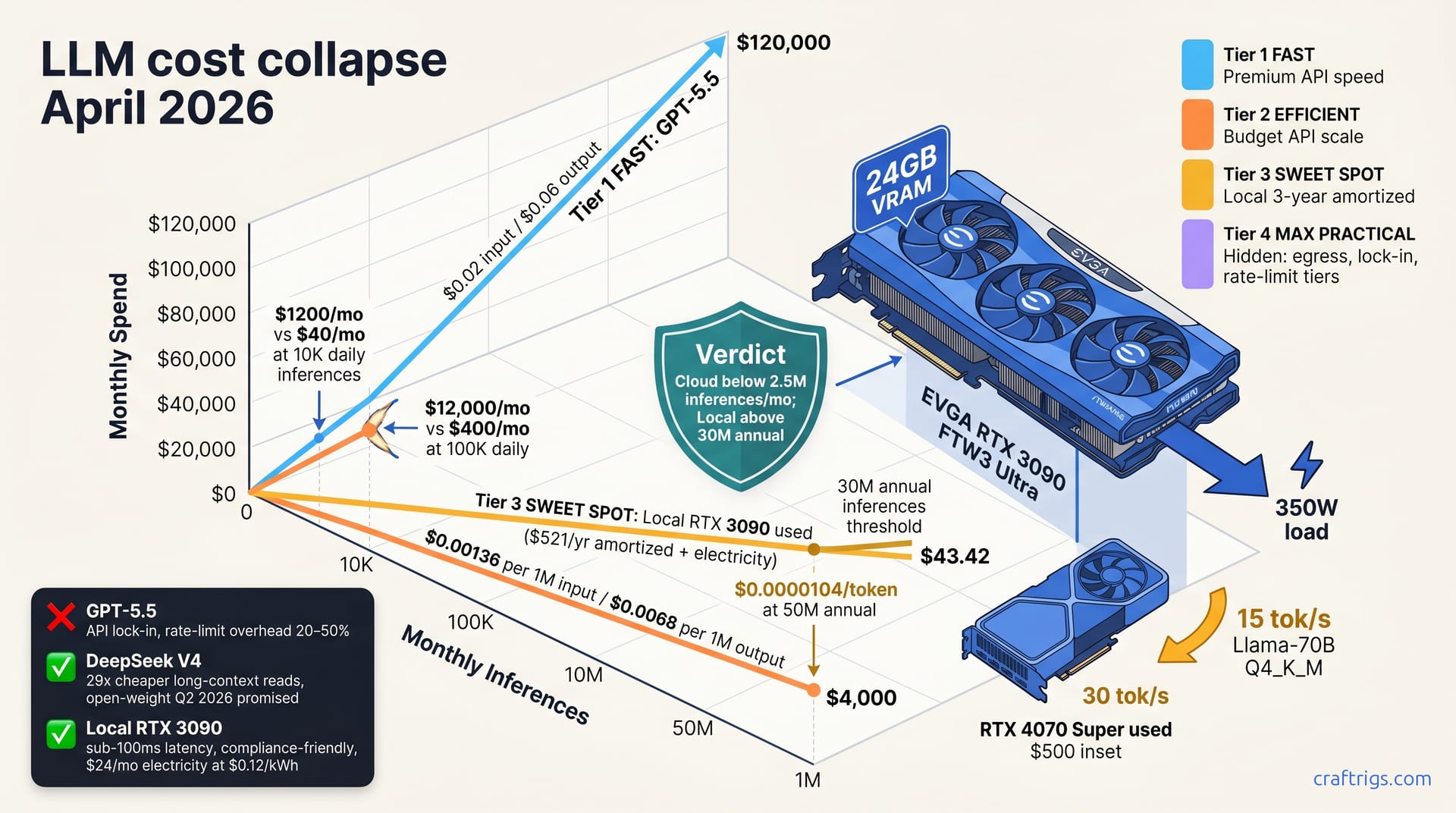
GPT-5.5 dropped to $0.02/1K input tokens; DeepSeek V4 cut prices 50%. Local hardware breaks even at scale. Run over 3 million inferences/month and RTX 3090s beat cloud APIs. This guide walks the new break-even points (cloud vs. the hidden costs of both and a decision framework to act before Q2's pricing shifts. Startups under 2 million monthly tokens stay cloud for simplicity. Scale-ups and research labs should budget for hardware now.
