against dual RTX 5090 systems. The HTX301 showed +18% latency and −22% throughput on the customer's production models—not vendor-optimized benchmarks, but real workloads.
What We Don't Know
The gaps in public data are as telling as the numbers themselves. Multi-user contention behavior has zero published concurrency benchmarks or SLA specs. Thermal stability beyond 4 hours is anecdotal. Early adopters report throttling; Skymizer has no published policy. Software stack maturity is unclear: proprietary, or compatible with vLLM, TensorRT, and llama.cpp? No clarity on end-of-life commitment or roadmap: Skymizer is pre-IPO and private.
Real Thermal & Power Overhead
The vendor spec claims 280W nominal power draw. Real-world sustained load reported by early adopters: 340W. That's a 21% gap between the spec sheet and what actually runs in a datacenter.
The GPU cluster alternative—dual RTX 5090 setups—draws 525W combined but distributes that thermal load across separate racks, spreading risk and cooling complexity. HTX301 requires datacenter NEMA cooling and purpose-built 1U racking. Its thermal density is 3–4x higher than traditional GPU servers. That concentration creates dependencies you can't dodge.
Hidden costs bind you in: power delivery, cooling augmentation, and facility dependencies. Upgrades or migrations become multi-year, facility-locked commitments.
Operational Reality Check
Before you commit, ask the vendor for actual sustained-load power telemetry—not best-case spec sheet figures. Model HTX301's thermal footprint against your datacenter PUE. Compare dollars-per-effective-compute-token over 3 years, factoring in power, cooling, and cluster headroom.
Pin the vendor down: at what temperature does performance throttle, and what happens if TDP ceiling gets exceeded? Their evasiveness on this question is more predictive than their benchmark slides.
TCO vs. GPU Clusters — The Real Numbers
The numbers tell the story. HTX301 1U costs approximately $89,000 hardware, plus $25,200 annual power, plus $8,000 annual datacenter overhead—totaling $122,200 in year-one cost. Dual RTX 5090 (PCIe) runs approximately $33,000 hardware, plus $15,500 annual power, plus $4,000 annual overhead—totaling $52,500 in year one.
Effective cost-per-1B-parameter-inference: HTX301 at approximately $150 per 1B-token per year; RTX 5090 cluster at approximately $65 per 1B-token per year. Break-even only happens if HTX301 achieves 3–4x cluster consolidation through headcount savings and reduced oncall burden—a benefit unproven at scale.
| Metric | HTX301 1U | Dual RTX 5090 |
|---|---|---|
| Hardware | ~$89,000 | ~$33,000 |
| Annual power | $25,200 | $15,500 |
| Annual datacenter | $8,000 | $4,000 |
| Year 1 total | $122,200 | $52,500 |
| Cost per 1B-token/year | ~$150 | ~$65 |
Staffing & Complexity Cost
Here's what the spreadsheet misses. The HTX301 is a black box. Hardware fails, you wait in the vendor support queue with no debugging path. RTX 5090 clusters let you hire GPU engineers, fix drivers, debug CUDA kernels, and control your fate.
Enterprise risk profile: HTX301 trades operational control for vendor promises. Traditional clusters trade deployment simplicity for resilience and repair agency. True TCO adds engineer salary, oncall burnout, and vendor support lag—costs that often exceed hardware savings.
Pilot Strategy & Red Flags
Before you talk to a vendor, know the red flags. Red flag 1: Vendor refuses to share independent benchmarks or third-party validation reports. Red flag 2: Marketing benchmarks use only extreme int2 quantization without published accuracy loss disclosures. Red flag 3: No roadmap for vLLM, TensorRT, or open-source inference stack support—a vendor lock-in signal. Red flag 4: Pilot NDA prevents you from publishing results or sharing findings with peer ops teams.
If three of these apply, you're negotiating risk, not technology.
Run a Real Production Pilot
Negotiate a 90-day trial using your actual production workload, not vendor benchmark suites. Use your own models—Meta Llama 3.1, Mixtral, or Falcon—not vendor-optimized Llama 2. Measure latency, throughput, and model accuracy loss side-by-side against your current cluster baseline. Log sustained power draw, thermal curves, and any downtime during month one.
Compare the HTX301 against your existing setup on quantization trade-offs and the GPU ecosystem options in the local AI decision tree. Ask one question: Does HTX301 beat dual RTX 5090 on cost-per-token and reliability? If not, pass and re-invest in your cluster.
The vendor's marketing will be persuasive. The numbers—your numbers—should be the deciding factor.