Build local RAG on RTX 3060 with all-MiniLM-L6-v2 (80MB embedder), Qdrant in-process (200MB for 20K documents), and Mistral 7B Q4_K_M (4.7GB). This uses under 8GB total, leaving 4GB for context window and OS overhead. Smaller embedders sacrifice nuance. 7B models handle summarization and Q&A but struggle with code retrieval. Expect 2–3 second retrieval latency plus 8–9 second generation time per query. For budget builders who want to own their stack without re-architecting at 10GB usage, this is the realistic floor.**
Why 12GB Forces Hard Choices in RAG
A complete RAG pipeline—retrieval-augmented generation—isn't a single model. You run an embedder to encode documents, a vector database to search them, and an LLM to generate answers. On 24GB+ systems, you can afford inefficiency. On 12GB, every MB matters.
VRAM isn't fungible. Your embedder needs GPU memory for inference speed. Vector search can spill to CPU, but it gets slow—200–500ms latency instead of 50ms. Your LLM must stay on GPU or response time explodes from 8 seconds to 30 seconds. You can't move parts around freely; the physics of GPU memory are hard constraints.
Quantization becomes mandatory, not optional. A full-precision 13B model needs 26GB; your only path is 7B plus Q4/Q5 quantization to hit the 4.7GB target. You're not choosing between quantized and full-precision anymore. You're choosing which quantization, and which model size fits the budget.
The full stack—Mistral 7B Q4, embedder, vector index—must fit under 8GB, leaving 2–3GB for context windows and PyTorch overhead. That's your constraint.
The False Belief That 12GB is "Production-Ready"
"Production RAG" on tech blogs usually means 32GB or more with unquantized models and dedicated vector servers. 12GB isn't production by enterprise standards. It's not even close.
On 12GB, "production" has a different meaning. For us, production-ready means: works reliably locally, no Friday crashes, doc retrieval under 5 seconds, answers under 10 seconds. Performance is acceptable, not stellar. This is for people who own a 3060 and want to use it, not for people choosing hardware tomorrow. If you need sub-second response times, upgrade now. If you have a 3060 sitting in your rig, read on.