What Shifted in April 2026
Two pricing shocks landed in the same week, and they've collapsed the entire economic case for cloud-only inference at mid-scale. On April 15, OpenAI released GPT-5.5 at $0.02/1K input tokens and $0.06/1K output tokens. Three days later, DeepSeek cut API pricing 50%, moving to $0.00136 per 1M input tokens and $0.0068 per 1M output tokens. Both moves compress the margin between premium closed-weight models and open-weight alternatives available via API. The pricing war cascades. Claude, Gemini, and Llama APIs all face margin pressure.
GPT-5.5 Launch Specifications
GPT-5.5 ships with 400B parameters, multimodal (text and vision), and a 128K context window. Training data cutoff is April 2026; it's available via API only with no open-weights release planned. It outperforms GPT-4 Turbo on reasoning and code benchmarks. Inference cost is the only variable you control—the model itself is fixed.
DeepSeek V4 Price Cut Anatomy
Here's what tightened the margin. DeepSeek V4 dropped to $0.00136/1M tokens from V3's $0.00272—the industry's cheapest 32K-context option. Architecture: 236B parameters, mixture-of-experts with 32 experts, ~37B active per token. Closed API weights are live now; an open-weight release is promised for Q2 2026. This move demonstrates that open-source competition directly pressures closed-model pricing.
Cloud Cost: The New Calculation
Let's anchor the numbers. GPT-5.5 at $0.02 input + $0.06 output averages ~$0.04 per 1K tokens for typical mixed workloads. DeepSeek V4 costs 29x less per token than GPT-5.5 on long-context reads like PDF summarization. At a $1000 monthly budget, you buy either 25 million tokens on GPT-5.5 or 735 million tokens on DeepSeek V4. Cost scales linearly with traffic; no upfront hardware investment required.
Monthly Spend by Inference Volume
| Workload | Inferences/Day | GPT-5.5 Monthly | DeepSeek V4 Monthly |
|---|---|---|---|
| Small team | 10K | $1,200 | $40 |
| Scale-up | 100K | $12,000 | $400 |
| High-traffic service | 1M | $120,000 | $4,000 |
These assume 200 tokens average output per inference. Adjust proportionally for your workload.
Hidden Cloud Costs Not in the Per-Token Rate
The per-token rate is a lie if you ignore everything else. API rate limits require business tiers, adding 20–50% overhead on stated pricing. Vendor lock-in runs deeper than price: unilateral pricing changes and feature deprecation without warning. Latency and compliance matter too: multi-second round trips to the cloud vs. sub-100ms local inference; regulated environments often forbid external API calls entirely. Egress charges pile on if you move data in bulk for auditing, retraining, or compliance.
Local Hardware Economics: What It Actually Costs
Used RTX 3090 on the secondary market costs $600–$800 and runs Llama-70B with 4-bit quantization at 15 tokens per second. Electricity for 24/7 inference at $0.12 per kWh runs ~$24/month (RTX 3090 draws 350W at typical load). Three-year amortized cost is ~$233/year hardware + $288/year electricity = $521/year total. That's $0.0000104 per token for 50 million annual tokens. Positive ROI needs 30M+ annual inferences (2.5M/month). Below that, cloud wins on simplicity.
Hardware Cost Tiers with Real Token Throughput
| GPU | Used Market Price | Tokens/Sec | Annual Amortized | Cost per Token (50M annual) |
|---|---|---|---|---|
| RTX 4070 Super | $500 | 30 | $139 | $0.0000278 |
| RTX 3090 | $700 | 20 | $194 | $0.0000388 |
| RTX 6000 Ada | $2,500 | 80 | $694 | $0.0000139 |
Three-year lifespan assumed. Used GPU market shows 25–35% resale value at end-of-life.
Ops Costs Vendors Omit from Break-Even Math
This is where cloud's SLA guarantees earn their keep. Cooling infrastructure: add $50–$100/month for proper ventilation and thermal headroom. Maintenance labor adds up: driver updates, VRAM replacements, crash debugging—~$500/year. Downtime risk is the silent killer: single GPU failure equals 0% throughput. Cloud has built-in redundancy and SLA guarantees. Colocation adds $200–$500/month, making local uncompetitive vs. cloud. cloud.
Break-Even Thresholds: When Local Beats Cloud
On-premises RTX 3090 breaks even vs. DeepSeek V4 at 8 million monthly inferences (267K per day). The same hardware breaks even vs. GPT-5.5 at just 2.5 million monthly inferences—a typical mid-market chatbot workload. If you need sub-50ms latency or offline-only capability, local wins on SLA regardless of cost. Break-even assumes home deployment. Colocation adds $6K+ annually and kills the local advantage.
