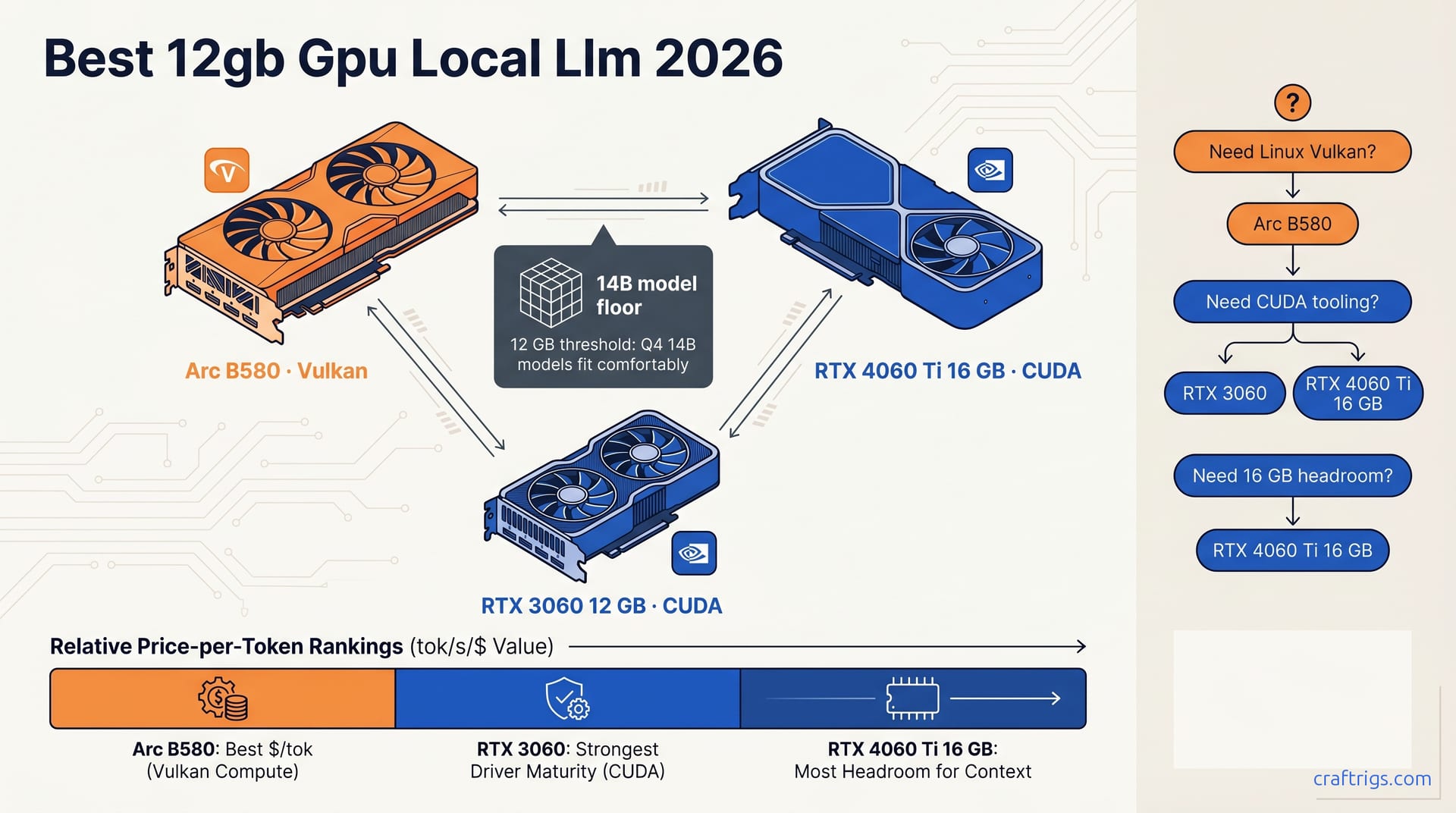
TL;DR — In 2026, the best 12GB GPU for local LLMs depends on your OS and your stack. RTX 3060 12GB used ($240–$280) is still the king for CUDA-on-anything. Arc B580 ($260) wins on price-per-token if you're Linux-comfortable and don't fear Vulkan. RTX 4060 Ti 16GB ($430) is the upgrade pick that buys you a full extra 14B's worth of headroom.
Why 12GB Is the Sweet Spot for 14B
Q4_K_M of a 14B model is 8–9GB of weights. Add KV cache for 8K context and you're at 10–11GB. 12GB fits with breathing room; 8GB doesn't. Once you cross into 14B-at-Q5 or 14B-at-32K-context, you want 16GB — but that's a different buying decision (see the RTX 5060 Ti 8GB vs 16GB comparison for that bracket).
This is the band where the 8GB VRAM 2026 tooling wave made things complicated — 8GB cards got better, but 12GB still buys you a category jump, not an incremental improvement.
Tok/s and Price-per-Token
Rough numbers on Qwen 3.5 14B Q4_K_M, 2048-token prompt, single batch:
- RTX 3060 12GB — 28–34 tok/s on CUDA. $240–$280 used. Price-per-token: best in class.
- Arc B580 12GB — 22–28 tok/s on Vulkan with
GGML_VK_DISABLE_COOPMAT=1. $250–$270 new. Slightly slower but new-card warranty. - RTX 4060 Ti 16GB — 35–42 tok/s on CUDA, plus 4GB extra headroom. $400–$440 new.
The 3060 is still the value floor. The B580 is competitive on price, but only after you tune Vulkan correctly — and that's not zero work.
The dedicated RTX 3060 12GB local LLM guide walks through the 3060 in full. For Arc, the B580 Vulkan setup guide covers the flags that turn an unstable card into a stable one, and the B580 review covers the day-2 experience.
When Vulkan Beats CUDA (And When It Doesn't)
Vulkan wins when:
- The card has no CUDA (Arc, RDNA where ROCm is unstable).
- You're on Linux with current Mesa drivers.
- You don't need flash-attention or vLLM throughput.
CUDA wins when:
- You want flash-attention, FA2, or any custom kernel.
- You need vLLM-class batched serving.
- You're on Windows. Vulkan on Windows is fine for llama.cpp but loses ~10–15% to CUDA in the same setup.
If you're running a single chat session in llama.cpp on Linux, Vulkan parity is real. If you're running anything more involved, CUDA still leads.
Buying Decision Tree
- Budget under $300, Linux-comfortable, new card preferred: Arc B580. Accept Vulkan, save $30.
- Budget under $300, want zero-config CUDA: RTX 3060 12GB used. Still the right answer.
- Budget $400–$450, want headroom and stability: RTX 4060 Ti 16GB. The extra 4GB lets you push 14B to Q5 or extend context to 16K without sweating.
- Windows-primary: Skip Arc unless you're willing to debug Vulkan crashes. Go RTX.
- Linux-primary with mixed workloads: Arc B580 is a real option for the first time.
The 12GB tier hasn't been this competitive in years. Pick by stack and OS, not brand loyalty.