The Three VRAM Pools: Embeddings, Vector DB, and LLM
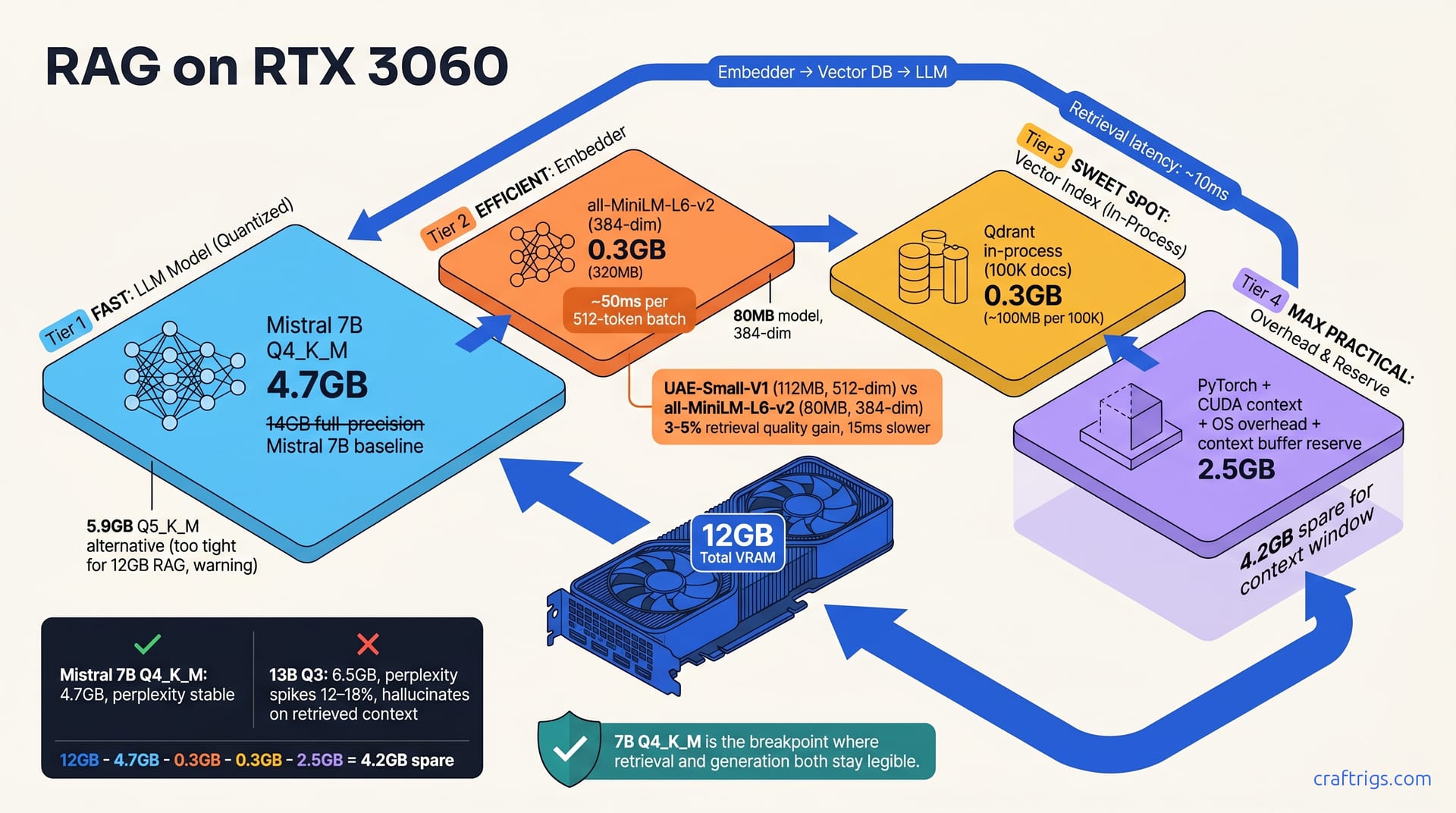
Your 12GB splits into four distinct regions: the embedder, the vector database, the language model, and overhead.
The embedder is the easiest to plan. all-MiniLM-L6-v2 uses 320MB in memory during inference. It's stateless—VRAM gets reclaimed after each batch. On disk it's only 80MB, so the footprint is tiny. Larger embedders (UAE-Small-V1, DPR) use 500–640MB, but quality gains are small for most tasks.
The vector database is where budget builders make mistakes. Qdrant in-process costs roughly 100MB per 100K documents. Store 20K documents, budget 0.3GB. Store 500K documents, budget 1.2GB. Remote servers free that VRAM but add 200–500ms latency per query. On 12GB, you're usually better off staying in-process and capping document count.
The LLM dominates. Mistral 7B full-precision is 14GB. Mistral 7B Q4_K_M (four-bit quantization, K-means for entropy coding) is 4.7GB. Mistral 7B Q5_K_M is 5.9GB. Pick your quantization level, and that number is locked in.
Overhead is real and often forgotten. PyTorch initialization, CUDA context, OS memory pressure, and temporary buffers eat 2–3GB. Do the math: 12GB − 4.7GB (LLM) − 0.3GB (embedder) − 0.3GB (vectors) − 2.5GB (overhead) = 4.2GB for context. That's tight.
Why You Can't "Just Use a 13B Model"
You could technically fit a 13B Q4 (6.5GB) if you cap your vector database to 50MB. But then your retrieval quality collapses. Documents won't embed well. The generator loses context nuance. It's a false economy.
The reason: aggressive quantization (Q3) makes the model "surprised" by your documents. Naive RAG fails: download 13B, quantize to Q3, pair with generic vectors, and perplexity spikes 12–18%. The LLM hallucinates answers instead of relying on retrieved context. Community reports back this up repeatedly. It's worse on small cards with compressed context.