Break-Even Monthly Inference Count by Model
| Comparison | Break-Even Monthly Inferences | Hardware |
|---|---|---|
| vs. GPT-5.5 ($0.04/1K avg) | 2.5M | RTX 3090 |
| vs. DeepSeek V4 ($0.001/1K) | 8M | RTX 3090 |
| vs. Above these thresholds, local hardware saves 3–10x annually on inference costs. |
Quick Break-Even Calculator Workflow
Gather annual inference count and average output tokens per inference from your API logs. Multiply to get total annual tokens, then divide by 50 million (rough budget for RTX 3090). If the quotient exceeds 1.0, local pays for itself in three years. If it's below 0.5, cloud is cheaper and simpler. Factor in ops overhead—add 20–30% if in-house staffing isn't available.
Decision Framework: Cloud vs. Local vs. Hybrid
Outcome depends on five factors: monthly inference volume, token count per call, required latency SLA, data sensitivity, and 12-month growth trajectory. Workloads under 5 million monthly inferences should stay cloud—ops overhead kills savings. Hybrid architectures (cloud peak, local baseline) are cost-optimal for traffic with 20–80% variance. Lock in long-term cloud discounts now; DeepSeek API may not stay at 2026 pricing if demand surges.
Step 1—Measure Your Current Baseline
Export API logs for the past 30 days and count inferences by model. Measure average input/output token counts. Project 12-month growth based on your product roadmap and user-acquisition targets. Identify latency-critical paths (user-facing) vs. batch workloads (async, offline-tolerant). Note any regulatory constraints: HIPAA, GDPR, or FedRAMP may forbid external API calls.
Step 2—Run the Math and Surface the Opportunity
Cloud annual cost = (monthly inferences × avg output tokens × 12) × $/1K-token rate. Local annual cost = (amortized hardware + electricity + ops) + (token count × $0.0000104). Calculate payback period: (hardware cost) ÷ (cloud cost − local cost per year). If payback is under 24 months and latency SLA is achievable, move to Step 3.
Step 3—Pilot Local in Staging and Measure
Buy one used RTX 3090 and set it up in a staging environment with the same workload distribution as prod. Route 5–10% of traffic to local, then measure P50 and P99 latencies and log any errors. Monitor for one week; if P99 latency stays below 500ms and error rate stays below 0.1%, proceed to Step 4. If latency or error rates are unacceptable, try hybrid: local for batch, cloud for real-time.
Step 4—Commit or Stay Cloud
If the pilot clears SLA and ROI is positive in 24 months, commit to local and transition traffic monthly. For hybrid workloads (bursty traffic, seasonal peaks), use cloud as autoscaling backup and local as baseline. If cloud is cheaper or ops overhead is unacceptable, stay cloud. Use savings to ship features. Check out the RTX 3090 buyers checklist if you're moving forward with hardware.
Who Should Act Now in April 2026
Pre-Series-A startups should stick with DeepSeek + Claude Opus API mix (runs under $500/mo) and stay cloud for 12 more months while scaling. Series B/C scale-ups: local break-even crossed in April 2026. Budget for RTX 3090 hardware by Q2 and pilot staging now. Research and training teams: switch to local clusters now. Llama-2 70B or Mistral 7B cut costs 50–80%. Solo developers and agencies: cloud simplicity (no ops burden) still wins. Pocket the price savings and redirect to product.
Startup Path: Stay Cloud Until Q3
Setup time to production on local hardware is 4–8 weeks (GPU procurement, Docker setup, inference optimization, testing). Cloud's advantage: no hidden ops burden. Move fast on product instead of infrastructure. Recommended stack: Claude 3.5 Sonnet for reasoning, GPT-5.5 for long-context, DeepSeek V4 for cost-sensitive tasks. Revisit ROI in Q3 2026 once Llama 3.1 stabilizes and local inference costs drop.
Scale-Up Path: Budget for Hardware Q2
Break-even crossed in April 2026 for workloads over 2.5M inferences/month. Typical payback period: 18–24 months on RTX 3090 hardware with hybrid cloud backup. Staffing: one senior engineer, 2–3 weeks to production (procurement, setup, integration, failover testing). Request CapEx approval this quarter. Budget $1500–$2500/GPU (hardware, setup, first-year ops). The RTX 3090 VRAM-per-dollar math guide has the detailed value analysis if you're evaluating hardware tiers beyond the 3090.