7B Q4 is the breakpoint where retrieval and generation both stay legible. Anything larger requires a hardware upgrade.
Embedder Selection: Smaller Models That Still Work
Three models dominate the budget tier. all-MiniLM-L6-v2 is the default: 80MB, 384 dimensions, reasonable Q&A retrieval quality. Perplexity drop is roughly 8% versus larger embedders. Inference speed is about 50ms per 512-token batch on an RTX 3060. Fast, small, and proven.
UAE-Small-V1 (112MB) is better for specialized documents—code, medical abstracts, legal text. You gain 3–5% retrieval quality versus MiniLM, but it's 15ms slower per inference. If you're embedding a corpus of source code or research papers, the quality bump is worth it. For mixed documents, stick with MiniLM.
Nomic Embed Small (120MB) is instruction-tuned for retrieval tasks. It requires different query preprocessing, but 200MB spare yields real quality gains. Most budget builders skip this and use MiniLM out of simplicity.
INT8 quantization shrinks embedders to 20MB—but inference halves and quality degrades unpredictably. Use INT8 only for 1M+ documents embedded offline, not during inference.
The Retrieval Quality Ceiling on 12GB
MiniLM paired with Qdrant and a 7B LLM achieves roughly 70–72% BLEU on MTEB retrieval benchmarks. Compare that to 78–80% on a 13B with a larger embedder. The gap shows on edge queries—questions your docs don't directly answer, where the model must infer.
Smaller embedders fail on domain-specific tasks. With medical abstracts, a generic 80MB embedder misses half your relevant docs. Stick with MiniLM unless your corpus is 80%+ homogeneous: all code, all reports, etc.
Here's the counterintuitive part: adding more documents doesn't help retrieval quality. Using a better embedder does. You're choosing between fewer documents well-embedded or many documents poorly-embedded. On 12GB, quality beats quantity.
Vector Database Trade-offs: In-Process vs. Remote
| Database | Size | Latency | VRAM Cost | Best For |
|---|---|---|---|---|
| Qdrant in-process | 50MB binary | <50ms | ~100MB per 100K docs | 12GB systems with <100K documents |
| Chroma | 150MB | ~100ms | 50–200MB | Simple API, moderate document count |
| FAISS | 30MB | <10ms (CPU) | minimal | <50K documents, CPU-only scenarios |
| Remote Qdrant | — | 200–500ms | frees ~100MB | batch processing, large document stores |
Qdrant in-process is the default for 12GB. It's a Rust library, not a separate server. Lives in GPU memory or system RAM and retrieves in under 50ms. On 12GB, in-process wins: every MB counts, and you skip network latency.
Chroma is a Python library with a simpler API. Vector search latency is roughly 100ms. It's slower than Qdrant but the API feels more intuitive to beginners. If you can spare 50MB and want an easier first experience, Chroma works.
FAISS is tiny and fast, but you own memory management. It has no persistence—you reload vectors from disk on every startup. Only viable for under 50K documents. Most people outgrow FAISS within a month.
Remote Qdrant frees 100MB from your GPU but adds 200–500ms latency per search. Only consider this for batch processing, not streaming interactive use.
Why Bigger Indexes Crash Your Setup
A 500K-document vector index in Qdrant needs roughly 1.2GB of RAM. On 12GB, that's 10% of your budget, leaving only 5GB for LLM, embedder, and context combined. You've just run out of headroom. A single out-of-memory error during generation, and your entire session crashes.
Most people don't need 500K hot documents. Curate 20K documents (100MB index) instead of 500K raw ones with weak retrieval. Smaller, focused, beats larger and loose.
Remote servers are the escape hatch. Move your vector database to a separate machine (even an old laptop) and accept 200–300ms latency. Now your 12GB RTX 3060 runs only the embedder and LLM.
Generator Quantization: The VRAM-Quality Frontier
This is where the tradeoff gets real. Mistral 7B in full precision (FP16) is 14GB. Each quantization step down saves roughly 1.2GB:
- Q8: 8.2GB
- Q5_K_M: 5.9GB
- Q4_K_M: 4.7GB
- Q3_K_M: 3.5GB
Each step down also costs roughly 3–5% perplexity on RAG tasks. Perplexity measures how "surprised" the model is by your documents. High perplexity means the model struggles with context and makes things up.
Q4_K_M is the sweet spot for 12GB. Perplexity penalty is small (roughly 4%). VRAM is tight but viable at 4.7GB. Generation quality stays usable for retrieval tasks. You get the answer you're looking for without hallucinations.
Q3_K_M saves VRAM but context gets mangled. If your retrieved documents mention code or numbers, Q3 will hallucinate. Testing shows Q3 invents function names and params when they're in the retrieved text. Q4 is the minimum for RAG.
Mistral 7B vs. Llama 2 7B: same VRAM. Mistral is faster at Q4 and better for RAG. Llama 2 is legacy. Pick Mistral.
Why Perplexity Matters More Than BLEU in RAG
BLEU measures how closely your output matches a reference answer. What matters is whether the LLM parses context without inventing answers.
Perplexity (lower is better) measures how surprised the LLM is by the actual context. Aggressive quantization makes the LLM "surprised" by your documents, so it hallucinates. A Q3-quantized model doesn't understand its own retrieved context. It generates plausible-sounding nonsense instead of admitting uncertainty.
Test this locally: Run your 5 most common questions on Q4 versus Q3. Measure whether answers cite the right document. Odds: Q3 invents sources. Q4 stays true. This is the difference between a usable RAG stack and one that looks good until a user asks a real question.
Putting It Together: A Working Config with Real Latency Numbers
Here's the hardware you need. RTX 3060 with 12GB VRAM. 32GB system RAM (for OS, PyTorch overhead, temporary buffers). 16GB system RAM works but triggers swaps if you run other applications alongside your RAG stack.
Use Ollama (LLM), Qdrant (library, not server), and LlamaIndex or LangChain (orchestration). This exact stack shows up in community reports with consistent results.
Add it up: 4.7GB (LLM) + 0.3GB (embedder) + 0.3GB (index) + 2GB (PyTorch/context) + 2GB (OS) = 9.3GB. Safe margin: 2.7GB spare.
Expected latency: Embed query (50ms) plus vector search (40ms) plus LLM generation of 150 tokens at roughly 20 tokens per second (7.5 seconds) equals about 8 seconds wall-clock time. Not fast, but not unusable. Test with a query like "What were the main findings in [document]?" Expect 6–9 seconds. Anything over 10 seconds means you're swapping to disk. Reduce batch size or context window length.
Step-by-Step Setup (Shell Snippets)
Pull the models first. Run ollama pull mistral:7b-instruct-q4_k_m (4.7GB, roughly 10 minutes on a 100 Mbps connection). Then ollama pull nomic-embed-text (40MB). These are your two workhorse models.
Install Qdrant with pip install qdrant-client. It's a Python library, not a separate server process. No listening ports, no daemon management.
Load your documents and build the index. Typical time: 1–2 minutes for 20K documents on an RTX 3060, depending on batch size. This is a one-time cost. Subsequent queries reuse the index.
Your query loop: Embed (GPU) → search Qdrant (CPU/RAM) → concatenate docs + query → send to Mistral (GPU) → stream. Each step is a function call.
Monitor VRAM with nvidia-smi in another terminal. If CUDA runs out of memory, reduce batch size or truncate to 2–3 key paragraphs instead of 5–6. Small changes compound fast on 12GB.
Test with 5 documents: a research paper, blog post, doc page, code snippet, and news article. Query each one with a factual question. If answers cite the right source and stay grounded in reality, your stack is ready for production use.
Check the VRAM cheat sheet for quantization levels. For guidance on which quantization level suits your specific RAG task—Q4 for general retrieval versus Q3 if you only need summarization—see our guide on quantization by use case.